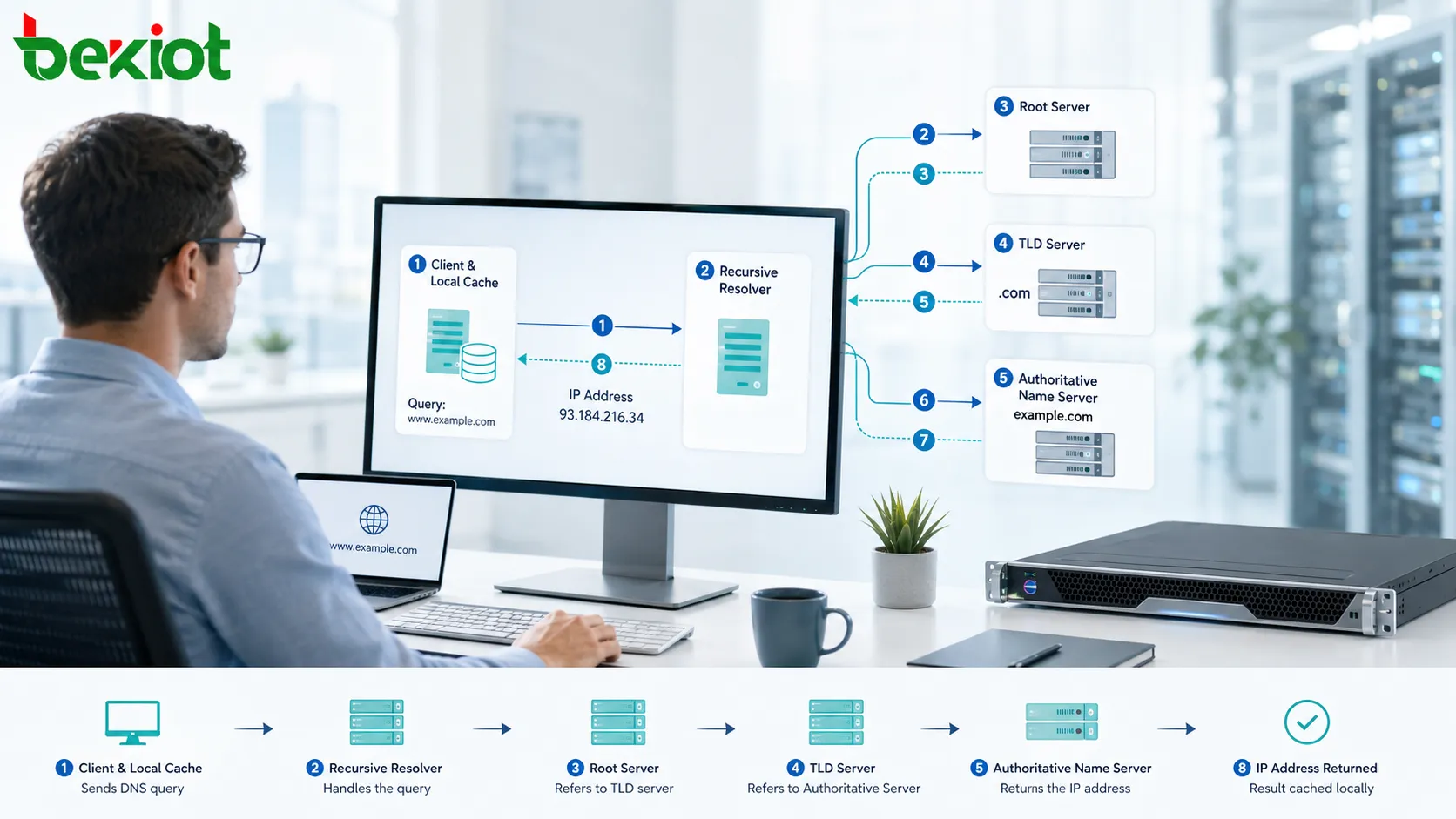
Аптайм — это время, в течение которого система, сервис, устройство, приложение, сеть или платформа остаются доступными и работоспособными. Простыми словами, он показывает пользователям, как долго что-либо работало без перебоев. Когда сайт доступен, сервер работает, коммуникационная платформа находится онлайн или сетевое устройство продолжает нормально функционировать, этот период засчитывается как аптайм.
