Технология аварийного восстановления объединяет системы резервного копирования, реплицированную инфраструктуру, резервные среды, процедуры восстановления, инструменты мониторинга и операционные планы, которые используются для возврата бизнес-сервисов после серьезного сбоя. Она помогает организациям восстанавливаться после отказа оборудования, повреждения данных, атак программ-вымогателей, пожара, наводнения, отключения электропитания, сбоя облачного сервиса, отказа сети, случайного удаления или нарушения работы целой площадки.
Ее цель не сводится к тому, чтобы просто «сохранить данные». Полноценный проект восстановления должен вернуть приложения, базы данных, серверы, системы идентификации, коммуникационные платформы, сетевые маршруты, доступ пользователей, политики безопасности и рабочие процессы в пригодное для использования состояние. Поэтому аварийное восстановление является одновременно технической архитектурой и дисциплиной обеспечения непрерывности бизнеса.
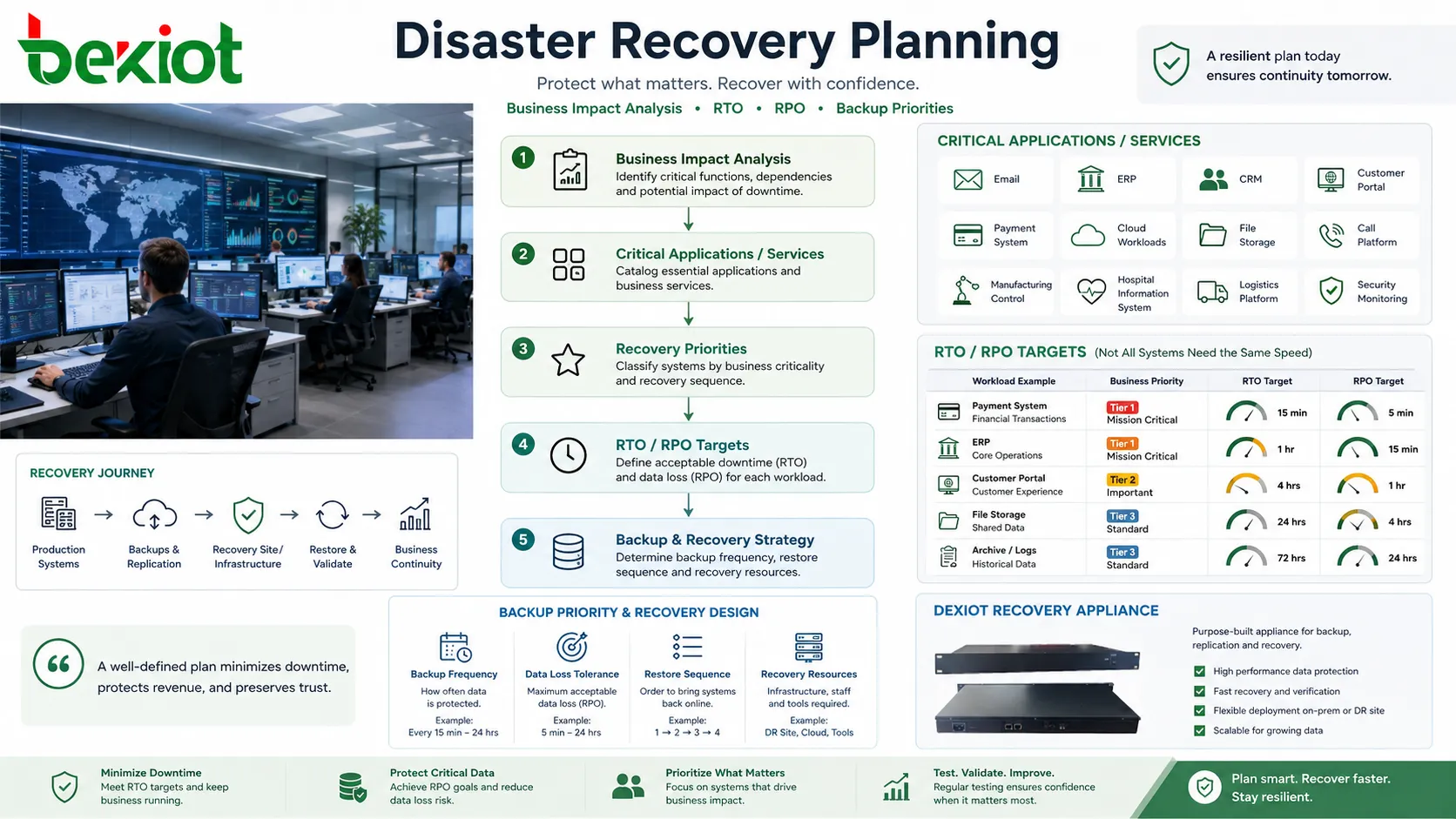
Начинать с влияния на бизнес
Надежный план восстановления начинается с понимания того, какие сервисы действительно критичны. Электронная почта, ERP, CRM, клиентские порталы, платежные системы, облачные рабочие нагрузки, файловое хранилище, платформы звонков, системы управления производством, больничные информационные системы, логистические платформы и мониторинг безопасности могут иметь совершенно разные приоритеты восстановления.
Не каждой системе нужна одинаковая скорость восстановления. Публичная транзакционная система может требовать возврата за считанные минуты, а архивная система может допускать несколько часов простоя. Если считать все нагрузки одинаково срочными, растут стоимость и сложность. Если недооценивать важные нагрузки, увеличивается бизнес-риск.
При планировании часто используют два понятия. Recovery Time Objective, или RTO, определяет, как быстро должен быть восстановлен сервис. Recovery Point Objective, или RPO, определяет допустимую потерю данных, измеряемую временем. Например, RPO в 15 минут означает, что организация должна иметь возможность восстановить данные к точке не более чем за 15 минут до отказа.
