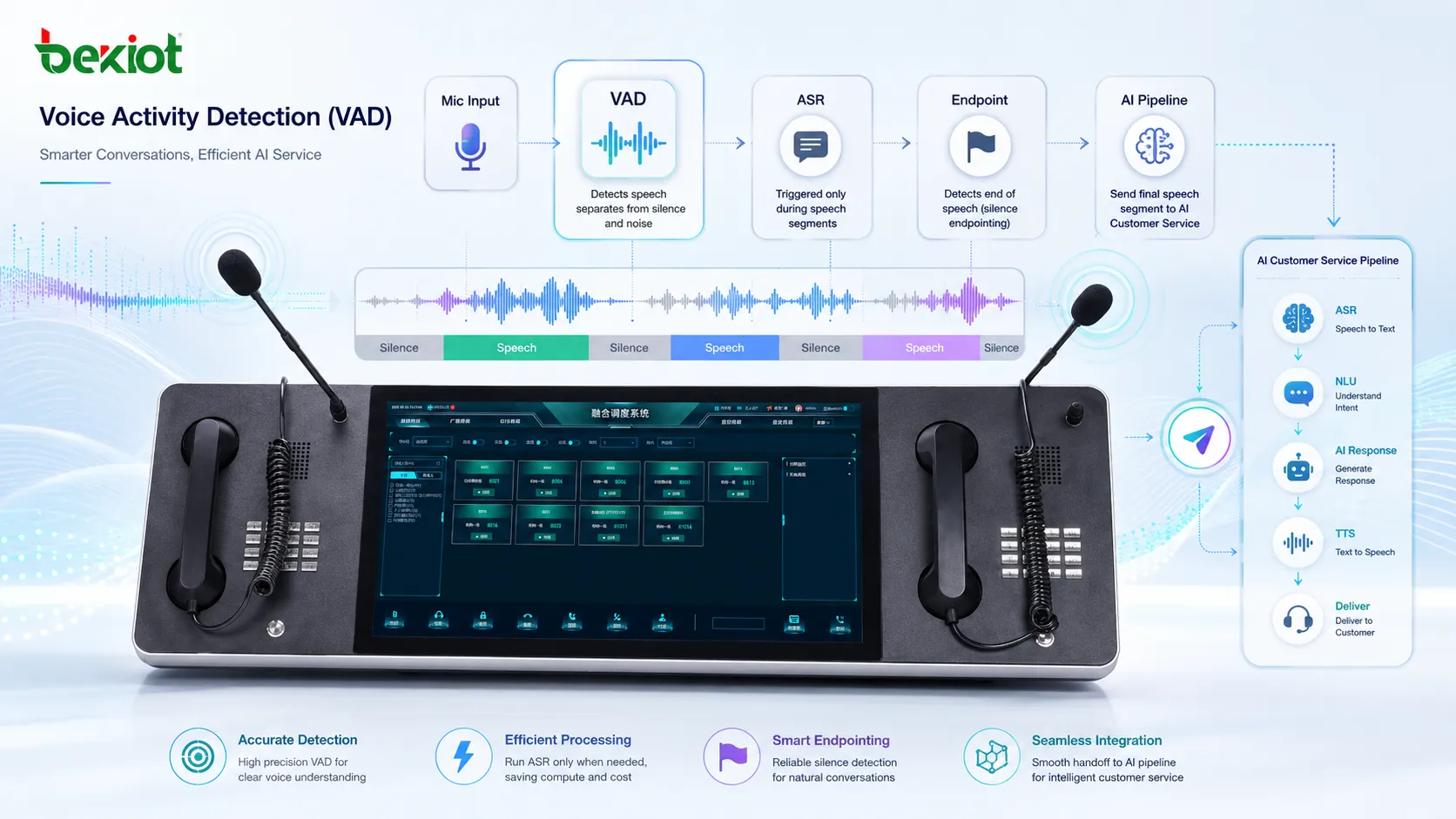
Обнаружение речевой активности, часто сокращаемое как VAD, — это технология, которая определяет, содержит ли аудиосигнал человеческую речь или неречевое содержимое: тишину, фоновый шум, музыку, звуки клавиатуры, дыхание или помехи окружающей среды. Она широко применяется в VoIP-системах, голосовых помощниках с ИИ, распознавании речи, платформах конференцсвязи, записи вызовов, двусторонней радиосвязи, мобильных приложениях и встроенных коммуникационных устройствах.
