Обновление системы не должно начинаться с самого установочного пакета.Оно должно начинаться с простого эксплуатационного вопроса: что должно оставаться стабильным во время изменения? Новая версия может принести исправления безопасности, лучшую производительность, новые функции или более долгий срок поддержки, но также может вызвать проблемы совместимости, изменения конфигурации, перерыв в сервисе и нагрузку на восстановление.
Поэтому грамотное управление обновлением — это не просто нажать «обновить» в подходящее время. Это контролируемое изменение, которое защищает сервисы, пользователей, данные и непрерывность бизнеса.
Начинайте с причины изменения
Первое правило — подтвердить, зачем нужно обновление. Некоторые обновления срочные, потому что устраняют уязвимости, серьезные ошибки, требования соответствия или риск окончания поддержки. Другие плановые: они улучшают производительность, добавляют функции, поддерживают новое оборудование или готовят будущую архитектуру. Необязательные обновления лучше откладывать до появления достаточного времени для тестирования.
Без четкой причины решение быстро становится реактивным. Команда может обновиться только потому, что вышла новая версия, поставщик ее рекомендует или другой отдел уже сделал это. Так возникает ненужный риск. Стабильную систему не стоит менять без понятной пользы, которая оправдывает возможное нарушение работы.
Цель обновления нужно записывать практически: «закрыть уязвимость аутентификации», «поддержать новую версию базы данных», «увеличить емкость обработки вызовов», «заменить неподдерживаемую ОС» или «включить интеграцию с новой платформой». Ясная цель помогает определить объем тестов и критерии приемки.
Когда причина ясна, команда может определить срочность. Критическое обновление безопасности может требовать короткого цикла согласования, функциональное — планироваться в низкорисковое окно обслуживания, а архитектурное — выполняться поэтапно. Разные причины требуют разного уровня контроля.
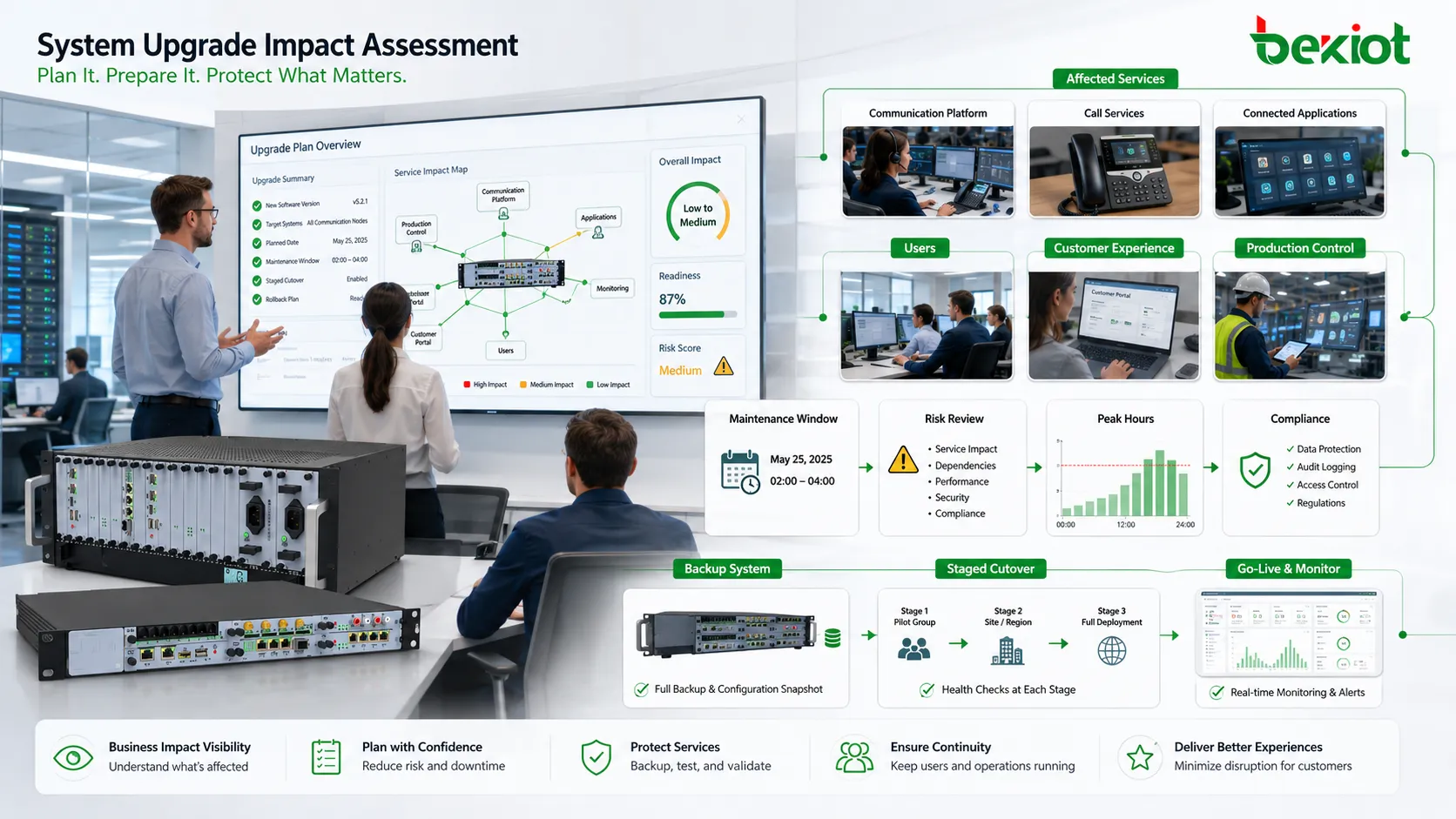
Оцените влияние на бизнес до технических действий
Любое обновление влияет не только на техническую систему. Оно может затронуть пользователей, окна обслуживания, связанные приложения, отчеты, права доступа, устройства, клиентский опыт, производственные процессы и команды поддержки. До технических действий нужно определить, какие бизнес-процессы зависят от системы.