Ключевые технологические уровни
Уровень защиты данных
Первый технический уровень защищает данные. Он может включать полное резервное копирование, инкрементное копирование, дифференциальное копирование, снимки, непрерывную защиту данных, неизменяемые резервные копии, дампы баз данных, версионирование объектного хранилища и репликацию на удаленную площадку.
Хорошая защита данных должна включать несколько точек восстановления. Если последняя резервная копия содержит поврежденные или зашифрованные данные, организации может потребоваться восстановление из более ранней чистой версии. Это особенно важно при атаках программ-вымогателей или случайном удалении.
Уровень восстановления вычислительных ресурсов
Одних данных недостаточно. Приложениям нужны серверы, виртуальные машины, контейнеры, операционные системы, среды выполнения, промежуточное ПО, лицензии и конфигурационные файлы. Вычислительный уровень определяет, где будут запускаться рабочие нагрузки после отказа основной среды.
Вычислительные ресурсы восстановления могут быть подготовлены в другом дата-центре, облачном регионе, резервном кластере, виртуализированной платформе или управляемой среде восстановления. Чем лучше подготовлена среда, тем быстрее может пройти восстановление.
Уровень сетевой непрерывности
После восстановления систем пользователи и другие системы должны иметь возможность к ним обращаться. Для этого нужны сетевые маршруты, обновления DNS, доступ VPN, правила межсетевых экранов, балансировщики нагрузки, планы IP-адресации, сертификаты, политики NAT и безопасный удаленный доступ.
Сетевое восстановление часто недооценивают. Приложение может уже работать на резервной площадке, но пользователи все равно не смогут получить к нему доступ, если записи DNS, таблицы маршрутизации, пути идентификации или правила межсетевого экрана не обновлены.
Уровень идентификации и доступа
Пользователям, администраторам, приложениям и сервисным учетным записям после сбоя нужны аутентификация и авторизация. Если службы идентификации недоступны, многие восстановленные приложения все равно останутся непригодными к использованию.
