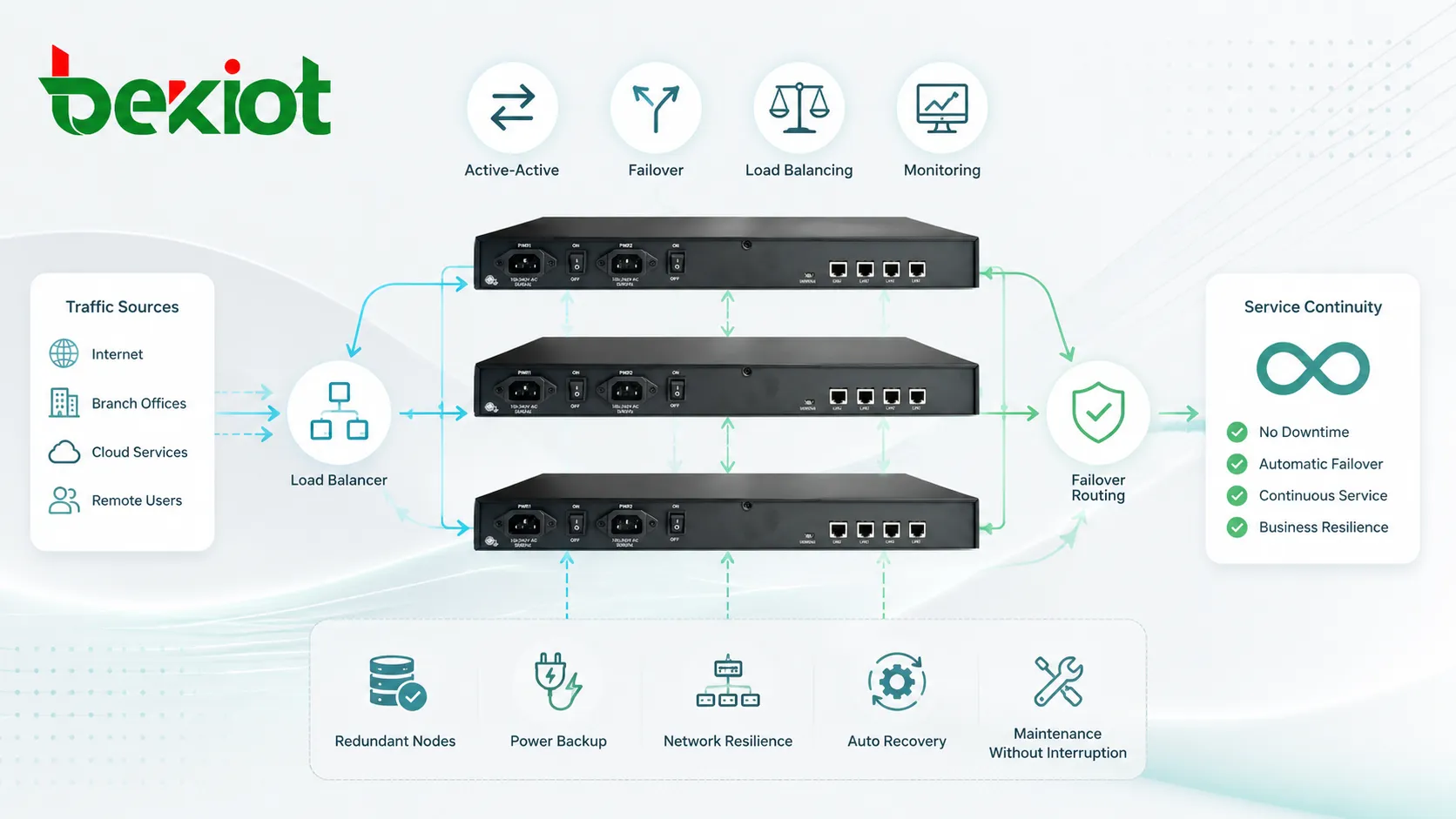
Кластер — это группа связанных компьютеров, серверов, шлюзов, устройств, приложений или сетевых узлов, которые работают вместе как единая согласованная система. Вместо зависимости от одного автономного блока кластерная архитектура распределяет нагрузки, повышает доступность, поддерживает переключение при отказе и позволяет сервисам продолжать работу, когда одна часть системы становится недоступной.