Это особенно важно для непрерывно работающих систем: коммуникационных платформ, баз данных, промышленных систем, клиентских порталов, платежных систем, платформ мониторинга и внутренних операционных инструментов. Даже короткий перерыв может привести к пропущенным звонкам, сбоям транзакций, задержке производства, неполным записям или жалобам.
Анализ влияния должен учитывать пиковые периоды, критические группы пользователей, внешних клиентов, внутренние подразделения, SLA, а также юридические и нормативные требования. Если система поддерживает аварийное реагирование, управление производством, охранный мониторинг или общественный сервис, план должен быть строже, чем для обычных офисных инструментов.
Результат анализа должен определять расписание. Одни обновления можно выполнить в обычное окно обслуживания, другие требуют ночи или выходных, третьи — временных резервных систем, уведомлений пользователей или поэтапного переключения. Технически простое обновление может быть рискованным при неправильном времени.
Сначала создайте точный инвентарный список
Систему нельзя безопасно обновить, если команда не знает, что к ней подключено. Инвентарь должен включать серверы, операционные системы, базы данных, middleware, приложения, конечные устройства, сетевое оборудование, хранилища, лицензии, сертификаты, API, сторонние интеграции, инструменты резервного копирования, мониторинг и способы доступа пользователей.
Такой список раскрывает скрытые зависимости. Отчетный инструмент может зависеть от версии базы данных, старый клиент может не поддерживать новый протокол, устройство может отказать после смены прошивки, а система безопасности может использовать устаревший API. Если это обнаружится после внедрения, давление на откат резко возрастет.
Инвентаризация конфигурации не менее важна. Параметры системы, правила маршрутизации, права пользователей, ключи интеграции, задания по расписанию, сервисные учетные записи, правила межсетевого экрана, сертификаты и пользовательские скрипты должны быть зафиксированы до обновления. Часто сбои возникают не из-за новой версии, а из-за потерянных или перезаписанных настроек.
В крупных средах нужно также видеть различия версий между площадками или узлами. Филиал может иметь другой уровень патчей, сервер — специальный модуль, модель устройства — особый путь прошивки. Эти различия влияют на порядок обновления и план тестирования.