Каталожные службы, системы MFA, центры сертификации, инструменты привилегированного доступа, хранилища паролей и платформы SSO должны входить в планирование восстановления. Резервная площадка без работающего контроля идентификации может стать проблемой безопасности и эксплуатации.
Уровень операционной оркестрации
Восстановление требует действий в правильном порядке. Базы данных могут запускаться раньше приложений. Сетевые правила могут изменяться до подключения пользователей. Хранилище должно быть смонтировано до запуска сервисов. Мониторинг должен подтвердить, что восстановленная система исправна.
Инструменты оркестрации автоматизируют эти шаги. Они могут запускать нагрузки, применять скрипты, обновлять конфигурации, инициировать переключение, проверять зависимости и формировать отчеты о восстановлении. Автоматизация снижает человеческие ошибки во время напряженных инцидентов.
Как обычно проходит процесс восстановления
Обнаружение и подтверждение инцидента
Процесс начинается, когда инструменты мониторинга, пользователи, администраторы или системы безопасности обнаруживают аномальное событие. Это может быть отказ сервера, ошибка базы данных, сбой хранилища, сигнал о ransomware, сбой приложения, потеря питания площадки или проблема облачного региона.
Команда должна подтвердить, требуется ли полное восстановление, частичная реставрация или локальный ремонт. Не каждый сбой должен запускать полное переключение. Небольшую проблему приложения можно устранить быстрее, чем активировать вторичную среду.
Решение и активация
После подтверждения инцидента уполномоченные сотрудники решают, активировать ли план восстановления. Решение должно основываться на влиянии на бизнес, ожидаемой длительности простоя, риске безопасности, влиянии на клиентов, целостности данных и возможности быстро восстановить основную площадку.
Четкие полномочия принятия решений очень важны. Если никто не знает, кто может утвердить переключение, организация может потерять ценное время во время серьезного инцидента.
Восстановление данных или переключение репликации
Среде восстановления нужны пригодные данные. Если проект использует резервные копии, команда восстанавливает данные из выбранной точки восстановления. Если используется репликация, резервная копия может быть переведена в активное использование.
Выбор данных критичен. Восстановление самой новой копии не всегда верно, если повреждение или вредоносное ПО уже попали в нее. Командам может понадобиться найти последнюю чистую точку восстановления.
Перезапуск сервисов и порядок зависимостей
Приложения перезапускаются в соответствии с зависимостями. Базы данных, хранилище, службы идентификации, промежуточное ПО, серверы приложений, веб-фронтенды, API и интеграции могут требовать заданной последовательности.
Игнорирование порядка зависимостей может создать запутанные сбои. Восстановленное приложение может казаться неисправным просто потому, что база данных, сервер лицензий, очередь сообщений или запись DNS еще не готовы.
Проверка перед передачей пользователям
Перед возвращением пользователей к сервису команда должна проверить, что восстановленная среда работает. Это может включать тесты входа, проверки согласованности данных, транзакционные тесты, тесты звонков, проверки API, формирование отчетов, обзор безопасности и подтверждение мониторинга.
Только после проверки среду восстановления следует считать активной производственной службой. Быстрое, но непроверенное восстановление может привести к потере данных, пробелам безопасности или путанице у пользователей.
Аварийное восстановление работает лучше всего, когда его рассматривают не как одну задачу резервного копирования, а как согласованный перезапуск данных, систем, сетей, идентичностей, пользователей и бизнес-процессов.
