HTTP, или протокол передачи гипертекста, — это протокол прикладного уровня, используемый для передачи веб-страниц, данных API, файлов, форм, изображений, сценариев и других ресурсов между клиентами и серверами. Он является основой World Wide Web и одним из самых распространённых коммуникационных протоколов в современных интернет-системах.
Когда пользователь открывает сайт, нажимает ссылку, отправляет форму, загружает изображение или вызывает API, HTTP определяет, как клиент запрашивает ресурс и как сервер отвечает. Сам протокол не решает, как будет выглядеть страница или как будет работать приложение. Его главная роль — предоставить структурированный способ обмена данными между двумя сторонами.
Диалог запроса и ответа
Базовый принцип прост: клиент отправляет запрос, а сервер возвращает ответ. Клиентом обычно является веб-браузер, мобильное приложение, настольная программа, инструмент API, поисковый робот или встраиваемое устройство. Сервер — это система, на которой размещён запрошенный ресурс или сервис.
Например, когда браузер посещает сайт, он отправляет запрос на конкретную страницу. Сервер получает запрос, проверяет, какой ресурс запрашивается, обрабатывает связанные правила и возвращает ответ, содержащий контент, сведения о состоянии и метаданные.
Эта модель называется обменом «запрос-ответ». Клиент начинает обмен, а сервер отвечает. Каждый обмен имеет структуру, чтобы обе стороны понимали, что запрашивается, как это должно быть обработано и какой результат возвращается.

До передачи первого байта
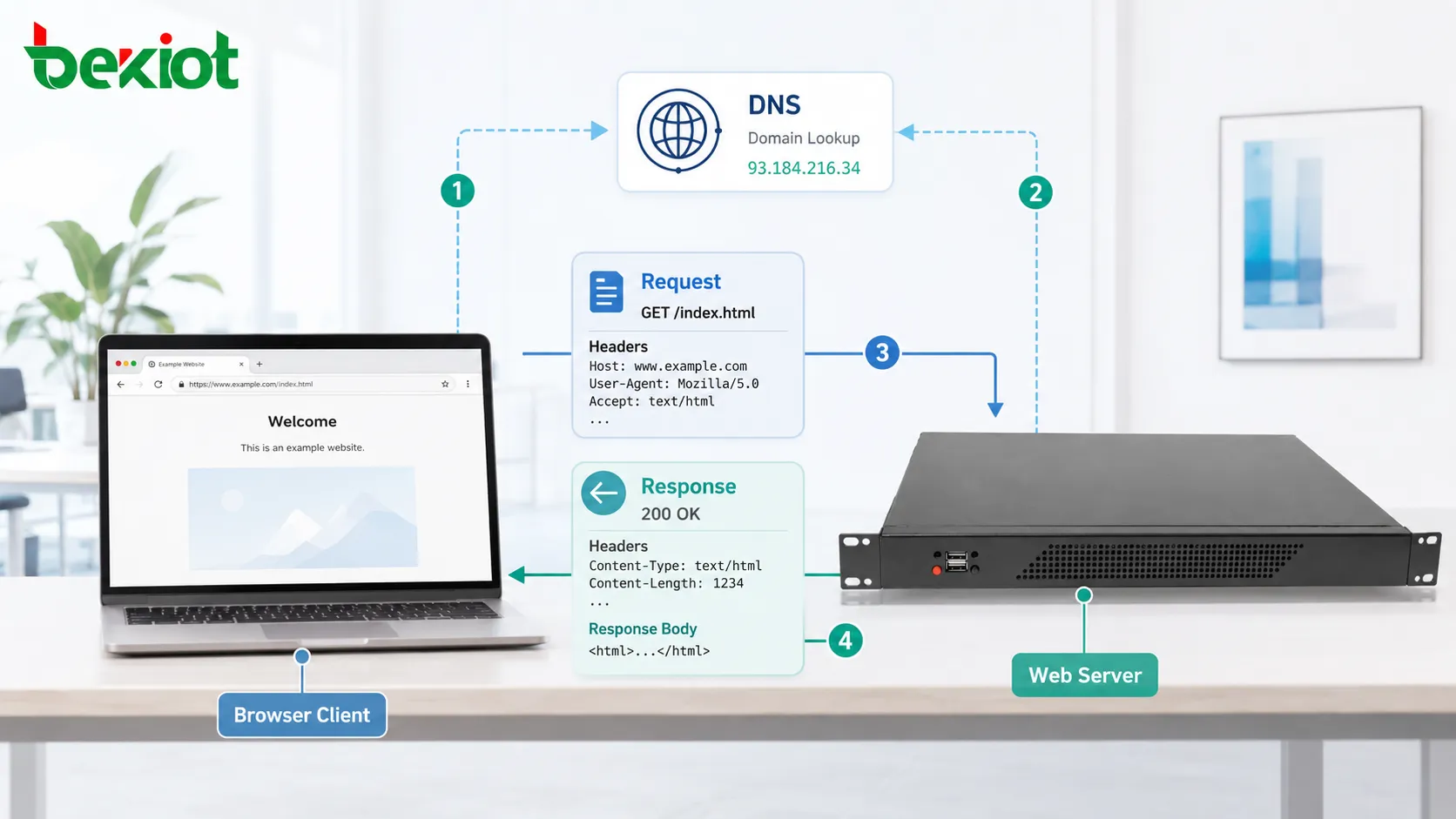
Прежде чем HTTP-запрос сможет попасть на сервер, клиент должен знать, куда его отправлять. Когда пользователь вводит доменное имя, браузер обычно сначала выполняет DNS-разрешение. DNS переводит понятное человеку доменное имя в IP-адрес.
После этого клиент устанавливает сетевое соединение с сервером. В традиционном HTTP поверх TCP это означает открытие TCP-соединения. В HTTPS дополнительно выполняется TLS-рукопожатие, чтобы связь могла быть зашифрована и аутентифицирована.