Подтверждайте совместимость, а не предполагайте ее
Совместимость — один из самых частых рисков обновления. Новая версия может требовать более свежую базу данных, другую библиотеку времени выполнения, обновленный браузер, измененный драйвер, пересмотренный API или новый метод аутентификации. Если связанные системы несовместимы, установка может пройти успешно, но эксплуатация будет нарушена.
Проверки должны охватывать оборудование, ОС, базу данных, версию приложения, протоколы, интерфейсы, браузеры, мобильные клиенты, конечные устройства, драйверы, плагины, сертификаты и сторонние сервисы. Команда не должна полагаться только на общие примечания к выпуску; реальные условия проекта нужно сравнивать с требованиями поставщика и локальной конфигурацией.
Обратная совместимость тоже важна. Если старые клиенты, устройства или интеграции должны работать после обновления, их нужно проверять напрямую. Одни системы временно допускают смешанные версии, другие требуют обновить все компоненты сразу. Ошибка в оценке может привести к частичному отказу сервиса.
Если совместимость неясна, нужен пилотный контур. На нем можно проверить представительные устройства, роли пользователей, потоки данных и вызовы интерфейсов до изменения рабочей среды. Это снижает риск обнаружить крупные конфликты уже в окне обслуживания.
| Область обновления | Ключевое правило | Причина проверки |
|---|---|---|
| Версия приложения | Проверить примечания к выпуску и изменения зависимостей | Предотвращает потерю функций и конфликты интерфейсов |
| База данных | Проверить схему, драйвер и требования миграции | Защищает доступ к данным и стабильность транзакций |
| Операционная система | Подтвердить поддержку среды выполнения, сервисов и политик безопасности | Предотвращает проблемы запуска и прав |
| Сеть и безопасность | Проверить межсетевой экран, сертификаты, DNS и правила доступа | Предотвращает сбои подключения после переключения |
| Конечные устройства и клиенты | Проверить представительные устройства и версии | Снижает жалобы на совместимость на местах |
Защитите данные до изменения среды
Защита данных — обязательное правило. Перед обновлением нужно подтвердить наличие резервной копии, ее целостность, способ восстановления, место хранения, политику хранения и время восстановления. Резервная копия, которая никогда не проверялась, — это предположение, а не план восстановления.
Для баз данных и приложений резервную копию нужно делать в правильный момент. Если данные продолжают меняться во время обновления, нужно решить, остановить ли запись, использовать журналы транзакций, сделать снимок или подготовить восстановление на основе репликации. Метод зависит от архитектуры и допустимого простоя.
Конфигурационные копии нельзя игнорировать. Настройки приложений, служебные файлы, таблицы маршрутизации, плановые задания, роли пользователей, сертификаты, ключи и пользовательские шаблоны могут быть так же важны, как бизнес-данные. После сбоя их ручное восстановление может занять больше времени, чем возврат ПО.
Скрипты миграции данных также нужно внимательно проверять. Некоторые обновления меняют схему, индексы, кодировку, длину полей или структуру данных. Такие изменения трудно откатить. Команда должна понимать, обратима ли миграция, нужен ли полный restore и сколько займет восстановление.
Используйте тестовую среду, близкую к реальности
Тестирование ценно только тогда, когда среда похожа на рабочую среду в важных аспектах. Маленькая пустая тестовая система может показать, что установщик запускается, но не выявить проблемы производительности, миграции, интеграции, прав доступа или совместимости устройств.
Тестовая среда должна включать представительные данные, роли пользователей, подключенные сервисы, параметры, интерфейсные вызовы и типовые нагрузки. Она не обязана идеально копировать рабочую среду, но должна содержать достаточно реальности, чтобы выявить основные риски.
Тест-кейсы должны повторять реальные процессы. Пользователи должны входить в систему, создавать записи, формировать отчеты, выполнять транзакции, запускать тревоги, вызывать API, создавать файлы, пользоваться мобильными клиентами или подключенными устройствами. Успешный запуск службы не равен готовности сервиса.