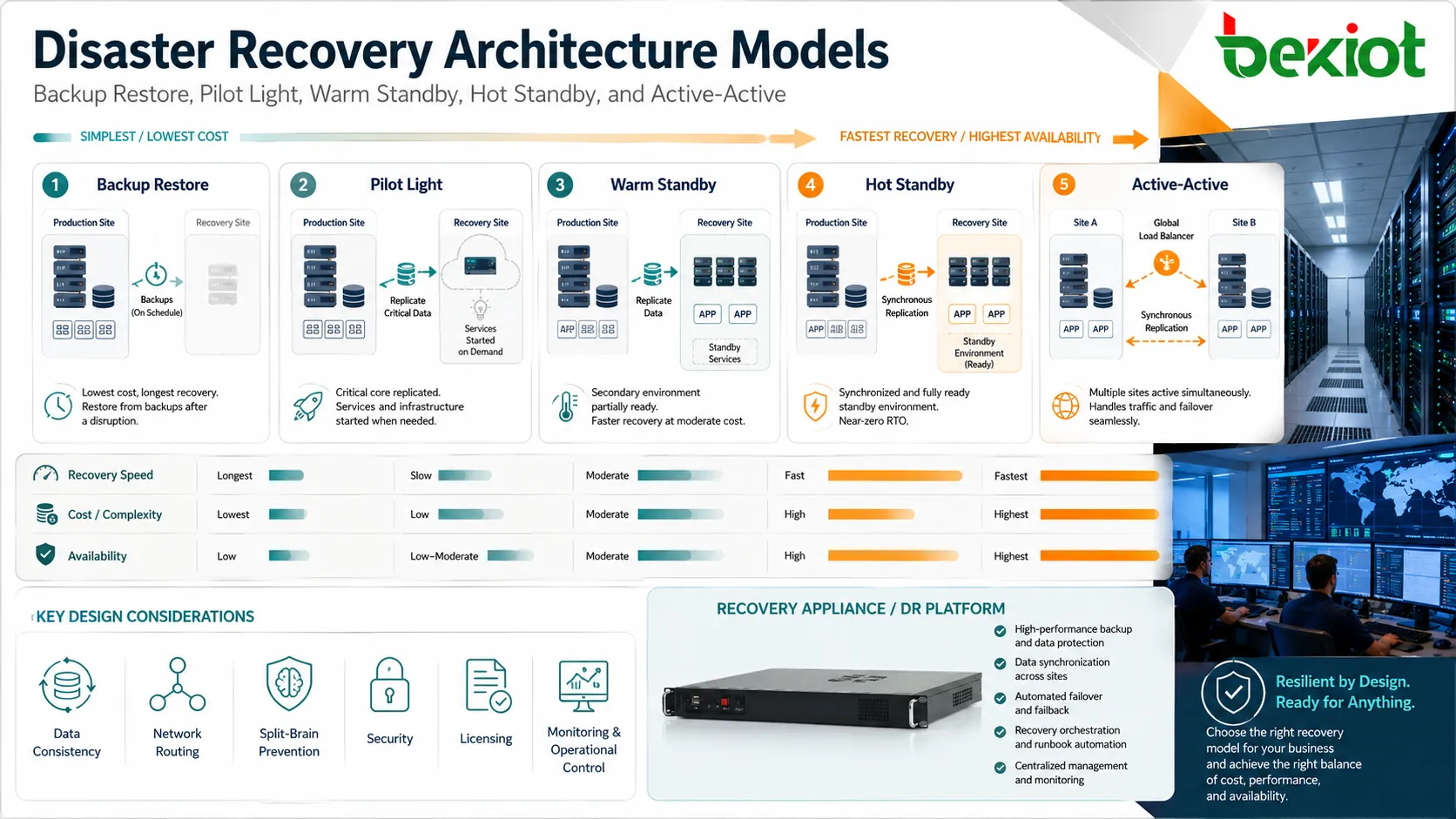
Основные архитектурные модели
Резервное копирование и восстановление
Самая простая модель хранит резервные копии и восстанавливает их при необходимости. Обычно она дешевле, но медленнее, потому что серверы, приложения, данные и конфигурации могут потребовать ручного восстановления или повторной сборки.