Только после этих шагов может быть передано собственно HTTP-сообщение. Поэтому загрузка веб-страницы зависит не только от сообщения протокола. Она также зависит от DNS, транспортного соединения, шифрования, доступности сервера, маршрутизации и производительности сети.
Структура клиентского запроса
HTTP-запрос обычно содержит метод, целевой путь, версию, заголовки и иногда тело сообщения. Метод объясняет предполагаемое действие. Путь идентифицирует ресурс. Заголовки предоставляют дополнительную информацию. Тело передаёт отправляемые данные, когда это необходимо.
Простой запрос может попросить главную страницу. Более сложный запрос может отправить учётные данные для входа, загрузить файл, отправить JSON-данные в API или запросить кэшированный ресурс только при его изменении.
К распространённым методам запросов относятся GET, POST, PUT, PATCH, DELETE, HEAD и OPTIONS. Каждый метод имеет своё значение и должен применяться в соответствии с целью операции.
GET обычно используется для получения данных. POST часто используется для отправки данных. PUT и PATCH применяются для обновления ресурсов. DELETE используется для запроса удаления. HEAD запрашивает заголовки ответа без полного тела. OPTIONS проверяет поддерживаемые варианты связи.
Как сервер интерпретирует сообщение
Получив запрос, сервер читает метод, путь, заголовки, тело, cookies, данные аутентификации и правила маршрутизации. Затем он решает, что должно произойти.
Если запрос относится к статическому файлу, сервер может вернуть файл напрямую. Если запрос относится к динамической странице или конечной точке API, сервер может вызвать код приложения, обратиться к базе данных, проверить права пользователя, выполнить бизнес-логику или связаться с другим сервисом.
Сервер также может применить правила безопасности до возврата данных. Он может проверить, аутентифицирован ли запрос, есть ли у пользователя разрешение, не имеет ли запрос неверный формат, не заблокирован ли источник и не превышены ли ограничения частоты.
Итоговый результат упаковывается в HTTP-ответ.