При необходимости выполняется нагрузочное тестирование. Новая версия может работать с одним пользователем, но замедляться под реальной нагрузкой. Нужно наблюдать миграцию базы, кэш, память, CPU, дисковый I/O, сетевую задержку и фоновые задания. Оценивать нужно эксплуатационное поведение, а не только завершение установки.

Подготовьте откат до внедрения
Обновление не следует продолжать без плана отката. Откат — это возврат системы к предыдущему рабочему состоянию, если обновление не удалось или вызвало неприемлемые проблемы. Недостаточно сказать «при необходимости восстановим резервную копию»; нужно знать точный порядок действий.
План отката должен определять, кто принимает решение, какие условия его запускают, какие файлы или базы восстанавливаются, сколько времени займет восстановление, какие данные могут быть потеряны и как уведомляются пользователи. Нужно также понять, возможен ли откат после миграции данных или остается только исправление вперед.
Некоторые обновления легко отменить. Другие меняют структуру базы, методы шифрования, прошивки или форматы конфигурации так, что возврат сложен. В таких случаях нужны дополнительная осторожность, поэтапное внедрение, сине-зеленая архитектура, резервные узлы или параллельная работа.
Откат по возможности нужно тестировать. План без тренировки может отказать в аварийной ситуации. Даже частичная репетиция выявляет отсутствующие права, медленное восстановление, неполные копии или неясные зоны ответственности.
Контролируйте окно обслуживания
Окно обслуживания — плановый период для обновления. Его выбирают с учетом влияния на пользователей, нагрузки системы, доступности специалистов, поддержки поставщика, завершения резервного копирования и времени отката. Частая ошибка — выделить время на установку, но не на диагностику или откат.
Окно должно включать подготовку, финальную копию, выполнение обновления, проверку, возможное исправление, время решения об откате, сам откат и коммуникацию с пользователями. Если установка занимает час, а откат три часа, график должен учитывать эту реальность.
Перед обновлением может потребоваться заморозка изменений. Другие команды не должны в тот же период вносить несвязанные изменения конфигурации, сети, базы данных или правил доступа. Когда изменения накладываются друг на друга, поиск причины становится намного сложнее.
Доступность поддержки также важна. Ключевые технические специалисты, владельцы приложений, сетевые инженеры, администраторы баз данных, службы безопасности и поддержка поставщика должны быть на связи. Нельзя планировать обновление, если единственный эксперт по критической зависимости недоступен.
Общайтесь с пользователями до и после изменения
Коммуникация с пользователями предотвращает путаницу. До обновления затронутые пользователи должны знать ожидаемое время, влияние на сервис, временные ограничения, канал связи и действия, которых следует избегать в окне обслуживания. Для публичных систем может потребоваться уведомление клиентов.
Сообщение должно быть конкретным, но не перегруженным техническими деталями. Пользователям нужно знать, будет ли система недоступна, нужно ли остановить ввод данных, обновлять ли мобильный клиент, изменятся ли пароли или способ входа и когда сервис должен вернуться.
После обновления пользователи должны получить подтверждение доступности системы. Если функции изменились, нужны краткие примечания к выпуску или инструкции. Если остаются проблемы, команда должна описать известные ограничения и ожидаемые шаги решения.
Хорошая коммуникация сокращает лишние обращения в поддержку. Многие жалобы после обновления вызваны не технической неисправностью, а неожиданными изменениями интерфейса, запросами входа, истекшими сессиями или временными колебаниями производительности.
Проверяйте результат приемочными проверками
Обновление не завершено, когда завершается установщик. Оно завершено только после прохождения приемочных проверок. Эти проверки нужно определить до начала, чтобы команда понимала, что значит «успешно».
Приемка может включать запуск сервисов, вход в систему, выполнение ключевых процессов, чтение и запись данных, отчеты, вызовы интерфейсов, подключение устройств, плановые задания, проверку прав, работу резервного копирования, состояние мониторинга и подтверждение пользователей. Точный список зависит от функции системы.
Сначала проверяются критические функции. Если система поддерживает транзакции — тестируйте транзакции; если связь — маршруты вызовов или потоки сообщений; если мониторинг — прием тревог и обновление панелей; если базы данных — доступ приложения и запросы. Не стоит тратить раннюю проверку на второстепенные функции.