Аптайм — один из важнейших показателей надёжности в сферах ИТ, сетей, телекоммуникаций, облачных сервисов, промышленных систем, веб-сайтов, дата-центров, платформ безопасности и бизнес-коммуникаций. Он помогает организациям понять, достаточно ли их системы надёжны для поддержки ежедневных операций. Сервис с высоким аптаймом доступен большую часть времени. Сервис с низким аптаймом может страдать от частых прерываний, отказов, перезагрузок или периодов недоступности.
В реальной эксплуатации аптайм — это не просто техническая цифра. Он влияет на клиентский опыт, непрерывность бизнеса, репутацию сервиса, реагирование на чрезвычайные ситуации, производительность и операционное доверие. Если система недоступна, когда она нужна людям, даже самый мощный набор функций может потерять практическую ценность. Вот почему аптайм часто обсуждается вместе с мониторингом, резервированием, планированием обслуживания, соглашениями об уровне услуг и аварийным восстановлением.
Что такое аптайм?
Определение и основное значение
Аптайм означает период, в течение которого система или сервис функционируют и доступны для использования. Это может относиться к серверу, маршрутизатору, коммутатору, веб-сайту, приложению, базе данных, облачной платформе, IP-АТС, системе безопасности, промышленному контроллеру или любому подключённому устройству, от которого зависят пользователи. Если система доступна и работает так, как ожидается, она считается работающей.
Ключевой смысл аптайма — доступность с течением времени. Это не означает просто, что устройство включено. Сервер может быть включён, но не способен отвечать пользователям. Сетевое устройство может работать, но не может корректно передавать трафик. Веб-сайт может частично загружаться, но отказывать в ключевых функциях. Для практического измерения аптайма система обычно должна быть доступна таким образом, чтобы обеспечивать предусмотренный сервис.
Вот почему аптайм следует определять в соответствии с реальным назначением системы. Проверка аптайма веб-сайта может фокусироваться на ответе страницы. Для коммуникационного сервиса — на регистрации, сигнализации и завершении вызовов. Для платформы баз данных — на ответе на запросы. Для системы мониторинга — на сборе данных и доступности оповещений.
Аптайм — это не только о том, включено ли оборудование. Это о том, действительно ли ожидаемый сервис доступен, когда он нужен пользователям.
Аптайм и доступность
Аптайм и доступность тесно связаны, и во многих повседневных обсуждениях они используются почти как взаимозаменяемые понятия. Однако доступность часто рассматривается как более широкая сервисная метрика. Аптайм описывает, как долго система остаётся работоспособной, в то время как доступность может включать в себя, способна ли система предоставлять требуемую функцию пользователям в реальных условиях.
Например, процесс на сервере может выполняться, но если пользователи не могут до него добраться из-за проблемы с сетью, сервис всё равно может быть недоступен. В этом случае сам сервер может иметь аптайм, но сервис, ориентированный на пользователя, не обладает полной доступностью. Это различие важно в сложных системах, где множество компонентов работают вместе.
В практическом управлении сервисами организации обычно больше всего заботятся о доступности, воспринимаемой пользователем. Сервис должен работать с точки зрения пользователя, а не только с экрана локального состояния устройства.

Как работает аптайм
Измерение времени работы
Аптайм работает путём измерения продолжительности времени, в течение которого система остаётся в исправном и доступном состоянии. Это можно измерять от времени загрузки системы, времени запуска сервиса, времени ответа мониторинга или определённого окна доступности сервиса. Метод зависит от того, что измеряется, и от того, что организация считает работоспособным.
Для отдельного устройства аптайм может отображаться как время с момента последней перезагрузки. Для веб-сайта аптайм может измеряться внешними зондами, которые проверяют, корректно ли отвечает сайт. Для сетевого сервиса аптайм может зависеть от того, могут ли пользователи подключаться, проходить аутентификацию, обмениваться данными и завершать предполагаемую транзакцию.
Наиболее полезное измерение аптайма привязано к поведению сервиса. Система, которая технически работает, но не выполняет свою основную функцию, не должна считаться полностью доступной в серьёзной операционной модели.
Отслеживание времени простоя и процента доступности
Аптайм часто выражается в процентах за определённый период, например за месяц или год. Базовая формула сравнивает время, когда система была доступна, с общим временем измерения. Если сервис был доступен почти весь период, его процент аптайма будет высоким. Если он испытывал длительные отказы, процент снизится.
Например, сервис, доступный 99,9% времени в месяц, имеет меньше времени простоя, чем сервис, доступный 99%. Эти проценты могут выглядеть близкими, но фактическая разница во времени простоя может быть значительной. Небольшие процентные различия имеют огромное значение в системах, поддерживающих бизнес-операции, клиентский доступ или критически важную связь.
