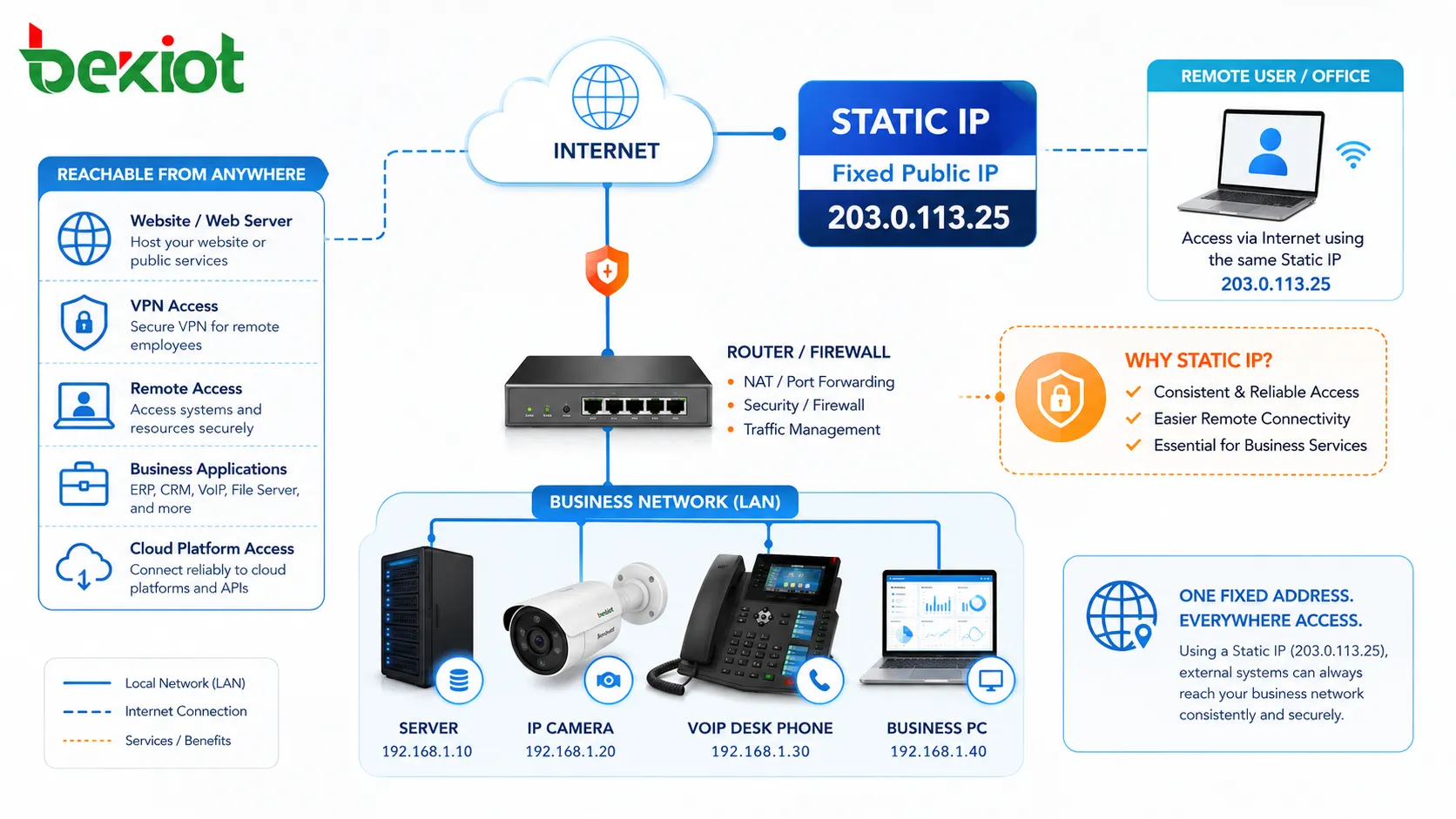
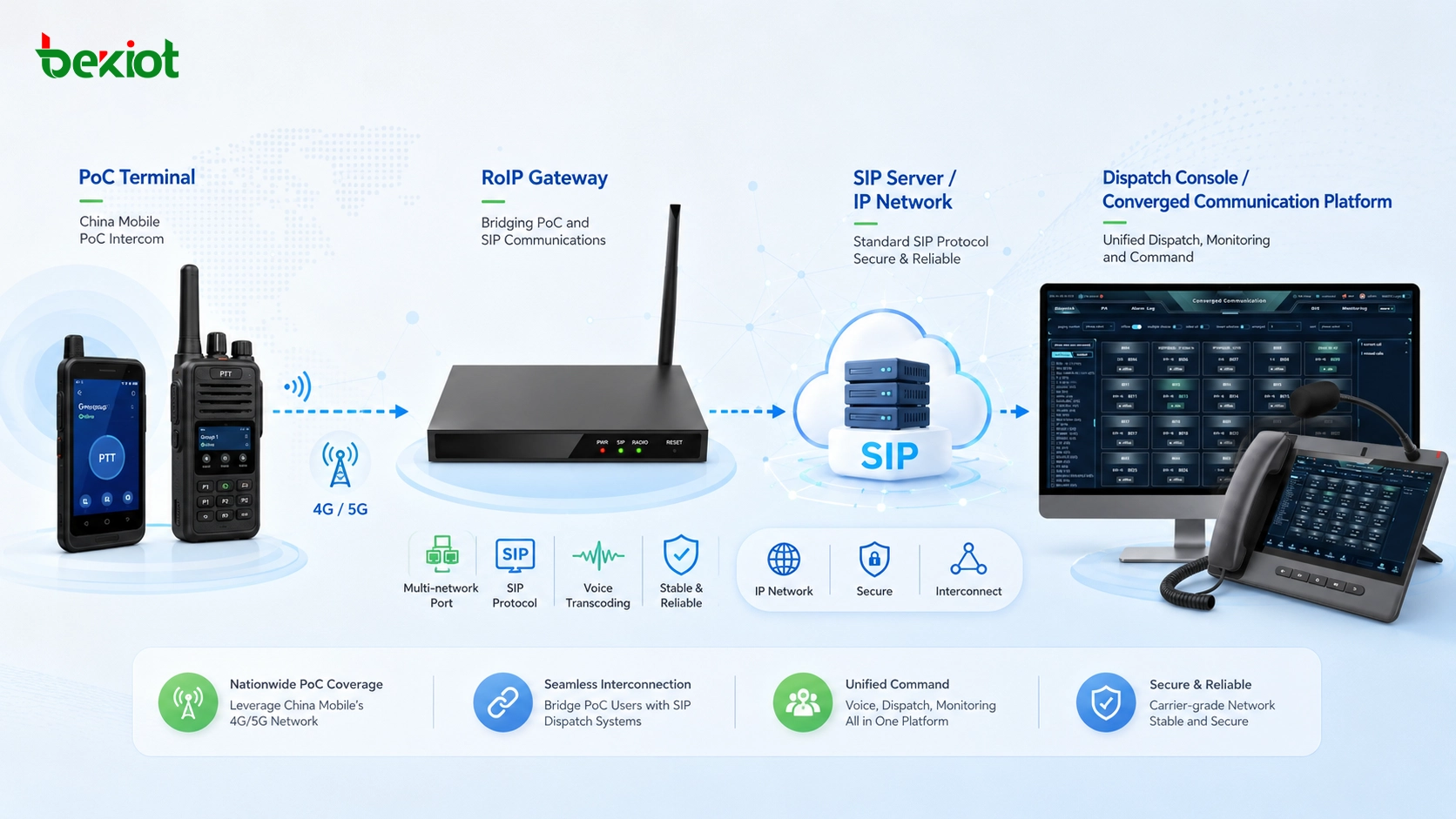
Высокая доступность — это подход к проектированию, при котором система, сервис, приложение или сеть остаются доступными даже при выходе из строя отдельных компонентов. Вместо того чтобы полагаться на один сервер, одну базу данных, один сетевой маршрут, один источник питания или один программный процесс, система с высокой доступностью использует резервирование, мониторинг, аварийное переключение и планирование восстановления для минимизации простоев и сохранения непрерывности обслуживания.
Для компаний и организаций, чья деятельность зависит от цифровых процессов, высокая доступность — это не просто ИТ-концепция. Она влияет на клиентский опыт, эффективность производства, реагирование в чрезвычайных ситуациях, надёжность связи, доступ к данным, работу служб безопасности и соблюдение соглашений об уровне обслуживания. Кратковременный перерыв может быть допустим для внутренней низкоприоритетной утилиты, но совершенно неприемлем для больничной системы, диспетчерской платформы, платёжного шлюза, сети промышленного управления, публичного сервиса связи или облачного приложения, которым пользуются тысячи людей.