Что означает обнаружение речевой активности в аудиосистемах
В аудиосистеме реального времени микрофон постоянно принимает звук. Не каждый звук нужно передавать, записывать, обрабатывать или отправлять в механизм распознавания речи. VAD помогает системе понять, когда человек действительно говорит, а когда аудиопоток можно считать тишиной или фоновым шумом.
Такое решение выглядит простым, но технически оно очень важно. Плохой VAD может обрезать начало или конец фразы, отправлять на сервер слишком много шума, вызывать ложные срабатывания или создавать ощущение задержки. Хорошо настроенный VAD повышает качество речи, экономит полосу пропускания, снижает вычислительные затраты и делает голосовое взаимодействие более естественным.

Как работает обнаружение речевой активности
Анализ аудиосигнала
VAD начинается с анализа коротких аудиокадров. Такие кадры обычно измеряются миллисекундами, поэтому система может быстро принимать решения, не ожидая длинной записи. Каждый кадр может проверяться по уровню энергии, частотному распределению, изменению сигнала, частоте пересечения нуля, спектральным признакам или вероятности речи, рассчитанной моделью машинного обучения.
Традиционные методы VAD часто опираются на акустические пороги. Например, если энергия аудио выше уровня фонового шума, система может считать сигнал речью. Современные системы используют нейронные сети или статистические модели, чтобы точнее отличать речь от шума, особенно в среде с вентиляторами, транспортом, оборудованием, музыкой или несколькими говорящими.
Решение о речи и тишине
После анализа аудиокадра механизм VAD принимает решение: речь, тишина или иногда неопределенное состояние. В реальных системах это решение обычно сглаживается по времени. Без сглаживания результат может слишком быстро переключаться между речью и тишиной, что приводит к неестественному обрезанию звука.
В большинстве внедрений используются параметры: порог начала, порог окончания, минимальная длительность речи, тайм-аут тишины и время удержания. Время удержания означает, что система еще короткое время считает аудио речью после падения речевой энергии. Это помогает не обрезать последнюю слоговую часть фразы слишком рано.
Интеграция с обработкой голоса
VAD редко используется отдельно. Он часто работает вместе с шумоподавлением, эхоподавлением, автоматической регулировкой усиления, распознаванием речи, обнаружением слова активации, записью вызовов, сжатием аудио и протоколами связи в реальном времени. В голосовой системе ИИ VAD может решать, когда начинать отправку аудио в ASR и когда прекращать прослушивание фразы пользователя.
В VoIP или конференцсистеме VAD может сокращать передачу пакетов во время тишины. В системах записи он может помечать активные речевые сегменты для удобного воспроизведения и поиска. Во встроенных устройствах он снижает нагрузку на процессор и расход батареи, исключая ненужную обработку аудио.
Основные возможности обнаружения речевой активности
Обнаружение речи в реальном времени
Главная особенность VAD — обнаружение в реальном времени. Система должна распознавать речь достаточно быстро, чтобы поддерживать естественное общение. Если задержка слишком велика, пользователи ощущают медленный ответ, прерывание диалога или задержку взаимодействия с ИИ.
VAD в реальном времени особенно важен для голосовых помощников, ИИ-обслуживания клиентов, диспетчерской связи, систем push-to-talk, видеоконференций и громкой связи через интерком. В этих сценариях нужно быстро обнаруживать начало речи и устойчиво определять тишину в конце фразы.
Устойчивость к шуму
Реальные акустические условия редко бывают тихими. VAD-система может работать в офисах, на заводах, в транспорте, на улицах, в больницах, школах, складах, контакт-центрах, диспетчерских или на открытых площадках. Фоновый шум усложняет обнаружение речи, особенно когда его уровень меняется со временем.