Вот почему аптайм часто используется в соглашениях об уровне обслуживания. Поставщик может гарантировать определённый процент аптайма, а клиенты используют это обязательство для понимания ожидаемой надёжности сервиса.
Процент аптайма кажется простым, но небольшие различия могут означать очень разное количество реального времени простоя.
Распространённые уровни аптайма и их значение
Понимание аптайма 99%, 99,9% и 99,99%
Аптайм часто обсуждается в терминах «девяток». Система с аптаймом 99% доступна большую часть времени, но всё же допускает значительное количество простоя в течение года. Система с аптаймом 99,9% надёжнее и допускает гораздо меньше простоя. Система с аптаймом 99,99% значительно более требовательна и обычно нуждается в более сильном проектировании, мониторинге и операционной дисциплине.
Чем выше цель по аптайму, тем сложнее её достичь. Переход от 99% к 99,9% может потребовать лучшего мониторинга и обслуживания. Переход от 99,9% к 99,99% может потребовать резервирования, автоматического переключения при отказе, архитектуры высокой доступности, лучшего контроля изменений и более быстрого реагирования на инциденты.
При практическом планировании организации не должны выбирать цели по аптайму только потому, что они впечатляюще звучат. Следует сопоставлять цель с бизнес-рисками, стоимостью, ожиданиями пользователей и операционной важностью.
Почему более высокий аптайм стоит дороже
Более высокий аптайм обычно требует больших инвестиций. Одиночный сервер без резервирования развернуть проще и дешевле, но у него есть очевидные точки отказа. Система с высокой доступностью может потребовать резервных серверов, резервированного питания, множественных сетевых путей, балансировщиков нагрузки, баз данных с аварийным переключением, инструментов мониторинга и квалифицированного эксплуатационного персонала.
Расходы включают не только оборудование. Сюда входят планирование, тестирование, процедуры обслуживания, обучение персонала, архитектура программного обеспечения, реагирование на инциденты, а иногда и географическое резервирование. Каждый дополнительный уровень повышает отказоустойчивость, но также увеличивает сложность.
Вот почему аптайм следует рассматривать как требование к проектированию, а не просто как маркетинговое заявление. Требуемый уровень надёжности должен поддерживаться реальной архитектурой и операционными процессами.

Ключевые факторы, влияющие на аптайм
Надёжность оборудования и стабильность питания
Надёжность оборудования — один из самых базовых факторов, влияющих на аптайм. Серверы, устройства хранения, коммутаторы, маршрутизаторы, блоки питания, вентиляторы, диски и другие физические компоненты могут отказывать. Если критически важный компонент откажет без резервного пути, сервис может упасть.
Стабильность электропитания не менее важна. Даже мощные системы могут выйти из строя, если питание прервётся или будет нестабильным. Центры обработки данных и критически важные объекты часто используют источники бесперебойного питания, резервные генераторы, двойные вводы питания и мониторинг электропитания для снижения этого риска.
В небольших средах даже простые улучшения, такие как надёжная защита электропитания и правильно обслуживаемое оборудование, могут заметно повысить аптайм.
Сетевая связность и стабильность маршрутизации
Сетевая связность сильно влияет на аптайм, поскольку многие сервисы зависят от доступа к пользователям через локальные сети, глобальные сети или интернет. Сервер может быть исправен, но если сетевой путь нарушен, пользователи всё равно могут испытывать простой. Отказы коммутаторов, ошибки маршрутизации, проблемы DNS, неправильные настройки брандмауэра и сбои у интернет-провайдера — всё это может повлиять на доступность сервиса.
Резервированные сетевые каналы, использование нескольких провайдеров, продуманная схема маршрутизации, правильное управление DNS и непрерывный мониторинг помогают повысить аптайм. В системах бизнес-коммуникаций стабильность сети особенно важна, поскольку голос, видео, обмен сообщениями и облачные приложения зависят от надёжной связности.
С практической точки зрения, аптайм следует измерять на всём пути предоставления сервиса, а не только на основном устройстве.
Аптайм и архитектура системы
Резервирование и аварийное переключение
Резервирование — один из самых распространённых архитектурных методов повышения аптайма. Оно означает наличие резервных компонентов или путей, готовых включиться в работу при отказе основного компонента. Это может включать резервные серверы, блоки питания, диски, коммутаторы, сетевые каналы, базы данных, шлюзы или центры обработки данных.