Эта модель подходит для некритичных систем, малого бизнеса, архивных нагрузок или приложений с более длительным допустимым простоем. Ее все равно нужно тестировать, потому что непроверенные копии могут отказать при реальном восстановлении.
Минимальная резервная среда
Дизайн pilot light поддерживает минимальную среду восстановления в рабочем состоянии. Ключевые компоненты, такие как базы данных, сетевая основа, службы идентификации или шаблоны конфигурации, уже могут существовать, а серверы приложений масштабируются только во время восстановления.
Такой подход балансирует стоимость и скорость. Он быстрее, чем построение всего с нуля, но дешевле, чем постоянная работа полной дублирующей среды.
Теплый резерв
Среда теплого резерва заранее поддерживает больше систем в работе. Данные могут регулярно реплицироваться, а прикладные сервисы могут быть установлены и частично активны. Во время инцидента среда масштабируется, повышается или перенастраивается для обслуживания производственного трафика.
Эта модель полезна, когда нужно сократить простой, но полностью активная вторичная площадка слишком дорога.
Горячий резерв или active-active
Самые быстрые проекты держат вторичную среду постоянно синхронизированной и готовой обслуживать пользователей. В схемах active-active несколько площадок могут одновременно обрабатывать рабочий трафик с балансировкой нагрузки и репликацией между локациями.
Эти модели уменьшают простой, но требуют тщательного проектирования. Согласованность данных, сетевой маршрутизации, предотвращение split-brain, лицензирование, безопасность, мониторинг и операционный контроль становятся сложнее.
Важные технические функции
Автоматическое расписание резервного копирования
Автоматические расписания уменьшают зависимость от ручных операций. Системы могут создавать копии ежечасно, ежедневно, еженедельно или непрерывно в зависимости от требуемого RPO.
Расписания должны соответствовать поведению рабочей нагрузки. База данных, изменяющаяся каждую минуту, требует иной стратегии защиты, чем статический архив документов.
Неизменяемые и офлайн-копии
Неизменяемые резервные копии нельзя изменять или удалять в течение заданного периода. Офлайн-копии или air-gapped-копии отделены от рабочей среды. Эти меры важны против ransomware, внутренних угроз, случайного удаления и скомпрометированных учетных записей администраторов.
План восстановления, который хранит все копии в той же скомпрометированной среде, может отказать именно тогда, когда он нужен больше всего.
Репликация и синхронизация
Репликация копирует данные из основной среды в другое место. Она может быть синхронной, когда записи подтверждаются на обеих сторонах до завершения, или асинхронной, когда изменения копируются вскоре после появления.
Синхронная репликация может снизить потерю данных, но требует каналов с низкой задержкой и может влиять на производительность. Асинхронная репликация гибче на расстоянии, но может потерять последние изменения при внезапном отказе основной площадки.
Защита с учетом приложения
Защита с учетом приложения понимает характер защищаемой нагрузки. Базы данных, почтовые системы, виртуальные машины, файловые серверы и корпоративные приложения могут требовать специальных шагов для согласованных резервных копий.
Например, простое копирование файлов базы данных во время их изменения может не дать чистую точку восстановления. Снимки с учетом приложения и обработка журналов транзакций улучшают качество восстановления.
Автоматизация восстановления
Автоматизация может запускать виртуальные машины, подключать хранилище, обновлять сетевые правила, запускать скрипты, менять DNS, проверять сервисы и создавать записи об инциденте. Она сокращает ручную работу и делает восстановление более повторяемым.
Ручное восстановление может работать в небольших средах, но сложные системы обычно нуждаются в задокументированных и автоматизированных процессах, чтобы снижать ошибки под давлением.
Применение в разных средах
Корпоративные ИТ-системы
Предприятия используют технологию восстановления для защиты ERP, CRM, электронной почты, систем идентификации, файловых ресурсов, баз данных, интранет-платформ и бизнес-приложений. Цель — сохранить доступность основных операций после крупных инцидентов.