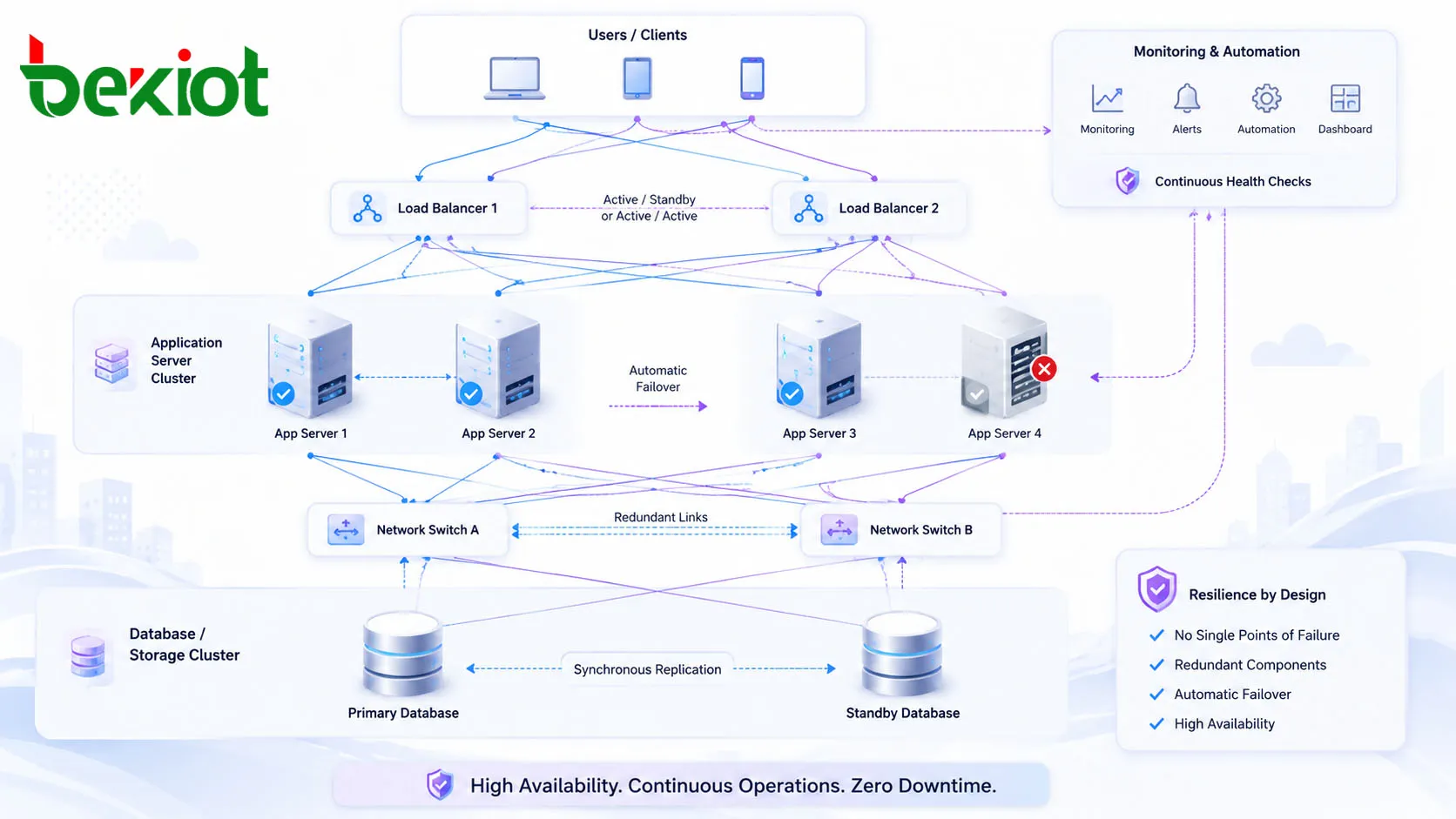
Значение в практическом проектировании систем
Высокая доступность, часто обозначаемая аббревиатурой HA (High Availability), означает способность системы оставаться работоспособной на протяжении высокой доли времени. Обычно её обсуждают через целевые показатели времени безотказной работы, такие как 99,9 %, 99,99 % или 99,999 %. Однако доступность не сводится лишь к тому, включён ли сервер. Система по-настоящему доступна только тогда, когда пользователи могут выполнять нужные им действия: совершить звонок, провести транзакцию, открыть приложение, получить уведомление о тревоге, синхронизировать записи или обратиться к оперативной информации.
Надёжный сервис зависит от всей сервисной цепочки. Она может включать вычислительные ресурсы, системы хранения, движки баз данных, сетевые коммутаторы, межсетевые экраны, DNS, службы идентификации, сертификаты безопасности, прикладные процессы, средства мониторинга, резервные каналы связи, инфраструктуру электропитания и операционные процедуры. Если у критической зависимости нет резервного пути, весь сервис может остаться уязвимым.
Высокая доступность также отличается от обычного резервного копирования. Резервная копия помогает восстановить данные после сбоя, но она может не обеспечить работу сервиса во время самого сбоя. HA ориентируется на непрерывность. Она позволяет другому узлу, маршруту, экземпляру сервиса или площадке взять на себя нагрузку до того, как пользователи столкнутся с длительным перерывом.