Устойчивый к шуму VAD адаптируется к изменяющимся звуковым условиям и уменьшает ложные срабатывания. Например, он не должен принимать печать на клавиатуре, кондиционер, короткие удары или дальние разговоры за голос основного говорящего. Это повышает точность и снижает лишнюю передачу аудио.
| Возможность VAD | Что делает | Почему это важно |
|---|---|---|
| Обнаружение начала речи | Определяет, когда пользователь начинает говорить | Помогает системе быстро отвечать и не терять первые слова |
| Определение конца по тишине | Определяет, когда речь закончилась | Позволяет ASR, записи или логике ИИ остановиться в нужный момент |
| Фильтрация шума | Снижает ложное обнаружение из-за фоновых звуков | Повышает точность в реальной среде |
| Управление удержанием | Короткое время сохраняет состояние речи после падения сигнала | Не дает обрезать окончания слов и предложений |
| Покадровый анализ | Непрерывно обрабатывает короткие аудиосегменты | Поддерживает решения в реальном времени с низкой задержкой |
Настраиваемая чувствительность
Разным приложениям нужна разная чувствительность VAD. Голосовой помощник в тихом офисе может использовать более чувствительную настройку, а промышленный интерком требует более жесткой фильтрации, чтобы не реагировать на машины. Настройка чувствительности помогает сбалансировать пропущенную речь и ложные срабатывания.
К типичным параметрам относятся порог энергии аудио, минимальная длина речи, максимальная длительность тишины, задержка окончания речи, адаптация к уровню шума и оценка уверенности. Эти параметры настраиваются по расстоянию до микрофона, фоновому шуму, стилю речи пользователя и требованиям к скорости ответа.
Почему обнаружение речевой активности важно
Лучший пользовательский опыт
В голосовом взаимодействии время реакции критично. Если система начинает слушать слишком поздно, она может пропустить первое слово. Если останавливается слишком рано, она обрезает пользователя. Если слишком долго ждет после завершения фразы, система кажется медленной. VAD делает обмен репликами между человеком и машиной более плавным.
Это особенно важно для ИИ-обслуживания клиентов, умных помощников, голосового поиска, диктовки и управления без рук. Пользователи ожидают, что система сама поймет, когда они говорят, без нажатия кнопок и ручного запуска или остановки записи.
Меньшая полоса пропускания и стоимость обработки
Передача и обработка аудио потребляют сетевую полосу, серверные ресурсы и энергию устройства. Передавая или обрабатывая только сегменты с речью, VAD снижает ненужную нагрузку. Это полезно для крупных голосовых платформ, облачных ASR-сервисов, конференцсистем и мобильных приложений.
В периферийных устройствах VAD также помогает снизить энергопотребление. Устройство может держать ресурсоемкие модули неактивными до обнаружения речи, что важно для продуктов с батарейным питанием и встроенных голосовых терминалов.
Более чистые записи и удобный анализ
В системах записи VAD отделяет полезную речь от длительных периодов тишины. Это облегчает просмотр аудиоархивов и сокращает расход хранилища. Для контакт-центров, совещаний, интервью, диспетчерских и записей для соответствия требованиям сегментация речи повышает эффективность поиска и воспроизведения.
Некоторые системы используют метки VAD, чтобы выделять активные речевые участки на временной шкале. Проверяющие могут сразу переходить к голосовым сегментам, а не слушать длинные интервалы тишины.
Типичные области применения
Автоматическое распознавание речи
ASR-системы используют VAD, чтобы определить, какая часть аудиопотока должна распознаваться как речь. Без VAD механизм распознавания может получать слишком много тишины или шума, что повышает стоимость обработки и снижает стабильность распознавания.
В разговорном ИИ VAD также используется для определения конца высказывания. Когда система понимает, что пользователь перестал говорить, она отправляет завершенную фразу в языковую модель или диалоговый механизм. Хорошее определение конца делает разговор быстрее и естественнее.
VoIP и видеоконференции
VoIP-телефоны, программные телефоны, конференцплатформы и WebRTC-приложения могут использовать VAD для оптимизации передачи аудио. Во время тишины система может уменьшить отправку пакетов или отметить поток как неактивный. Это снижает использование сети, особенно в больших встречах или при низкой пропускной способности.
VAD также может поддерживать обнаружение активного говорящего в видеовстречах. Когда система знает, кто говорит, она может выделить говорящего, изменить раскладку или улучшить аудиомикширование.
Контакт-центры и контроль качества
Контакт-центры используют VAD для анализа речевых шаблонов операторов и клиентов. Он помогает выявлять тишину, перебивания, длинные паузы, одновременную речь и задержки ответа. Эти данные поддерживают контроль качества, оптимизацию сценариев и обучение операторов.
В сочетании с речевой аналитикой VAD также помогает сегментировать разговоры перед расшифровкой, поиском ключевых слов, анализом тональности или проверкой соответствия требованиям.