Приемка также должна включать просмотр журналов. Ошибки, предупреждения, неудачные задания, ошибки аутентификации, сообщения миграции и сбои интеграции могут показать проблему раньше пользователей. Чистый экран не всегда означает чистое обновление.

Отслеживайте состояние системы после выпуска
Первые часы и дни после обновления важны. Некоторые проблемы проявляются только под реальным трафиком, плановыми заданиями, пиковой нагрузкой или конкретным поведением пользователей. Пост-обновленный мониторинг должен быть активнее обычного, особенно для критических систем.
Мониторинг должен включать CPU, память, диск, производительность базы данных, сетевой трафик, состояние сервисов, журналы ошибок, пользовательские сессии, успешность транзакций, ответ API, длину очередей и рост хранилища. Также нужно отслеживать отзывы пользователей, потому что часть проблем видна им раньше, чем на панелях.
Базовые показатели производительности полезны. Если известны нормальное время ответа, потребление ресурсов и уровень ошибок до обновления, новую версию можно сравнить объективнее. Без базовой линии трудно понять, новое ли замедление или историческое.
Длительность мониторинга должна быть определена. Малой внутренней системе может хватить нескольких часов, критической — нескольких дней или полного бизнес-цикла. Обновление нельзя закрывать, пока система не докажет стабильность в обычных условиях.
Документируйте все изменения
Документация является частью обновления, а не необязательной административной задачей. Команда должна записать установленную версию, изменения конфигурации, выполненные резервные копии, возникшие проблемы, способы решения, согласующих лиц и оставшиеся действия.
Записи версий особенно важны. Будущая диагностика зависит от понимания текущей версии системы, базы данных, прошивки, драйвера или патча. Без документации следующая команда будет заново выяснять состояние среды.
Известные проблемы нужно фиксировать. Если функция требует дальнейшей настройки, интеграция ждет подтверждения поставщика или группе пользователей нужно обучение, это не должно оставаться в неформальном чате. Это часть записи обновления.
Хорошая документация улучшает следующее обновление. Команда может понять, что прошло хорошо, что заняло больше времени, какие риски были пропущены и какие шаги нужно улучшить. Каждое обновление должно делать организацию готовее к следующему.
Итоги
Главное правило системного обновления — контролируемое изменение. Успешное обновление защищает данные, проверяет совместимость, ограничивает простой, готовит откат, информирует пользователей и подтверждает поведение сервиса после выпуска. Сам пакет обновления — только часть процесса.
Для критичных бизнес-сред безопаснее рассматривать обновление как полный эксплуатационный процесс: оценить влияние, реалистично протестировать, аккуратно запланировать, выполнить с ясной ответственностью, проверить результат и мониторить после выпуска. Тогда обновления улучшают систему, а не создают предотвратимые сбои.
FAQ
Нужно ли обновлять каждую систему сразу после выхода новой версии?
Нет. Срочные исправления безопасности могут требовать быстрого действия, но функциональные и крупные версии нужно сначала оценить. До внедрения проверяют совместимость, влияние на бизнес, готовность тестов и варианты отката.
Какая подготовка перед обновлением самая важная?
Самое важное — подтвердить восстанавливаемость. Это проверенные резервные копии, записи конфигурации, процедуры отката и ясные правила решения. Без уверенности в восстановлении даже простое обновление может стать рискованным.
Почему обновления могут не пройти даже после тестов?
Тесты могут не охватить реальные условия рабочей среды: высокий трафик, необычные данные, старые клиенты, сторонние интеграции, плановые задания, различия прав или сетевые ограничения. Тестовая среда должна отражать ключевые зависимости рабочей среды.
Как долго должен продолжаться мониторинг после обновления?
Это зависит от важности системы и цикла использования. Малому внутреннему инструменту может хватить короткого контроля, а критическому сервису нужны пики нагрузки, плановые задания и полный бизнес-цикл.
Что должно входить в запись обновления?
Нужно включить старую и новую версии, время обновления, ответственных, детали резервного копирования, измененную конфигурацию, результаты тестов, найденные проблемы, статус отката, уведомления пользователей и последующие действия.