Термин «кластер» применяется во многих областях: ИТ-инфраструктуре, облачных вычислениях, базах данных, коммуникационных платформах, телефонии, радиосетях, промышленной автоматизации, системах хранения и периферийных вычислениях. Техническая реализация может различаться, но идея остается одной: несколько компонентов взаимодействуют, чтобы вся система стала надежнее, масштабируемее и проще в управлении.

Базовая идея группированных систем
В простой автономной системе один сервер или одно устройство самостоятельно обслуживает сервис. Если этот блок выходит из строя, сервис может остановиться. Если спрос пользователей растет, блок может быть перегружен. Если требуется обслуживание, избежать перерыва бывает трудно.
Кластерная система меняет эту модель. Несколько узлов соединяются сетью и управляются по общим правилам. Один узел может обрабатывать текущую нагрузку, другой ожидать как резервный, или все узлы могут вместе обрабатывать трафик. Конструкция зависит от цели системы.
Например, в бизнес-платформе связи несколько серверов могут совместно выполнять регистрацию пользователей, маршрутизацию вызовов, запись или обработку медиа. В среде Radio over IP несколько шлюзов могут соединять распределенные радиоканалы, диспетчерские центры и IP-сети, чтобы связь сохранялась между площадками.
Как группированные узлы работают вместе
Участие узлов
Узел — это участвующая единица внутри системы. Это может быть физический сервер, виртуальная машина, шлюз, контроллер, устройство хранения, коммуникационный терминал или программный сервис. Каждый узел имеет определенную роль и обменивается данными с другими узлами по сети.
Некоторые узлы выполняют одинаковые функции, а другие имеют специализированные задачи. В базе данных один узел может принимать записи, а другие реплицировать данные. В системе связи один узел может обрабатывать сигнализацию, а другой управлять медиа, записью или доступом к шлюзам.
Heartbeat и проверка состояния
Многие кластеры используют heartbeat-сигналы, чтобы проверять, живы ли узлы. Heartbeat — это регулярное сообщение состояния, которым обмениваются узлы или которое отправляется контроллеру управления. Если узел перестает отвечать, система считает, что он мог отказать.
Проверка состояния также может контролировать загрузку CPU, память, состояние сети, ответ приложения, процессы сервиса, место на диске, подключение шлюза или регистрацию устройств. Это помогает решить, должен ли узел продолжать обслуживать трафик или временно быть выведен из работы.
Распределение рабочей нагрузки
Некоторые кластерные системы распределяют работу между несколькими узлами. Это выполняется через балансировщики нагрузки, политики маршрутизации, общие очереди, распределенные базы данных или координацию на уровне приложения. Цель — не допустить перегрузки одного узла при простое других.
Распределение нагрузки повышает производительность и масштабируемость, но требует правильной обработки сессий, синхронизации данных, сетевой емкости и мониторинга. Неправильно спроектированный метод может создать неравномерную нагрузку или нестабильность сервиса.
Поведение при отказе
Переключение при отказе означает, что при сбое одного узла другой принимает его роль. В схеме активно-резервный резервный узел может быть неактивным до отказа активного. В схеме активно-активный несколько узлов уже обслуживают трафик и могут принять дополнительную нагрузку, когда один узел отключается.
Failover нужно тщательно тестировать. Резервный узел полезен только тогда, когда у него есть правильная конфигурация, актуальные данные, сетевой доступ, достаточная лицензия и состояние приложения, необходимые для продолжения сервиса.