Такие среды часто требуют многоуровневого восстановления. Критически важные приложения получают более быстрые цели, а менее срочные системы используют более экономичную защиту.
Облачная и гибридная инфраструктура
Облачные среды поддерживают снимки, межрегиональную репликацию, инфраструктуру как код, управляемые базы данных, версионирование объектного хранилища и автоматизированные схемы failover. Гибридные системы могут объединять локальные дата-центры с облачными ресурсами восстановления.
Облачное восстановление может уменьшить необходимость в полноценном вторичном дата-центре, но все равно требует планирования сети, проектирования безопасности, контроля затрат и регулярного тестирования.
Промышленные и коммунальные операции
Заводы, электростанции, системы водоочистки, нефтегазовые площадки и логистические центры могут нуждаться в планах восстановления для систем управления, исторических архивов, серверов мониторинга, коммуникационных платформ и рабочих мест операторов.
Эти среды должны учитывать безопасность, управление процессами в реальном времени, устаревшие протоколы, доступ к полевым устройствам и строгий контроль изменений. Восстановление не должно создавать небезопасных условий эксплуатации.
Здравоохранение и общественные службы
Больницам, центрам экстренного реагирования, государственным сервисам и общественным объектам во время сбоев нужен доступ к записям, коммуникациям, расписаниям, системам безопасности и операционным данным.
Планирование должно учитывать конфиденциальность, аудиторские следы, влияние на пациентов или граждан, аварийные процедуры и доступ персонала в нестандартных условиях.
Телекоммуникации и коммуникационные сервисы
Коммуникационные платформы требуют восстановления для управления вызовами, маршрутизации, медиасервисов, записи, голосовой почты, SIP-транков, шлюзов, контакт-центров и данных регистрации пользователей.
Поскольку такие системы часто поддерживают экстренное реагирование и взаимодействие с клиентами, тесты восстановления должны включать реальные потоки вызовов, а не только запуск серверов.
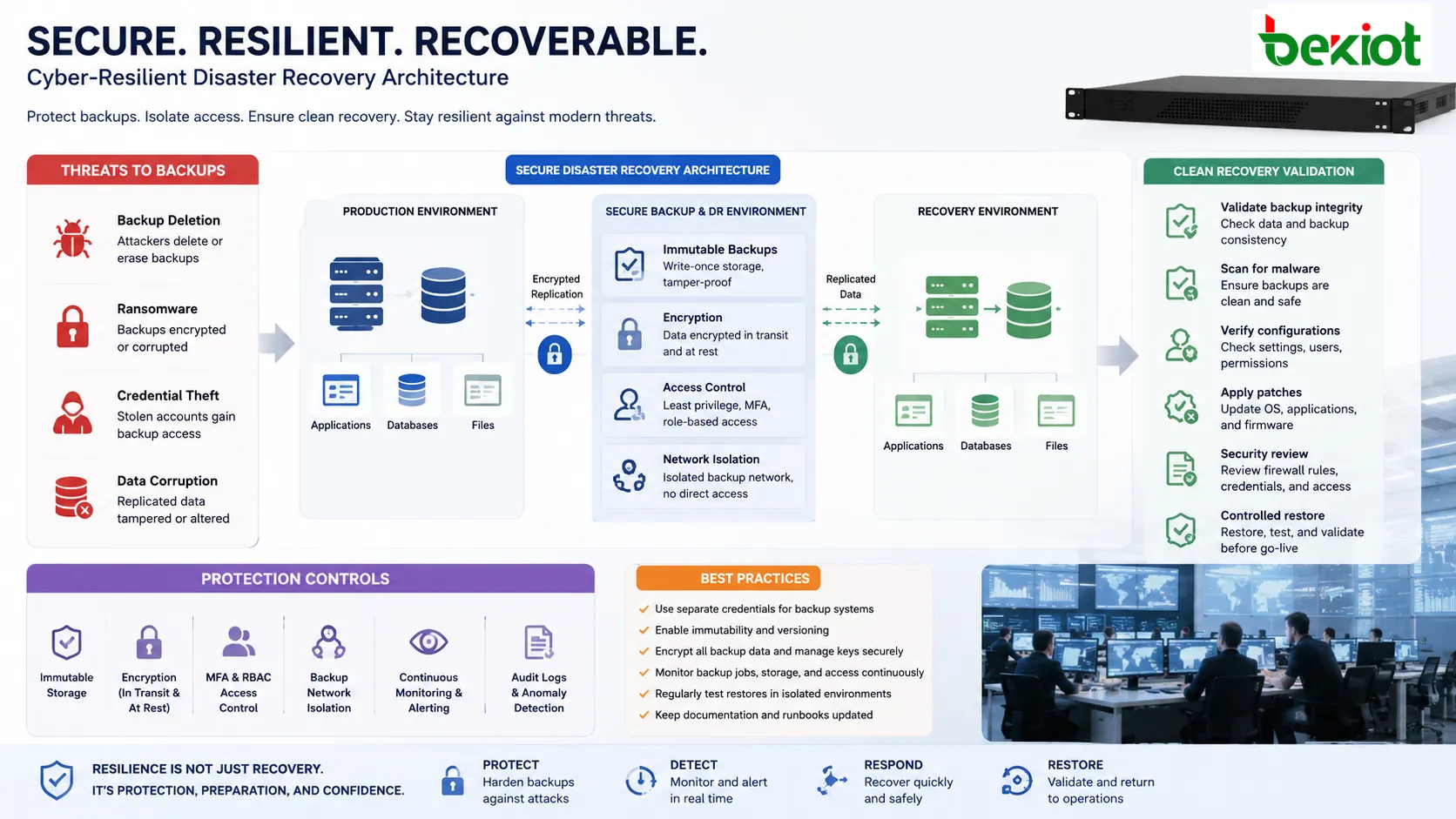
Целостность данных и кибербезопасность