Аварийное переключение (failover) — это процесс перевода сервиса с отказавшего компонента на резервный. В хорошо спроектированной системе аварийное переключение может происходить автоматически с минимальным или нулевым прерыванием для пользователей. В более простых системах может потребоваться ручное вмешательство.
Резервирование и аварийное переключение не устраняют все риски, но снижают вероятность того, что одиночный отказ остановит весь сервис. Они обязательны в системах, где простой имеет значительные последствия для бизнеса или безопасности.
Балансировка нагрузки и проектирование высокой доступности
Балансировка нагрузки также может поддерживать аптайм, распределяя трафик между несколькими серверами или экземплярами сервиса. Если один сервер перегружается или выходит из строя, другие серверы могут продолжать обрабатывать запросы. Это улучшает и производительность, и отказоустойчивость при правильной реализации.
Проектирование высокой доступности сочетает в себе множество техник, включая резервирование, аварийное переключение, кластеризацию, репликацию, проверки работоспособности, автоматическое восстановление и мониторинг. Цель — сохранить сервис доступным даже при отказе отдельных компонентов.
Систему с высокой доступностью необходимо тщательно тестировать. Резервные компоненты полезны только в том случае, если они действительно корректно принимают на себя нагрузку при возникновении отказа.
Аптайм строится архитектурой, а не благими пожеланиями. Надёжной системе нужны пути отработки отказов, спроектированные и проверенные до того, как отказ произойдёт.
Мониторинг аптайма
Внутренний и внешний мониторинг
Мониторинг аптайма проверяет, доступна ли система или сервис. Внутренний мониторинг наблюдает за компонентами изнутри среды, такими как процессор сервера, память, состояние дисков, состояние процессов, состояние базы данных и локальная сетевая связность. Внешний мониторинг проверяет сервис снаружи, ближе к перспективе пользователя.
Оба метода полезны. Внутренний мониторинг может выявить ранние признаки отказа до того, как пострадают пользователи. Внешний мониторинг может подтвердить, действительно ли сервис доступен извне. Система может выглядеть исправной внутренне, но оставаться недоступной из-за проблем DNS, маршрутизации, брандмауэра или вышестоящей сети.
Сильная стратегия мониторинга часто сочетает внутренние и внешние проверки, чтобы создать более полную картину аптайма.
Проверки работоспособности, оповещения и реагирование на инциденты
Проверки работоспособности — это автоматизированные тесты, которые подтверждают, работает ли система так, как ожидается. Простая проверка может подтвердить, что сервер отвечает на запрос. Более продвинутая проверка может верифицировать вход в систему, ответ базы данных, регистрацию вызовов, завершение транзакции или поведение API.
Оповещения уведомляют администраторов, когда аптайм находится под угрозой или происходит простой. Однако одних оповещений недостаточно. Организация также должна иметь процесс реагирования на инциденты, который определяет, кто расследует, как проблемы эскалируются, как информируются пользователи и как восстанавливается сервис.
Мониторинг становится наиболее ценным, когда он связывает обнаружение с действием. Быстрое получение информации о простое полезно только в том случае, если команда способна эффективно отреагировать.
Аптайм и SLA
Соглашения об уровне обслуживания (SLA)
Соглашение об уровне обслуживания, часто называемое SLA, может определять процент аптайма, который поставщик услуг или внутренняя команда обязуется обеспечить. Например, провайдер может обещать аптайм 99,9% за месячный расчётный период. В SLA также может объясняться, что считается простоем, какие окна обслуживания исключаются и какие компенсации или зачёты применяются, если цель не достигнута.
Формулировки SLA имеют значение, поскольку аптайм можно интерпретировать по-разному. Некоторые соглашения исключают плановое обслуживание. Некоторые учитывают только полный отказ сервиса, а не частичное ухудшение производительности. Некоторые измеряют доступность из сети провайдера, а не из местоположения клиента.
По этой причине пользователям следует внимательно читать определения SLA. Рекламируемый процент аптайма важен, но правила измерения не менее важны.
Плановое обслуживание и внеплановый простой
Плановое обслуживание — это запланированные работы, которые могут временно повлиять на доступность системы. Они могут включать обновление прошивок, обновление программного обеспечения, замену оборудования, обслуживание базы данных, установку исправлений безопасности или изменения в инфраструктуре. Многие расчёты аптайма рассматривают плановое обслуживание иначе, чем неожиданные отказы.