Структура и значение ответа
HTTP-ответ обычно содержит код состояния, заголовки и необязательное тело. Код состояния сообщает клиенту, был ли запрос успешным, завершился ли ошибкой, был ли перенаправлен или требует дальнейшего действия.
Заголовки описывают ответ. Они могут включать тип содержимого, длину содержимого, правила кэширования, cookies, сведения о сервере, метод сжатия, политику безопасности и адрес перенаправления.
Тело содержит фактически возвращаемый контент. Это может быть HTML, JSON, XML, данные изображения, видеосегменты, текстовые файлы, таблицы стилей, сценарии или бинарные загрузки.
Браузер использует тело ответа и заголовки, чтобы решить, что отображать, что кэшировать, что выполнять, что скачивать и нужны ли дополнительные запросы.
Коды состояния как дорожные сигналы
Коды состояния помогают клиентам быстро понять результат. Они сгруппированы по категориям.
| Диапазон кодов | Общее значение | Пример использования |
|---|---|---|
| 100-199 | Информационный ответ | Продолжение обработки или уведомление уровня протокола |
| 200-299 | Успешный ответ | Страница загружена, API вернул данные, файл доставлен |
| 300-399 | Перенаправление | Ресурс перемещён или клиент должен запросить другой URL |
| 400-499 | Ошибка на стороне клиента | Неверный запрос, несанкционированный доступ, отсутствующий ресурс |
| 500-599 | Ошибка на стороне сервера | Сбой приложения, ошибка шлюза, перегрузка сервера |
Ответ 200 обычно означает, что запрос выполнен успешно. Ответ 301 или 302 означает, что клиент должен перейти в другое место. Ответ 404 означает, что запрошенный ресурс не найден. Ответ 500 означает, что сервер столкнулся с внутренней проблемой.
Коды состояния предназначены не только для браузеров. Клиенты API, системы мониторинга, поисковые роботы, прокси и балансировщики нагрузки также используют их для принятия решений.
Заголовки передают контекст
Заголовки — это поля «ключ-значение», которые передают контекст обмена. Они помогают обеим сторонам описывать формат данных, языковые предпочтения, сжатие, аутентификацию, поведение кэша, cookies, поведение соединения и требования безопасности.
Например, заголовок Accept может сообщить серверу, какие типы содержимого предпочитает клиент. Заголовок Content-Type сообщает получателю, какой формат использует тело. Заголовок Authorization может переносить учётные данные или токены. Заголовок Cache-Control определяет поведение кэширования.
Заголовки делают протокол гибким. Одна и та же модель «запрос-ответ» может поддерживать сайты, API, загрузку файлов, потоковые сегменты, процессы аутентификации и интеграцию сервисов, потому что заголовки добавляют инструкции без изменения базовой структуры сообщения.
Бессостояние и обработка сессий
HTTP часто описывают как протокол без состояния. Это означает, что каждый запрос по умолчанию независим. Сервер не запоминает автоматически предыдущие запросы как часть базовой модели протокола.
Однако большинству реальных сайтов и приложений нужно сессионное поведение. Пользователи входят в систему, добавляют товары в корзину, меняют настройки и продолжают рабочие процессы через множество запросов. Для этого системы используют cookies, идентификаторы сессий, токены, локальное хранилище, серверные сессии и заголовки аутентификации.
Протокол остаётся основанным на запросах, но приложения строят поверх него непрерывность. Поэтому сайт может помнить пользователя, хотя базовый обмен всё ещё состоит из отдельных запросов и ответов.
Идентификация ресурсов с помощью URL
URL сообщает клиенту, где находится ресурс и как его запросить. Обычно он включает схему, хост, путь, строку запроса и иногда порт или фрагмент.
Схема может быть http или https. Хост идентифицирует домен. Путь указывает на конкретный ресурс или маршрут. Строка запроса переносит дополнительные параметры. Фрагмент обычно обрабатывается на стороне клиента и не должен отправляться на сервер так же, как основной путь запроса.
URL делает веб-ресурсы адресуемыми. Он позволяет браузерам, API, поисковым системам, приложениям и пользователям ссылаться на ресурсы в едином формате.