Кластерная архитектура — это не просто добавление оборудования. Это координация узлов, чтобы отказы, рост и обслуживание проходили без лишних перерывов в сервисе.
Архитектурные модели, которые встречаются чаще всего
Схема активно-резервный
В схеме активно-резервный один узел предоставляет сервис, а другой ожидает как резервный. Если активный узел отказывает, резервный принимает работу. Такая модель распространена там, где согласованность и контролируемое переключение важнее одновременного использования всех узлов.
Преимущество — простота. Недостаток — резервные ресурсы могут быть недоиспользованы в обычном режиме. Однако для критичных систем такая свободная емкость часто оправдана, потому что повышает непрерывность.
Схема активно-активный
В схеме активно-активный несколько узлов одновременно предоставляют сервис. Трафик или задачи распределяются между ними. Если один узел отказывает, остальные продолжают обслуживать пользователей, хотя общая емкость может уменьшиться.
Эта модель улучшает использование ресурсов и масштабируемость. Она часто применяется в облачных платформах, веб-приложениях, системах связи, распределенных базах данных и многоузловых сервисных платформах.
Развертывание с балансировкой нагрузки
Развертывание с балансировкой использует фронтальный компонент, распределяющий трафик между несколькими backend-узлами. Балансировщик может использовать правила round-robin, наименьшего числа соединений, состояния здоровья, адреса источника, приоритета сервиса или географического положения.
Такой дизайн распространен для веб-сервисов, SIP-платформ, API, серверов приложений, медиасистем и корпоративных порталов. Сам балансировщик также должен быть резервирован, иначе он станет единой точкой отказа.
Распределенная edge-архитектура
Некоторые системы размещают узлы в разных местах, а не в одном дата-центре. Это характерно для связи филиалов, промышленных объектов, транспортных сетей, интеграции радио, IoT-платформ и систем общественной безопасности.
Распределенная edge-архитектура уменьшает зависимость от центральной площадки и может улучшить локальную реакцию. Но она требует надежной синхронизации, удаленного мониторинга, мер безопасности и понятных процедур обслуживания.
Почему организации выбирают такой подход
Более высокая доступность
Доступность — одна из основных причин использования группированных систем. Если автономный блок отказывает, сервис может остановиться. Если доступно несколько согласованных узлов, другой узел может продолжить сервис или принять затронутую нагрузку.
Это важно для платформ связи, аварийных служб, бизнес-приложений, финансовых систем, здравоохранения, промышленного управления и клиентских сервисов, где простой вызывает операционный или коммерческий ущерб.
Масштабируемость для роста
Когда спрос растет, организации могут нуждаться в большей вычислительной мощности, емкости вызовов, пропускной способности базы данных, хранилище, каналах шлюзов или сервисных точках. Кластер позволяет наращивать емкость добавлением узлов, а не заменой всей системы.
Масштабируемость особенно важна, когда трафик меняется со временем. Система может начаться с малого и расширяться по мере роста площадок, пользователей, каналов, сервисов или спроса клиентов.
Обслуживание с меньшими перерывами
Кластерные системы упрощают обслуживание. Администраторы могут вывести один узел из сервиса, обновить его, протестировать и вернуть в работу, пока другие узлы продолжают обрабатывать трафик.
Это не отменяет планирование. При обслуживании нужно учитывать совместимость, синхронизацию, сессии пользователей, поведение переключения при отказе и откат. Но такая архитектура дает больше гибкости, чем одноузловая система.
Лучшее использование ресурсов
В активно-активный или балансируемых системах несколько узлов делят работу. Это улучшает использование ресурсов, потому что емкость не ограничивается одной машиной или устройством.
Например, несколько серверов приложений могут обслуживать больше пользователей, чем один сервер. Несколько медиашлюзов поддерживают больше голосовых каналов. Несколько узлов хранения дают больше емкости и устойчивости.