Радиосвязь, интерком и push-to-talk
В радиосвязи и интеркомах VAD может управлять включением аудио, уменьшать шум открытого канала и улучшать работу без рук. Он применяется в диспетчерских системах, промышленных интеркомах, транспортной связи, комнатах охраны и сетях аварийного реагирования.
Однако такие среды часто содержат сильный фоновый шум. Настройки VAD нужно подбирать аккуратно, чтобы сирены, двигатели, тревоги, оборудование, ветер и другие неречевые звуки не вызывали ложную активацию.
Что учитывать при внедрении
Качество и расположение микрофона
Производительность VAD сильно зависит от качества аудиовхода. Даже хороший алгоритм может работать плохо, если микрофон слишком далеко от говорящего, открыт ветру, расположен рядом с источником шума или страдает от эха. Выбор и размещение микрофона должны быть частью проекта VAD.
Направленные микрофоны, акустическая защита, эхоподавление и шумоподавление могут повысить качество обнаружения. В конференц-залах и промышленных помещениях схема размещения микрофонов может быть так же важна, как программная настройка.
Задержка и время определения конца
Низкая задержка важна, но слишком агрессивное обрезание речи ухудшает опыт пользователя. Система должна сочетать быстрый ответ и полное захватывание речи. Например, ИИ-помощнику может быть нужен короткий тайм-аут тишины, а программе диктовки — более длинный, чтобы учитывать естественные паузы.
Время определения конца должно соответствовать приложению. Командная фраза, разговор с клиентом, протокол совещания и диспетчерское радиосообщение могут требовать разных длительностей тишины.
Тестирование в реальных акустических условиях
VAD нужно тестировать на реалистичном аудио, а не только на чистых лабораторных записях. Полевые испытания должны включать разных говорящих, акценты, темпы речи, расстояния до микрофона, уровни шума, эхо и состояния сети.
Тесты также должны проверять крайние случаи: короткие ответы, шепот, одновременную речь, внезапный шум, длинные паузы и речь после тишины. Эти ситуации часто показывают, подходит ли конфигурация VAD для эксплуатации.

Заключение
Обнаружение речевой активности — базовая технология современных голосовых систем. Она помогает определить, когда речь начинается, когда заканчивается и какие части аудиопотока нужно передавать, записывать или обрабатывать. Хотя VAD работает за кулисами, он напрямую влияет на пользовательский опыт, эффективность полосы пропускания, точность ASR, качество записи и производительность связи в реальном времени.
Успешное внедрение VAD требует большего, чем включение одной функции. Нужно учитывать качество микрофона, акустическую среду, настройки чувствительности, целевую задержку, время определения конца, шумоподавление и рабочий процесс приложения. При правильном проектировании и тестировании VAD делает голосовые системы быстрее, чище, эффективнее и естественнее.
FAQ
Обнаружение речевой активности — это то же самое, что обнаружение слова активации?
Нет. VAD определяет, присутствует ли речь, а обнаружение слова активации ищет конкретную фразу, например имя устройства или команду запуска. Система может использовать VAD перед обнаружением слова активации, чтобы уменьшить лишнюю обработку, но это разные функции.
Может ли VAD понять, что говорит человек?
Нет. VAD не распознает слова и смысл. Он только решает, вероятно ли наличие речи в аудио. Для преобразования речи в текст и понимания намерения пользователя нужны распознавание речи или обработка естественного языка.
Почему VAD иногда останавливается до того, как пользователь закончит говорить?
Обычно это происходит, когда тайм-аут тишины слишком короткий, пользователь делает паузы между словами, уровень микрофона низкий или фоновые шумы делают обнаружение нестабильным. Настройка задержки конца, усиления и времени удержания помогает уменьшить проблему.
Хорошо ли VAD работает, когда несколько людей говорят одновременно?
VAD может определить наличие речи, но не разделяет говорящих автоматически. В многоабонентской среде могут потребоваться диаризация говорящих, формирование луча или разделение источников звука, чтобы понять, кто говорит.
Должен ли VAD работать на устройстве или в облаке?
Возможны оба варианта. VAD на устройстве снижает расход полосы, улучшает приватность и уменьшает стоимость облачной обработки. Облачный VAD может предложить более сильные модели и простые обновления. Лучший выбор зависит от задержки, приватности, возможностей оборудования и архитектуры системы.