Что происходит при загрузке веб-страницы
Одна загрузка страницы может включать множество HTTP-обменов. Первый запрос может получить основной HTML-документ. После чтения документа браузер обнаруживает дополнительные ресурсы: CSS-файлы, JavaScript-файлы, изображения, шрифты, значки, аналитические сценарии, вызовы API и медиафайлы.
Каждый ресурс может потребовать отдельного запроса. Некоторые ресурсы могут поступать с того же сервера, другие — из CDN, сторонних сервисов, рекламных систем, картографических провайдеров или API-шлюзов.
Затем браузер объединяет полученные ресурсы, строит структуру страницы, применяет стили, выполняет сценарии и отображает итоговый визуальный интерфейс. Поэтому за одним видимым действием могут стоять десятки или даже сотни протокольных обменов.
Кэширование и повышение производительности
Кэширование позволяет клиентам, браузерам, прокси, CDN и серверам повторно использовать ранее загруженные ресурсы, когда это уместно. Это сокращает повторную передачу данных, снижает задержку, экономит пропускную способность и улучшает пользовательский опыт.
Поведение кэша управляется заголовками Cache-Control, ETag, Last-Modified и Expires. Эти заголовки помогают определить, можно ли использовать ресурс повторно, нужно ли его перепроверить или следует скачать заново.
Для статических файлов, таких как изображения, сценарии и таблицы стилей, кэширование может значительно сократить время загрузки. Для динамических данных кэширование нужно применять осторожно, поскольку устаревший контент может привести к неверным результатам.
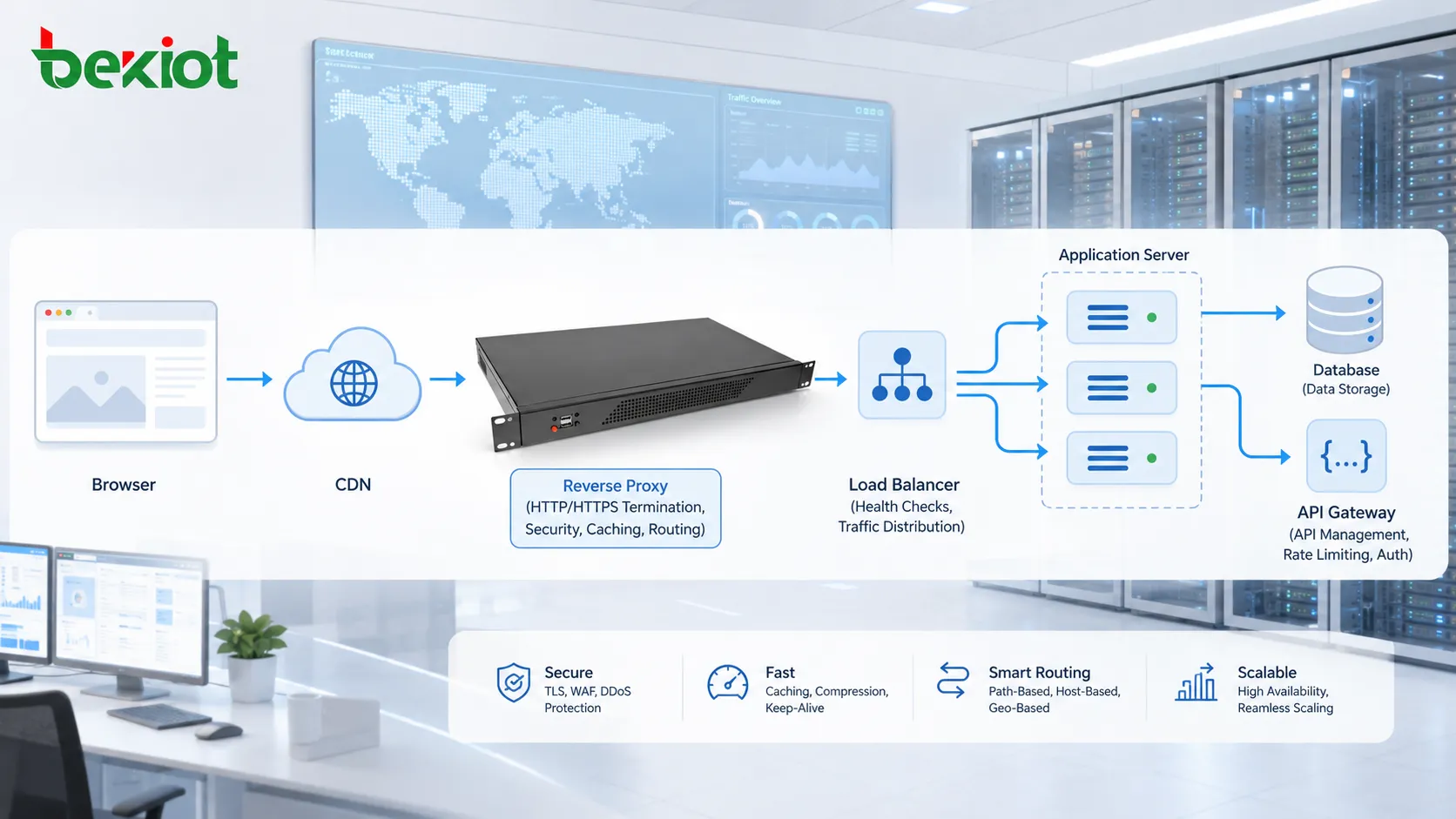
Роль прокси, шлюзов и CDN
HTTP-трафик не всегда проходит напрямую от браузера к исходному серверу. Он может проходить через обратные прокси, прямые прокси, API-шлюзы, балансировщики нагрузки, межсетевые экраны, периферийные узлы CDN или системы проверки безопасности.
Обратный прокси может принимать запросы от имени внутренних серверов. Балансировщик нагрузки может распределять трафик между несколькими серверами приложений. CDN может кэшировать контент ближе к пользователям. API-шлюз может проверять токены, ограничивать частоту запросов, преобразовывать заголовки или направлять трафик к микросервисам.