Повышенная устойчивость сервиса
Устойчивость означает, что система может продолжать работу при нагрузке, частичном отказе, обслуживании или изменении трафика. Кластер помогает распределением ответственности и снижением зависимости от одного компонента.
Для критичных сред устойчивость должна также включать резервное питание, сетевое резервирование, географическое разделение, мониторинг, усиление безопасности и проверенные процедуры восстановления.
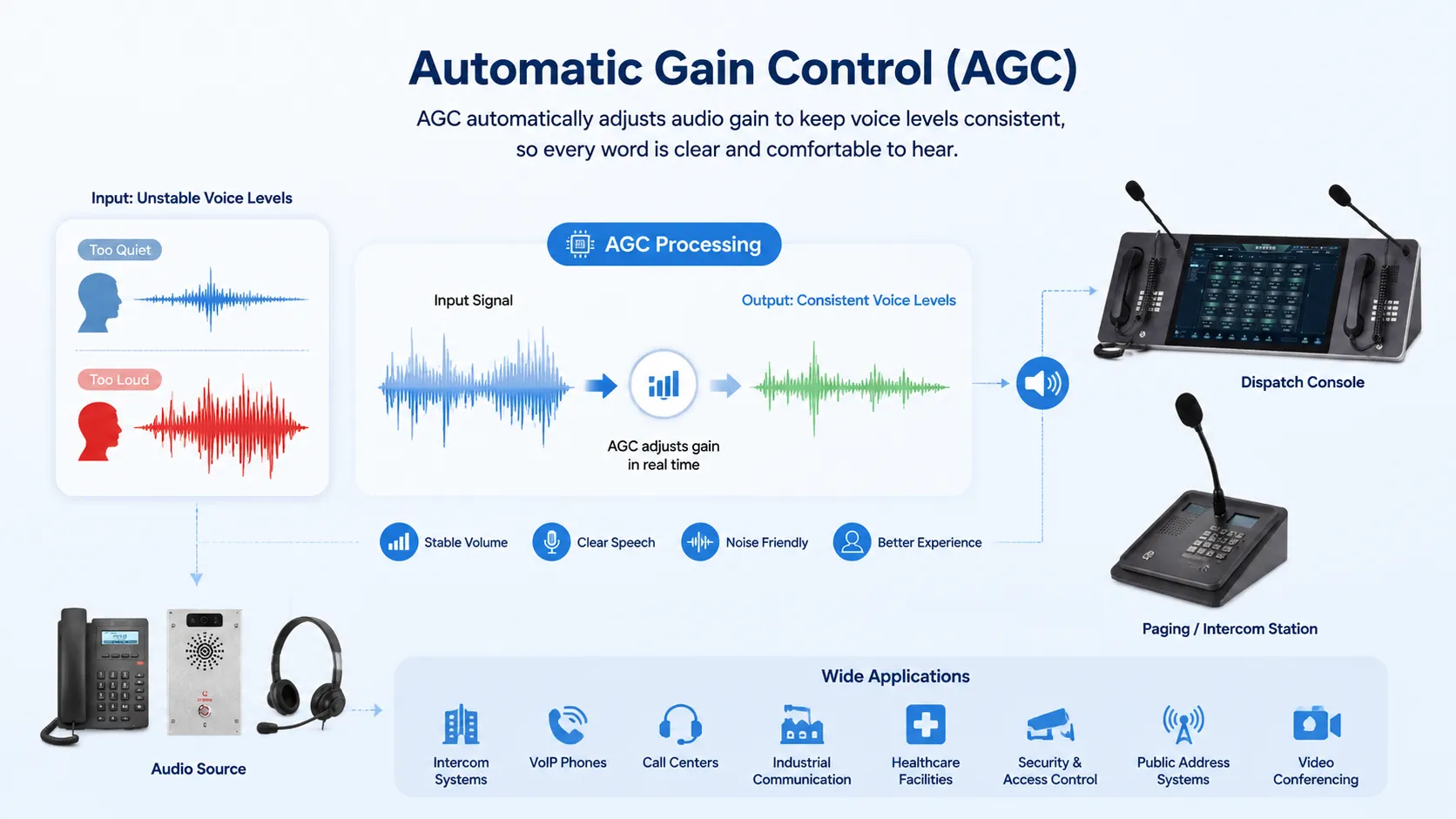
Важные технические компоненты
Общая конфигурация
Узлам нужна согласованная конфигурация, чтобы они вели себя предсказуемо. Это может включать сетевые настройки, данные пользователей, правила маршрутизации, сертификаты безопасности, параметры сервисов, лицензии и политики приложений.