Почему организации строят системы с прицелом на непрерывность
Ценность высокой доступности становится очевидной, когда простой оборачивается реальными последствиями. В электронной коммерции это потерянные заказы и сбои платежей. В телекоммуникациях — пропущенные звонки, недоступные добавочные номера или прерванная маршрутизация экстренных вызовов. На производстве это может остановить технологические цепочки. В здравоохранении и общественной безопасности — задержать связь, координацию и реагирование.
Доступность также оберегает доверие. Клиенты, сотрудники, партнёры и выездные бригады рассчитывают, что современные системы будут доступны в любое время. Если платформа периодически уходит в офлайн, пользователи могут потерять уверенность, даже если каждый перерыв короток. Для поставщиков услуг и корпоративных платформ стабильное время безотказной работы — часть общего пользовательского опыта.
Ещё одна причина — операционный контроль. Без планирования HA технические специалисты часто полагаются на экстренную диагностику уже после того, как сбой затронул пользователей. При наличии резервирования, автоматических проверок состояния, логики переключения и чётких процедур обработки инцидентов сбои становятся управляемыми событиями, а не неожиданными кризисами.
Высокодоступная система не исходит из того, что отказов не будет. Она исходит из того, что они неизбежны, и заранее готовит сервис к продолжению работы в случае их возникновения.
Ключевые характеристики, обеспечивающие надёжную работу
Резервная инфраструктура
Резервирование — это фундамент высокой доступности. Критически важные компоненты дублируются, чтобы при выходе из строя активного компонента работу продолжал другой. Резервирование может охватывать несколько серверов, кластеризованные узлы приложений, зеркальное хранилище, реплицированные базы данных, двойные блоки питания, резервные маршрутизаторы, дублирующие коммутаторы, несколько подключений к интернету и развёрнутые в разных локациях копии сервисов.
Эффективное резервирование должно покрывать реальный сервисный тракт. Два сервера приложений не обеспечивают полную защиту, если оба зависят от одной базы данных, одного дискового массива, одного межсетевого экрана, одной цепи питания или одного внешнего провайдера. При планировании HA необходимо проанализировать каждую зависимость, без которой сервис не сможет функционировать.
Автоматическое аварийное переключение
Аварийное переключение (failover) — это процесс передачи обслуживания от отказавшего компонента к исправному. Во многих HA-решениях этот процесс происходит автоматически. Например, балансировщик нагрузки может исключить неработоспособный сервер из пула, резервная база данных — стать основной, а запасной сетевой маршрут — перехватить трафик при обрыве основного канала.
Автоматическое переключение сокращает время восстановления, потому что не требует ожидания, пока инженер вручную диагностирует неисправность. Однако логику переключения необходимо проектировать тщательно. Если проверки состояния слишком примитивны, система может переключаться без необходимости. Если правила срабатывают чересчур медленно, пользователи могут столкнуться с более долгим простоем, чем планировалось.
Мониторинг работоспособности сервиса
Мониторинг позволяет системе и эксплуатационной команде заблаговременно выявлять аномальные состояния. Эффективный мониторинг охватывает состояние серверов, использование процессора и памяти, дисковое пространство, время отклика сервиса, репликацию баз данных, сетевую задержку, потери пакетов, завершение вызовов, долю успешных транзакций, истечение срока действия сертификатов, статус резервного копирования и события безопасности.
Наиболее полезные проверки здоровья привязаны к реальному поведению сервиса. Устройство может отвечать на ping, в то время как приложение зависло. Веб-сервер может работать, хотя соединение с базой данных разорвано. Коммуникационный сервер может быть в сети, тогда как маршрутизация вызовов не работает. Мониторинг должен подтверждать, действительно ли сервис пригоден к использованию.
Распределение нагрузки
Балансировка нагрузки распределяет трафик между несколькими серверами или экземплярами сервиса. Это повышает производительность в штатном режиме и поддерживает непрерывность при возникновении неисправностей. Если один узел перегружается или становится недоступным, трафик может быть переведён на другие исправные узлы.
Балансировка нагрузки широко применяется для веб-сайтов, API, облачных приложений, коммуникационных платформ, служб аутентификации и внутренних корпоративных систем. В зависимости от исполнения она может поддерживать сохранение сессий, географическую маршрутизацию, маршрутизацию по состоянию узла или интеллектуальное управление трафиком с учётом особенностей приложения.
Репликация данных
Многие системы не могут оставаться доступными, если недоступны данные. Репликация данных поддерживает копии важной информации на нескольких узлах или площадках. Это позволяет вторичному серверу, системе хранения или центру обработки данных продолжить обслуживание в случае отказа основной среды.
Репликация бывает синхронной и асинхронной. Синхронная репликация подтверждает запись только после фиксации данных более чем в одном месте; это может повысить согласованность, но способно увеличить задержку. Асинхронная репликация обычно быстрее, однако небольшой объём самых свежих данных может быть потерян при внезапном сбое. Правильный выбор зависит от требуемого баланса между производительностью, консистентностью и допустимым объёмом потери данных.