Современное планирование восстановления должно исходить из того, что кибератаки могут нацеливаться на резервные копии так же, как на производственные системы. Злоумышленники могут удалить копии, зашифровать репозитории, украсть учетные данные или повредить реплицированные данные. Поэтому изоляция резервных копий, контроль доступа, неизменяемость, шифрование и мониторинг необходимы.
Данные восстановления должны защищаться при передаче и хранении. Ключи шифрования нужно управлять осторожно, потому что потеря ключа может сделать восстановление невозможным. Репозитории резервных копий не должны использовать те же учетные данные и разрешения, что обычные производственные учетные записи.
Проверка безопасности после восстановления также важна. Восстановление системы из резервной копии может вернуть устаревшее ПО, уязвимые конфигурации или скомпрометированные учетные записи. Команды должны проверить обновления, учетные данные, правила межсетевого экрана и безопасность конечных точек перед возвратом сервиса пользователям.
Тестирование и учения готовности
План восстановления, который никогда не тестировался, является лишь предположением. Тестирование подтверждает, что резервные копии можно восстановить, приложения корректно запускаются, пользователи могут входить, данные согласованы, сетевые маршруты работают, а персонал знает свои действия.
Тестирование может выполняться на разных уровнях. Тест восстановления файла проверяет, можно ли восстановить отдельные данные. Тест восстановления приложения проверяет, можно ли восстановить один сервис. Полная симуляция проверяет отказ площадки и весь процесс переключения.
Учения должны документироваться. Команда должна фиксировать время восстановления, найденные проблемы, отсутствующие доступы, неудачные скрипты, устаревшую документацию и корректирующие действия. Каждый тест должен улучшать план.
Типичные точки отказа
Резервные копии, которые никогда не восстанавливали
Многие организации слишком поздно обнаруживают, что задания резервного копирования завершались, но данные нельзя корректно восстановить. Это может происходить из-за поврежденных файлов, отсутствующих зависимостей, неверных учетных данных, неподдерживаемых версий или неполных данных приложения.