Если конфигурации расходятся, переключение при отказе или распределение нагрузки становятся ненадежными. Централизованное управление конфигурацией или автоматическое развертывание снижает этот риск.
Синхронизация данных
Некоторым системам требуется синхронизация данных между узлами. Это могут быть пользовательские сессии, состояния вызовов, записи базы данных, статус очередей, регистрация устройств, данные голосовой почты, права доступа или журналы тревог.
Проектирование синхронизации критично. Если данные не актуальны, резервный узел может принять работу, но не предоставить ожидаемое состояние сервиса. Если синхронизация слишком тяжелая, она создает нагрузку на производительность.
Кворум и защита от split-brain
В некоторых кластерах кворум используется для определения, какие узлы имеют право принимать решения. Это помогает предотвращать split-brain, когда две части системы после разделения сети считают себя активными одновременно.
Split-brain опасен, потому что может привести к конфликтующим данным, двойному управлению сервисом или нестабильному переключение при отказе. Правильный кворум, fencing и сетевое резервирование уменьшают этот риск.
Мониторинг и оповещения
Мониторинг необходим, потому что кластеры могут скрывать частичные отказы. Сервис может выглядеть доступным, хотя один узел, канал, диск, шлюз или процесс уже отказал.
Администраторы должны контролировать здоровье узлов, распределение трафика, события переключение при отказе, состояние синхронизации, использование ресурсов, журналы ошибок и показатели уровня сервиса. Оповещения должны показывать не только факт сбоя, но и конкретный компонент, требующий внимания.
Контроль безопасности
В группированных системах обычно больше внутреннего обмена, чем в автономных системах. Узлы могут обмениваться состоянием, конфигурацией, данными, учетными данными или управляющими сообщениями. Эти каналы нужно защищать аутентификацией, шифрованием, сегментацией и контролем доступа.
Административный доступ также должен контролироваться. Если один узел скомпрометирован, злоумышленник не должен автоматически получить контроль над всей средой.
Сценарии связи и шлюзов
В коммуникационных сетях понятие кластера часто встречается в PBX-платформах, SIP-серверах, диспетчерских системах, шлюзах, Radio over IP сетях, платформах записи, контакт-центрах и системах аварийной связи. Этим сервисам нужна непрерывность, потому что сбои связи влияют на ежедневные операции, безопасность или обслуживание клиентов.
Для интеграции радио и диспетчеризации кластерный дизайн шлюзов помогает соединять несколько радиоканалов, IP-сетей и центров управления. Группа шлюзов может обеспечить расширение каналов, переключение при отказе, удаленный доступ и централизованное управление между площадками.
Например, кластерный шлюз серии BK-ROIP от Becke Telcom можно использовать в проектах, где радиосистемы должны подключаться к IP-диспетчерским платформам, многоузловым командным центрам или корпоративным сетям связи. В таких сценариях шлюзовой уровень связывает радиоголос, IP-передачу и операционные процессы диспетчеризации, сохраняя решение масштабируемым и удобным в управлении.