Эти промежуточные системы повышают масштабируемость, безопасность, производительность и управляемость. Они также усложняют диагностику, поскольку ошибки могут возникать на разных уровнях.
HTTPS и безопасная связь
HTTPS — это HTTP, передаваемый поверх шифрования TLS. Он защищает данные в пути, шифруя связь между клиентом и сервером. Он также помогает проверять идентичность сервера с помощью цифровых сертификатов.
Без шифрования конфиденциальная информация, такая как пароли, токены, персональные данные и сессионные cookies, могла бы быть раскрыта атакующим в сети. HTTPS снижает этот риск и стал обычным стандартом для современных сайтов и API.
Безопасная связь также зависит от правильной настройки сертификатов, сильных версий протокола, безопасных cookies, корректных перенаправлений и безопасных параметров сервера. HTTPS важен, но его нужно настраивать правильно.
Эволюция версий протокола
HTTP развивался для повышения производительности и эффективности. Ранние версии использовали более простую обработку запросов. Поздние версии ввели постоянные соединения, мультиплексирование, сжатие заголовков, идеи server push и улучшенное транспортное поведение.
HTTP/1.1 улучшил повторное использование соединений и получил широкое распространение. HTTP/2 ввёл мультиплексирование, позволяя нескольким запросам и ответам эффективнее использовать одно соединение. HTTP/3 использует QUIC поверх UDP, чтобы улучшить установление соединения и снизить некоторые проблемы задержки при определённых сетевых условиях.
Принцип работы остаётся коммуникацией «запрос-ответ», но транспортные и производительные механизмы стали более продвинутыми.
API и межмашинная коммуникация
HTTP используется не только браузерами. Он также является доминирующим стилем протокола для многих API. Мобильные приложения, веб-приложения, IoT-платформы, облачные сервисы, платёжные системы, инструменты мониторинга и корпоративные системы часто обмениваются данными JSON или XML поверх HTTP.