Внеплановый простой происходит, когда система неожиданно выходит из строя из-за отказа оборудования, сбоя программного обеспечения, сетевой аварии, ошибки конфигурации, кибератаки, потери питания или человеческой ошибки. Такой тип простоя обычно более разрушителен, потому что пользователи к нему не готовы.
Хорошее управление аптаймом сокращает внеплановые простои и чётко информирует о плановом обслуживании, чтобы пользователи могли подготовиться.
Советы по обслуживанию для повышения аптайма
Используйте профилактическое обслуживание
Профилактическое обслуживание помогает повысить аптайм, решая проблемы до того, как они превратятся в отказы. Оно может включать проверку журналов, обновление прошивок, применение исправлений безопасности, замену устаревающего оборудования, мониторинг дискового пространства, тестирование резервных копий и анализ тенденций производительности системы.
Профилактическое обслуживание должно быть плановым и документированным. Случайные изменения могут создавать новые проблемы, тогда как контролируемое обслуживание помогает снизить риск. Цель — поддерживать системы в исправном состоянии, не вызывая ненужных перерывов в работе.
В практической эксплуатации многие отказы можно предотвратить, если обслуживающие команды действуют до того, как предупреждающие признаки превратятся в сбои.
Тщательно контролируйте изменения
Изменения конфигурации — распространённый источник простоев. Правило брандмауэра, изменение маршрутизации, обновление ПО, замена сертификата, корректировка базы данных или изменение политики доступа могут случайно нарушить работу сервиса, если не проверить их должным образом. Контроль изменений помогает снизить этот риск.
Хороший контроль изменений включает документацию, согласование, тестирование, планирование отката, выбор времени и проверку после внесения изменений. Для критически важных систем изменения следует вносить в периоды низкой нагрузки и сразу после этого внимательно отслеживать состояние.
Аптайм часто зависит от дисциплинированной эксплуатации не меньше, чем от мощного оборудования.
Многие проблемы с аптаймом начинаются не с вышедшего из строя оборудования. Они начинаются с неконтролируемых изменений, слабых привычек обслуживания или отсутствия проверок.
Применение измерения аптайма
Веб-сайты, облачные сервисы и приложения
Веб-сайты, облачные сервисы и приложения используют измерение аптайма, чтобы оценить, могут ли пользователи получить доступ к цифровым услугам, когда это необходимо. Сайты электронной коммерции, SaaS-платформы, системы интернет-банкинга, клиентские порталы, стриминговые платформы и бизнес-приложения — все зависят от высокой доступности.
В этих средах простой может вызвать потерю дохода, разочарование клиентов, ущерб репутации и нарушение внутренних рабочих процессов. Мониторинг аптайма помогает организациям быстро обнаруживать проблемы и оценивать, соответствует ли производительность сервиса ожиданиям пользователей.
Для клиентских сервисов аптайм часто является одним из самых заметных признаков надёжности.
Сети, коммуникационные системы и инфраструктура
Аптайм также критически важен в сетях и коммуникационных системах. Маршрутизаторам, коммутаторам, брандмауэрам, IP-АТС платформам, SIP-серверам, шлюзам, диспетчерским системам, переговорным сетям, системам безопасности и платформам мониторинга — всем необходима надёжная работа. Если эти системы откажут, могут пострадать голосовая связь, доступ к данным, сигнализация, контроль доступа и операционная координация.
Аптайм инфраструктуры особенно важен, поскольку от неё зависят многие другие сервисы. Облачное приложение может быть исправно, но если локальная сеть недоступна, пользователи не могут к нему подключиться. Коммуникационная платформа может работать, но при отказе шлюза или транкового пути вызовы могут не завершаться.
Поэтому аптайм инфраструктуры обычно мониторится на нескольких уровнях: от физических устройств до сервисов, ориентированных на пользователя.
Распространённые причины простоев
Технические сбои
К техническим сбоям относятся неисправности оборудования, аварийные завершения программ, утечки памяти, проблемы с базой данных, отказ диска, отказ сетевого оборудования, перерыв в питании, проблемы с охлаждением и исчерпание ресурсов. Это распространённые причины простоев во многих средах.
Некоторые технические сбои происходят внезапно, другие развиваются постепенно. Диск может показывать предупреждения перед отказом. Сервер может начать тормозить перед крашем. Сетевой канал может показывать потерю пакетов до полного отказа. Мониторинг помогает замечать ранние признаки, чтобы команды могли действовать быстрее.