Применение в разных отраслях
Корпоративные ИТ-системы
Компании используют кластерные серверы для бизнес-приложений, баз данных, файловых сервисов, электронной почты, платформ идентификации и внутренних порталов. Эти системы должны оставаться доступными при отказах оборудования, обновлениях ПО или пиках трафика.
Для корпоративной ИТ главные цели — время безотказной работы, предсказуемая производительность, более простое обслуживание и непрерывность бизнеса. Дизайн должен соответствовать важности каждого приложения.
Облако и дата-центры
Облачные платформы сильно зависят от группированных ресурсов. Вычислительные узлы, узлы хранения, сетевые контроллеры и прикладные сервисы распределяются по инфраструктуре, чтобы нагрузки могли масштабироваться и восстанавливаться после отказов.
В дата-центрах такой дизайн поддерживает высокую доступность, пул ресурсов, виртуализацию, оркестрацию контейнеров и автоматическую миграцию нагрузок.
Телефония и унифицированные коммуникации
Голосовые платформы могут использовать группированные серверы для регистрации, маршрутизации вызовов, медиасервисов, голосовой почты, записи, очередей контакт-центра или управления SIP-транками. Это снижает риск, что отказ одного сервера прервет связь всех пользователей.
Для компаний с несколькими площадками распределенные коммуникационные узлы также повышают локальную живучесть. Филиал может продолжать внутреннюю связь, даже если соединение с центральной площадкой временно недоступно.
Промышленные и энергетические объекты
Заводы, коммунальные предприятия, нефтегазовые объекты, шахты, порты и электростанции могут использовать группированные системы для мониторинга, диспетчеризации, обработки тревог, интеграции радио, контроля доступа и связи диспетчерской.
В этих условиях время работы и устойчивость особенно важны. Систему следует планировать вместе с резервным питанием, защитой сети, условиями окружающей среды и процедурами обслуживания.
Общественная безопасность и экстренное реагирование
Организации экстренного реагирования могут использовать группированные серверы связи, диспетчерские платформы, радиошлюзы, системы записи и инструменты оповещения. Цель — сохранить связь при росте нагрузки или отказе части инфраструктуры.
Такие системы нужно тестировать в реалистичных условиях, включая переключение при отказе, резервное питание, высокий объем вызовов, координацию нескольких служб и сетевые сбои.

Планирование подходящей конфигурации
Сначала определить цель сервиса
Перед выбором кластерной архитектуры организация должна определить цель сервиса. Это может быть высокая доступность, распределение нагрузки, географическое резервирование, гибкость обслуживания, расширение каналов, аварийное восстановление или интеграция нескольких площадок.
Каждая цель ведет к другой архитектуре. Система, созданная в первую очередь для переключение при отказе, может отличаться от системы, созданной для масштабирования производительности.
Определить точки отказа
Кластер может отказать, если другие компоненты не резервированы. Питание, коммутаторы, маршрутизаторы, хранилище, межсетевые экраны, балансировщики, лицензии, базы данных и платформы управления могут стать едиными точками отказа.
Планирование должно выходить за рамки самих узлов. Нужно анализировать полный путь предоставления сервиса.
Проверить совместимость приложения
Не каждое приложение или устройство рассчитано на кластеризацию. Некоторым системам нужны специальные лицензии, поддержка базы данных, логика синхронизации, общее хранилище или архитектура поставщика.
Совместимость нужно подтвердить до внедрения. Дизайн, хорошо выглядящий на бумаге, может не работать, если приложение не поддерживает активно-активный режим или синхронизацию состояния.
Протестировать восстановление
Failover должен быть проверен до промышленной эксплуатации. Тесты должны включать отказ узла, разрыв сети, перезапуск сервиса, задержку базы данных, потерю питания, режим обслуживания и возврат к нормальной работе.
Тесты восстановления выявляют скрытые проблемы: медленное переключение, неполную синхронизацию, неверную маршрутизацию или потерю пользовательских сессий.