В API-коммуникации тело ответа может быть не HTML-страницей. Оно может быть структурированными данными для обработки другой программой. Коды состояния, заголовки, токены аутентификации и методы запросов становятся особенно важными для предсказуемой интеграции.
Поэтому разработчикам нужно понимать как базовую рабочую модель, так и практические соглашения, используемые при проектировании API.
Распространённые проблемы и их причины
Медленная страница может быть вызвана задержкой DNS, крупными файлами, плохим кэшированием, перегрузкой сервера, задержкой базы данных, перегрузкой сети, слишком большим числом запросов или неэффективными сценариями.
Ошибка 404 может указывать на отсутствующий файл, неправильный URL, удалённый маршрут, неверное правило перезаписи или битую ссылку. Ошибка 500 может указывать на сбой серверного кода, проблему базы данных, проблему разрешений или неправильно настроенный backend-сервис.
Сбои аутентификации могут быть связаны с истёкшими токенами, отсутствующими cookies, неверными учётными данными, заблокированными настройками cross-origin или неправильной обработкой заголовков.
Понимание пути «запрос-ответ» помогает определить, где возникает проблема.
Практический метод диагностики
Начните с проверки URL и метода запроса. Затем проверьте код состояния. Далее изучите заголовки запроса, заголовки ответа, cookies и тело ответа. Инструменты разработчика в браузере полезны для этого процесса.
Для серверных проблем проверьте журналы доступа, журналы ошибок, журналы приложения, журналы обратного прокси и состояние backend-сервисов. В распределённых системах trace ID и request ID помогают проследить один запрос через несколько сервисов.
Для проблем производительности проверьте время DNS, время соединения, время TLS, время ответа сервера, время загрузки содержимого, поведение кэша и размер ресурсов. Эти детали показывают, связана ли проблема с сетью, сервером или frontend.
Почему эта модель остаётся важной
Принцип работы HTTP остаётся важным, потому что почти каждый современный цифровой сервис зависит от него. Сайты, API, мобильные приложения, облачные панели, платформы управления, платёжные системы, сервисы входа, системы мониторинга и IoT-платформы используют одну базовую идею: запросить, обработать, ответить.
Его сила заключается в простоте, расширяемости, читаемости и широкой совместимости. Он может переносить множество типов контента и поддерживать разные виды приложений, сохраняя единую структуру коммуникации.
В то же время хороший дизайн требует внимания к безопасности, кэшированию, заголовкам, кодам состояния, обработке ошибок, совместимости версий и сетевой архитектуре.
Итоги
HTTP работает так: клиент отправляет структурированный запрос серверу и получает структурированный ответ. Вокруг этой простой модели современные веб-системы добавляют DNS, TLS, кэширование, прокси, CDN, API, аутентификацию, оптимизацию производительности и меры безопасности.
Частые вопросы
HTTP — это то же самое, что HTTPS?
Нет. HTTP определяет модель обмена сообщениями, а HTTPS добавляет TLS-шифрование и проверку личности на основе сертификатов для защиты связи при передаче.
Почему одна веб-страница вызывает много запросов?
Страница обычно зависит от отдельных файлов, таких как изображения, сценарии, таблицы стилей, шрифты, вызовы API и медиа-ресурсы. Браузер запрашивает эти ресурсы после чтения основного документа.
Можно ли использовать HTTP без браузера?
Да. Мобильные приложения, серверы, инструменты командной строки, IoT-устройства, системы мониторинга и API могут использовать HTTP без традиционного веб-браузера.
Почему некоторые вызовы API возвращают данные вместо веб-страниц?
API часто возвращают структурированные данные, такие как JSON или XML. Получающая программа обрабатывает данные, а не отображает их как веб-страницу.
Что нужно проверить первым при сбое HTTP-запроса?
Проверьте URL, метод запроса, код состояния, заголовки, состояние аутентификации, сетевое соединение, серверные журналы и то, не изменяет ли запрос какой-либо прокси или шлюз.