Резервирование, оповещения, планирование ёмкости и профилактическое обслуживание — всё это помогает снизить влияние технических сбоев.
Человеческий фактор и слабость процессов
Человеческая ошибка — ещё одна серьёзная причина простоев. Неправильная команда, случайное удаление, неверно настроенное правило брандмауэра, ошибочный файл прошивки, истёкший сертификат или плохо протестированное обновление могут обрушить сервис. Во многих случаях система отказывает не потому, что оборудование слабое, а потому что слабы операционные процессы.
Средства контроля процессов помогают снизить этот риск. Документирование, контроль доступа, коллегиальная проверка, согласование изменений, резервное копирование, промежуточные среды и планы отката делают человеческие ошибки менее разрушительными. Обучение также важно, так как администраторы должны понимать и систему, и последствия изменений.
Надёжное управление аптаймом рассматривает людей, процессы и технологии как единую систему надёжности.
Как повысить аптайм
Проектируйте с учётом отказов
Повышение аптайма начинается с проектирования с расчётом на отказ. Любой компонент в конечном итоге может отказать. Надёжная система исходит из того, что отказ произойдёт, и включает резервные пути, мониторинг, процедуры восстановления и проверенное поведение при аварийном переключении.
Такой подход меняет образ мышления при проектировании. Вместо вопроса «откажет ли этот компонент?» команда спрашивает: «что произойдёт, когда он откажет?». Если ответ заключается в том, что весь сервис остановится, дизайн, возможно, нуждается в улучшении. Если ответ — трафик переключится на резервный путь и пользователи продолжат работать, система более устойчива.
Проектирование с учётом отказов — один из ключевых принципов, лежащих в основе высокого аптайма.
Измеряйте то, что реально ощущают пользователи
Улучшение аптайма должно фокусироваться на пользовательском опыте, а не только на внутреннем состоянии. Панель управления сервером может показывать, что процесс выполняется, но пользователи всё равно могут не иметь возможности войти в систему, совершать вызовы, открывать файлы или завершать транзакции. Поэтому мониторинг должен по возможности включать сквозные проверки сервиса.
Измерение, ориентированное на пользователя, помогает выявить проблемы, которые могут упустить проверки на уровне компонентов. Оно также помогает организациям понять реальное влияние простоя на бизнес. Если пользователи не могут завершить сервисную задачу, система с их точки зрения не является по-настоящему доступной.
Лучшие программы управления аптаймом измеряют как техническое здоровье, так и поведение сервиса, ориентированное на пользователя.
Заключение
Аптайм — это мера того, как долго система, устройство, сервис или платформа остаётся работоспособной и доступной. Это ключевой показатель надёжности веб-сайтов, облачных платформ, сетей, коммуникационных систем, дата-центров, промышленной инфраструктуры и бизнес-приложений. Высокий аптайм означает, что пользователи могут положиться на сервис, когда он им нужен.
Аптайм работает путём отслеживания времени доступности сервиса и сравнения его с общим измеренным временем. На него влияют надёжность оборудования, сетевая связность, стабильность питания, качество программного обеспечения, архитектура системы, мониторинг, обслуживание и операционная дисциплина. Надёжный аптайм обычно требует резервирования, аварийного переключения, профилактического обслуживания, контролируемых изменений и реалистичного мониторинга сервиса.
С практической точки зрения, аптайм — это не просто процент. Это отражение того, насколько хорошо система была спроектирована, эксплуатировалась, мониторилась и обслуживалась для поддержки реальных пользователей и реальных бизнес-потребностей.
Часто задаваемые вопросы (FAQ)
Что означает аптайм простыми словами?
Простыми словами, аптайм означает количество времени, в течение которого система или услуга работает и доступна для использования. Если веб-сайт, сервер, сеть или устройство работает нормально, этот период считается аптаймом.
Этот показатель обычно используется для измерения надёжности.
Как рассчитывается аптайм?
Аптайм обычно рассчитывается путём сравнения времени, когда система была доступна, с общим временем за период измерения. Результат часто отображается в процентах, например, аптайм 99,9%.
Точный расчёт зависит от того, как определяются доступность и время простоя.
Почему аптайм важен?
Аптайм важен, потому что пользователи и компании зависят от систем, которые должны быть доступны, когда это необходимо. Плохой аптайм может привести к потере производительности, сбоям связи, разочарованию клиентов, перерывам в обслуживании и потере доходов.
Высокий аптайм поддерживает надёжность, непрерывность бизнеса и доверие пользователей.