Обслуживание без полной остановки
Продуманная HA-архитектура помогает и во время планового технического обслуживания. Системы нуждаются в обновлениях, установке исправлений безопасности, замене оборудования, продлении сертификатов, изменении конфигураций и расширении ёмкости. Если архитектура поддерживает плавающие обновления или контролируемое переключение, обслуживание можно провести, не отключая сервис целиком.
Это особенно ценно для сервисов, работающих круглосуточно. Вместо ожидания длинных технологических окон команды могут обновлять узлы по очереди, пока остальные продолжают обрабатывать пользовательскую нагрузку.
Распространённые архитектурные шаблоны
Активный-резервный (Active-Standby)
В схеме «активный-резервный» одна система обрабатывает промышленный трафик, а другая остаётся в готовности взять управление на себя. Эта модель часто применяется для межсетевых экранов, баз данных, офисных АТС, шлюзов, промышленных приложений и центральных платформ управления.
Преимущество такой архитектуры — простота и предсказуемое поведение при переключении. Недостаток — резервные ресурсы в нормальном режиме могут использоваться не полностью. Кроме того, резервную систему необходимо регулярно тестировать, чтобы убедиться, что она синхронизирована и готова к работе.
Активный-активный (Active-Active)
В схеме «активный-активный» несколько систем одновременно обрабатывают трафик. Если один узел выходит из строя, остальные продолжают работу и принимают нагрузку на себя. Такая модель способна повысить как доступность, так и производительность, поскольку мощности используются непрерывно.
Активно-активная архитектура обычно требует более тщательной проработки. Приложения должны корректно работать с распределёнными сессиями, согласованностью данных, поведением маршрутизации и возможными конфликтными ситуациями. Если программное обеспечение не рассчитано на распределённую работу, внедрение active-active может породить сложность вместо надёжности.
Кластерные сервисы
Кластер — это группа узлов, работающих как единый сервис. Кластерные системы способны защищать приложения, базы данных, виртуальные машины, платформы хранения, контейнерные нагрузки и службы связи. Менеджеры кластера отслеживают состояние узлов и координируют переключение либо перераспределение рабочей нагрузки.
Устойчивая кластеризация требует корректной работы heartbeat-сообщений, правил кворума, механизмов изоляции (fencing) и сетевой сегментации. Эти меры помогают избежать ситуации «расщеплённого мозга» (split-brain), когда два узла ошибочно считают себя главными.
Размещение на нескольких площадках
При повышенных требованиях к отказоустойчивости системы могут размещаться в нескольких географических локациях — разных дата-центрах, облачных зонах доступности или регионах. Если одна площадка становится недоступной из-за перебоя с питанием, сетевой аварии, физического повреждения или крупного инфраструктурного инцидента, обслуживание продолжает другая площадка.