Распространенные сложности
Одна из распространенных сложностей — комплексность. Больше узлов, каналов и правил синхронизации означает больше объектов для настройки и мониторинга. Плохо управляемый кластер может быть сложнее в диагностике, чем простая автономная система.
Еще одна сложность — ложная уверенность. Некоторые организации считают, что добавление узлов автоматически создает высокую доступность. На практике полный дизайн должен включать резервирование, мониторинг, логику переключение при отказе, проверенное восстановление и квалифицированное обслуживание.
Стоимость также важна. Дополнительные узлы, лицензии, хранилище, коммутаторы, шлюзы, программные модули и поддержка могут увеличить стоимость проекта. Инвестиции должны соответствовать бизнес-риску простоя или ограниченной емкости.
Кластерная система должна проектироваться вокруг реальных требований сервиса, а не вокруг идеи, что больше узлов автоматически означает лучшую надежность.
Обслуживание и эксплуатация
Регулярное обслуживание должно включать проверки состояния узлов, ревизию конфигурации, проверку резервных копий, тесты переключения при отказе, анализ журналов, мониторинг производительности и обновления безопасности. Кластер, который никогда не тестируется, может отказать в самый нужный момент.
Администраторы также должны следить за дрейфом конфигурации. Когда один узел обновлен вручную, а другой нет, поведение может стать непоследовательным. Автоматизация конфигурации и документированный контроль изменений снижают риск.
Емкость нужно пересматривать со временем. Если один узел отказывает, оставшиеся узлы должны иметь достаточно ресурсов для критичных нагрузок. Иначе переключение при отказе сохранит сервис онлайн, но с неприемлемой производительностью.
Как выбрать подходящее решение
Правильное решение зависит от типа нагрузки, важности сервиса, масштаба пользователей, распределения площадок, требований восстановления и бюджета. Небольшому офисному приложению может хватить базового резервного копирования, а операторской платформе связи может потребоваться активно-активный резервирование на нескольких площадках.
Для коммуникационных проектов нужно учитывать емкость вызовов, емкость каналов, SIP-совместимость, обработку медиа, интеграцию радио, резервирование шлюзов, централизованное управление, журналирование и поведение переключения при отказе. Если решение соединяет радио, IP-диспетчеризацию и корпоративную связь, особенно важны масштабируемость шлюза и устойчивость на уровне площадки.
Организациям также следует учитывать долгосрочное обслуживание. Решение должно быть понятным, документированным, мониторируемым и поддерживаемым командой, отвечающей за ежедневную эксплуатацию.
FAQ
Может ли малый бизнес использовать кластерные системы?
Да. Малому бизнесу может не требоваться сложная многоузловая платформа, но он может использовать простые решения высокой доступности, такие как резервные межсетевые экраны, резервные серверы, реплицированное хранилище или облачные управляемые сервисы.
Всегда ли кластеризация требует одинакового оборудования?
Не всегда. Некоторые системы требуют одинакового оборудования или версий ПО, другие допускают смешанные узлы. Но различия в мощности или версиях могут влиять на производительность, переключение при отказе и поддержку.
Чем резервирование отличается от кластеризации?
Резервирование означает наличие запасных компонентов. Кластеризация — это согласованный дизайн, где несколько компонентов работают вместе по общей логике. Кластер обычно включает резервирование, но одно резервирование не всегда означает кластерную систему.
Почему переключение при отказе иногда занимает больше времени, чем ожидалось?
Failover может задерживаться из-за таймеров health-check, синхронизации базы данных, запуска сервисов, сходимости маршрутизации, DNS-кэша, восстановления сессий или ручного подтверждения. Эти факторы нужно проверять до запуска в производство.
Что нужно задокументировать после внедрения?
Документация должна включать роли узлов, IP-адреса, зависимости сервисов, правила переключение при отказе, учетные записи управления, пороги мониторинга, процедуры резервного копирования, окна обслуживания, шаги восстановления и ответственных контактов.