Тест восстановления — единственный надежный способ доказать, что резервные данные полезны.
Отсутствующие конфигурационные файлы
Приложения могут зависеть от конфигурационных файлов, сертификатов, переменных окружения, таблиц маршрутизации, правил межсетевого экрана, лицензий и сервисных учетных записей. Если эти элементы не защищены, данные могут быть восстановлены, но приложение не запустится.
Резервное копирование конфигураций должно считаться частью области восстановления.
Неясная ответственность
Во время инцидента путаница в том, кто принимает решения, может замедлить восстановление. В процесс могут быть вовлечены ИТ, безопасность, эксплуатация, бизнес-руководители, облачные команды и поставщики.
План должен определить роли, полномочия утверждения, контакты эскалации и каналы связи до возникновения кризиса.
Репликация плохих данных
Репликация полезна, но она может скопировать повреждение, удаление или зашифрованные файлы на вторичную площадку. Поэтому восстановление на момент времени и неизменяемые копии остаются важными даже при наличии репликации.
Репликация улучшает непрерывность; она не заменяет чистые исторические точки восстановления.
Сетевой доступ не готов
Восстановленное приложение бесполезно, если пользователи не могут к нему подключиться. DNS, VPN, firewall, балансировщик нагрузки, сертификаты, маршрутизация и зависимости идентификации должны входить в тесты восстановления.
Готовность сети часто определяет разницу между техническим восстановлением и реально пригодным сервисом.
Настоящая мера технологии восстановления — не то, существуют ли данные где-то. Важно, могут ли нужные люди безопасно возобновить нужный сервис в требуемое временное окно.
Контрольный список внедрения
Классифицируйте системы по бизнес-приоритету. Определяйте RTO и RPO для каждого сервиса, а не используйте одну общую цель для всего.
Выберите подходящий метод защиты. Backup restore, снимки, репликация, резервные среды и active-active-проекты обслуживают разные потребности и уровни затрат.
Защищайте копии от киберрисков. Используйте неизменяемость, отдельные учетные данные, шифрование, минимальные привилегии, мониторинг резервных копий и офлайн- или изолированные копии там, где это уместно.
Документируйте шаги восстановления. Включайте зависимости систем, порядок запуска, сетевые изменения, методы входа, контакты поставщиков, требования лицензий и тесты проверки.
Тестируйте регулярно. Процесс восстановления должен быть отработан до реального инцидента. Обновляйте план после изменений инфраструктуры, облачных миграций, обновлений приложений и изменений политики безопасности.
FAQ
Предоставляет ли облачный хостинг аварийное восстановление автоматически?
Нет. Облачные платформы предоставляют полезные инструменты, но клиент все равно должен настроить резервное копирование, репликацию, регионы, разрешения, мониторинг, процедуры восстановления и тестирование.
Как часто нужно тестировать планы восстановления?
Частота зависит от бизнес-риска и критичности системы. Критические системы могут требовать регулярных учений, а менее важные системы могут тестироваться во время плановых проверок или после крупных изменений.
Может ли ransomware повлиять на системы резервного копирования?
Да. Злоумышленники могут атаковать репозитории резервных копий и учетные данные администраторов. Неизменяемые копии, офлайн-копии, отдельные разрешения и мониторинг помогают снизить этот риск.
В чем разница между высокой доступностью и аварийным восстановлением?
Высокая доступность сосредоточена на поддержании работы сервисов при небольших отказах. Аварийное восстановление сосредоточено на восстановлении сервисов после более крупных нарушений, включая отказ площадки, кибератаку или серьезную потерю данных.
Что следует проверить после реального события восстановления?
Проверьте время восстановления, потерю данных, неудачные шаги, пробелы коммуникации, влияние на пользователей, результаты безопасности, реакцию поставщиков, точность документации и улучшения, необходимые до следующего инцидента.