Мультисайтовая архитектура сложнее локального резервирования. Она требует управления трафиком, защищённых каналов связи, продуманной репликации, единообразной конфигурации, координации эксплуатационных служб и регулярных учений по аварийному восстановлению. Также необходимы чёткие правила переключения трафика между площадками.
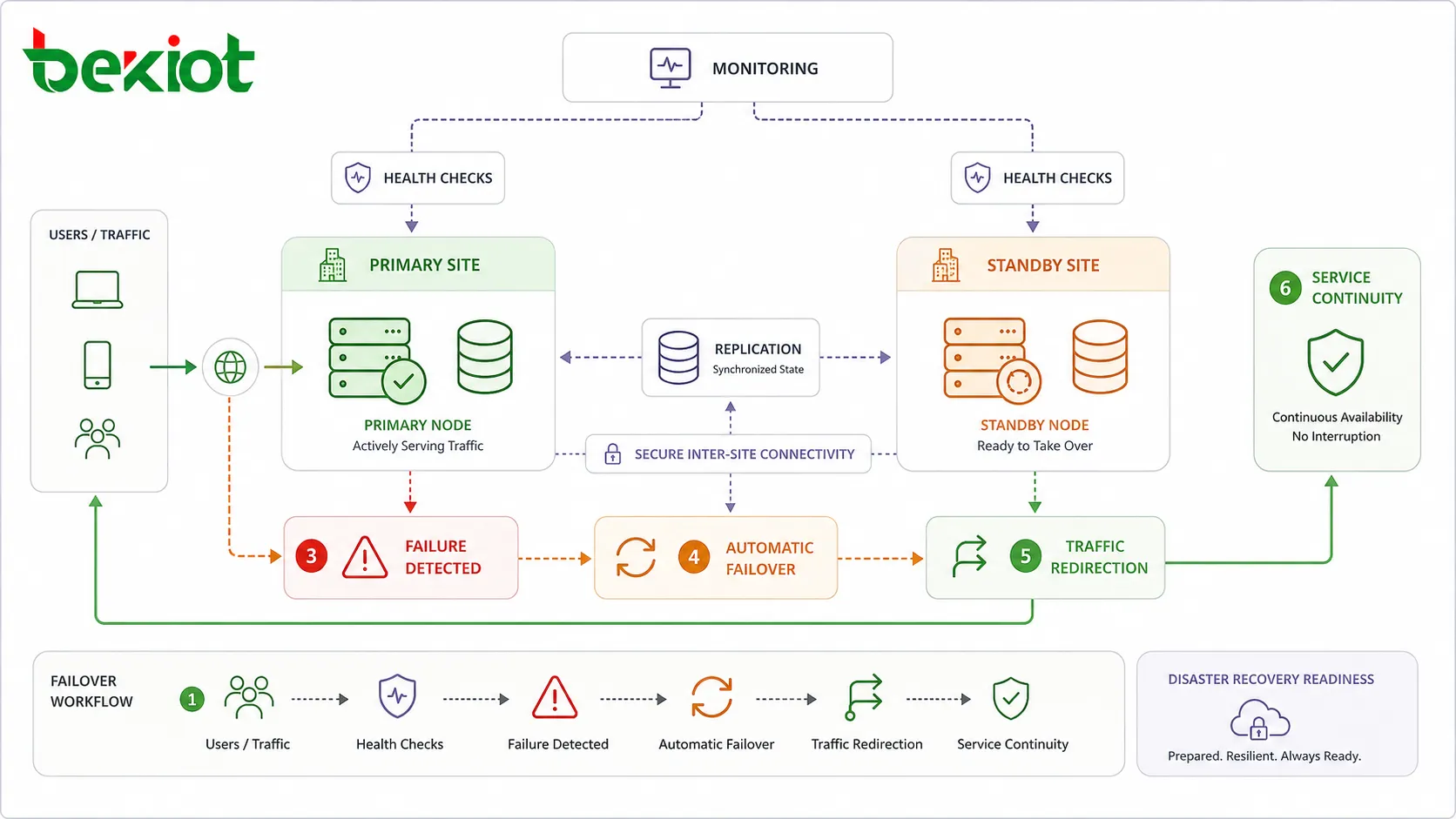
Показатели, используемые для измерения непрерывности сервиса
Процент безотказной работы (Uptime)
Процент безотказной работы показывает, как долго система оставалась работоспособной за определённый период. Он часто фигурирует в соглашениях об уровне обслуживания и внутренних целях по надёжности. Более высокие целевые показатели требуют более крепкой архитектуры, быстрого восстановления, качественного мониторинга и строгой эксплуатационной дисциплины.
Однако uptime следует измерять с точки зрения пользователя. Система, которая технически запущена, но не может обрабатывать запросы, завершать вызовы, предоставлять доступ к данным или отвечать в допустимые сроки, не должна считаться полностью доступной.
Целевое время восстановления (RTO)
Целевое время восстановления (Recovery Time Objective, RTO) определяет, как быстро сервис должен быть восстановлен после перерыва. Короткий RTO обычно требует автоматического переключения, готового к немедленному использованию резерва, отработанных процедур и быстрого обнаружения.
RTO должно соответствовать бизнес-влиянию. Не каждой системе требуется мгновенное восстановление. Некоторые внутренние инструменты могут допускать более длительное восстановление, в то время как критически важные сервисы могут требовать практически непрерывной работы.
Целевая точка восстановления (RPO)
Целевая точка восстановления (Recovery Point Objective, RPO) определяет, какой объём потери данных допустим после сбоя. Низкий RPO требует частой или непрерывной репликации. Более высокий RPO позволяет восстанавливаться из регламентных резервных копий.
RPO имеет значение для журналов транзакций, записей вызовов, истории событий, производственных данных, информации о пользователях, аудиторских следов и оперативной отчётности. Если потеря данных недопустима, требования к репликации и резервному копированию должны быть строже.
Среднее время восстановления (MTTR)
Среднее время восстановления (Mean Time to Repair, MTTR) показывает, сколько уходит времени на возврат к нормальной работе после отказа. Высокая доступность улучшается при снижении MTTR. Лучшая автоматизация, более чёткая документация, обученные операторы, наличие запасных ресурсов и отработанные планы восстановления — всё это способствует сокращению времени ремонта.
Сокращение времени восстановления зачастую реалистичнее, чем попытки предотвратить любой возможный отказ. Даже хорошо спроектированные системы рано или поздно отказывают, но подготовленная организация способна восстановиться быстрее и с меньшими последствиями для пользователей.
Применение в реальных средах
Облачные платформы и SaaS-приложения
Облачные сервисы и SaaS-платформы используют HA-проектирование, чтобы приложения оставались доступными для пользователей из разных мест и часовых поясов. В числе распространённых техник — группы автомасштабирования, балансировщики нагрузки, реплицированные базы данных, распределённое объектное хранилище, проверки работоспособности, резервные регионы и стратегия плавающих развёртываний.
Для подписных сервисов доступность напрямую влияет на удержание клиентов и репутацию бренда. Пользователи могут не знать деталей архитектуры, но они сразу замечают медленные отклики, ошибки входа, отсутствие данных или перебои в обслуживании.
Корпоративные коммуникационные системы
Системы голосовой и видеосвязи, обмена сообщениями, персонального вызова и диспетчеризации часто требуют высокой доступности, поскольку связь бывает нужна и в рутинной работе, и при критических инцидентах. Планирование HA может включать резервные серверы обработки вызовов, дублирующие SIP-транки, вторичные шлюзы, отказоустойчивые сетевые маршруты, локально выживаемые филиальные системы и резервное питание.
Доступность связи необходимо проверять от конечной точки до конечной точки. Недостаточно, чтобы сервер был в сети, если телефоны не могут зарегистрироваться, вызовы не маршрутизируются, голос не проходит через сеть или до экстренных номеров невозможно дозвониться.
Промышленные и энергетические объекты
Промышленные площадки, коммунальные предприятия, горные разработки, порты, транспортные узлы и объекты энергетики часто зависят от непрерывного мониторинга и связи. В этих средах высокая доступность может включать резервные оптоволоконные кольца, дублирующие беспроводные каналы, сдвоенные серверы управления, локальную живучесть, защищённое оборудование и изолированные аварийные линии связи.
При проектировании необходимо учитывать не только ИТ-отказы, но и физические условия. Агрессивная среда, электромагнитные помехи, удалённое расположение, нестабильность электропитания и ограниченный доступ для обслуживания — всё это может влиять на доступность.
Здравоохранение и экстренные службы
Больницы, центры экстренного реагирования, органы общественной безопасности и командные пункты опираются на надёжные системы координации. Высокая доступность может обеспечивать доступ к информации о пациентах, сигнализацию тревог, экстренную связь, рабочие процессы диспетчеризации, контроль доступа, видеонаблюдение и внутреннее взаимодействие.
В этих средах простой — не просто техническая неполадка. Он способен повлиять на скорость реакции, безопасность, принятие решений и непрерывность оказания помощи. Резервное питание, дублированные сети, ясные процедуры эскалации и регулярные тренировки здесь особенно важны.
Финансы, розничная торговля и онлайн-транзакции
Банки, платёжные системы, торговые платформы и интернет-магазины нуждаются в надёжных системах для защиты транзакций и клиентского доступа. Даже короткие перебои могут привести к непроведённым платежам, упущенным продажам, задержке заказов, проблемам с расчётами или жалобам клиентов.
Эти системы часто совмещают планирование доступности с усиленными мерами безопасности, аудиторским журналированием, мониторингом мошенничества, шифрованием и комплаенс-контролем. Непрерывность обслуживания должна проектироваться в единстве с целостностью данных и управлением рисками.
Рекомендации по проектированию перед внедрением
Составьте карту всей цепочки зависимостей
Первый шаг — понять, как сервис работает на самом деле. Команды должны описать приложения, базы данных, сети, системы хранения, аутентификацию, DNS, межсетевые экраны, сторонние сервисы, сертификаты, средства мониторинга и зоны эксплуатационной ответственности. Это помогает выявить скрытые зависимости, которые могут стать едиными точками отказа.
Карта сервиса также помогает определить, какие компоненты нуждаются в резервировании, а какими рисками можно пренебречь. Не каждая зависимость требует одинакового уровня защиты, но любая критическая зависимость должна быть на виду.
Установите реалистичные цели восстановления
Целевые показатели доступности должны определяться потребностями бизнеса, а не маркетинговыми лозунгами. Критичная платформа может оправдать дорогостоящее резервирование и практически мгновенную репликацию. Низкоприоритетный отчётный инструмент может обходиться регламентным копированием и ручным восстановлением.
Чёткие цели по RTO и RPO помогают выбрать верную архитектуру. Они также позволяют избежать как избыточного усложнения систем, которым не нужна глубокая защита, так и недостаточной защиты сервисов, жизненно важных для деятельности.
Тестируйте переключение в контролируемых условиях
План аварийного переключения ценен лишь в том случае, если он срабатывает, когда это необходимо. Контролируемые тесты проверяют, выявляет ли мониторинг отказ, корректно ли активируются резервные ресурсы, правильно ли перенаправляется трафик, остаётся ли информация согласованной и могут ли пользователи продолжать работу.
Тестирование должно охватывать плановое переключение, имитацию отказа узла, изоляцию сети, восстановление из резервной копии, восстановление базы данных и процедуры отката. Результаты следует документировать, чтобы будущие улучшения опирались на факты, а не на предположения.
Контролируйте изменения конфигурации
Многие простои вызваны человеческими ошибками, а не отказом оборудования. Неверные правила межсетевого экрана, истёкшие сертификаты, несовместимые обновления, ошибочные изменения маршрутизации, проблемы с правами в базе данных и несогласованность конфигураций — всё это способно прервать обслуживание.
Контроль изменений, версионирование, согласующие процедуры, тестовые окружения, планы отката и резервные копии конфигураций снижают этот риск. В HA-средах и основная, и резервная системы должны оставаться синхронизированными.
Проблемы и ограничения
Высокая доступность сокращает простои, но не делает систему абсолютно безотказной. Программные ошибки, программы-вымогатели, ошибки конфигурирования, повреждение данных, отказ внешних зависимостей, региональные катастрофы и ошибки операторов по-прежнему могут нарушить работу сервиса. HA должна работать в связке с резервным копированием, кибербезопасностью, аварийным восстановлением, наблюдаемостью и реагированием на инциденты.
Стоимость — ещё один вызов. Резервированная архитектура может потребовать больше серверов, сетевого оборудования, облачных ресурсов, лицензий, систем мониторинга, дискового пространства и эксплуатационных компетенций. Чем выше планка доступности, тем важнее обосновать инвестиции.
Сложность тоже способна превратиться в риск. Запутанная HA-конструкция, которую эксплуатационная команда не понимает до конца, может подвести во время инцидента. Практичная высокая доступность должна быть задокументирована, пригодна для тестирования и посильна для управления теми, кто отвечает за её функционирование.
Лучшая стратегия доступности — не всегда самая сложная. Это та, которая защищает наиболее значимые сервисы, может регулярно проверяться и позволяет уверенно действовать в условиях реальных инцидентов.
Передовой опыт для долгосрочной надёжности
Начните с классификации сервисов. Определите, какие системы критичны для выполнения миссии, какие важны для бизнеса, а какие могут выдержать более долгое восстановление. Это позволит направить ресурсы туда, где простой наносит наибольший ущерб.
Используйте мониторинг, отражающий реальные результаты для пользователей. Вместо проверки одного лишь статуса устройств следите за тем, могут ли пользователи войти в систему, совершить звонок, получить доступ к записям, отправить форму, получить оповещения или завершить транзакцию. Это даёт более точную картину работоспособности сервиса.
Поддерживайте документацию в актуальном состоянии. Архитектурные схемы, шаги переключения, списки контактов, пути эскалации, расположение резервных копий, порядок работы с учётными данными и процедуры отката должны обновляться после каждого значительного изменения. Во время инцидента устаревшая документация может задержать восстановление.
Регулярно пересматривайте архитектуру. Объём трафика, версии программного обеспечения, требования безопасности, сторонние зависимости и бизнес-приоритеты со временем меняются. Система, которая в прошлом соответствовала целям по доступности, может потребовать перепроектирования по мере роста нагрузки и изменения рисков.
Заключение
Высокая доступность — это практический метод сохранения доступности важных сервисов при возникновении отказов. Она объединяет резервную инфраструктуру, автоматическое переключение, мониторинг здоровья, балансировку нагрузки, репликацию данных, планирование обслуживания и отработанные процедуры восстановления. Её ценность особенно очевидна, когда простои затрагивают безопасность, доходы, связь, производство, нормативное соответствие или доверие клиентов.
Успешная HA-стратегия не сводится к простому добавлению оборудования. Она требует понимания всей сервисной цепочки, выявления единых точек отказа, постановки реалистичных целей восстановления, тестирования переключений и нахождения баланса между надёжностью, стоимостью и сложностью. Будучи грамотно спроектированной, высокая доступность помогает организациям строить системы, которые остаются надёжными в реальных условиях эксплуатации.
Часто задаваемые вопросы
Может ли высокодоступная система всё равно потерять данные?
Да. Доступность и защита данных связаны, но не тождественны. Если репликация отстаёт или политики резервного копирования слабы, сервис может быстро восстановиться, утратив при этом самые свежие данные. Для управления этим риском необходимо планирование RPO.
Высокая доступность — это то же самое, что отказоустойчивость?
Нет. Отказоустойчивость (fault tolerance) обычно подразумевает, что система продолжает работу практически без перерыва даже при выходе из строя компонента. Высокая доступность нацелена на сокращение простоев, но в зависимости от архитектуры может наблюдаться кратковременная задержка при переключении.
Стоит ли малому бизнесу внедрять высокую доступность?
Да, но масштаб решения должен соответствовать бизнес-рискам. Небольшой компании может не требоваться мультирегиональная архитектура, однако она способна выиграть от резервных интернет-каналов, надёжных резервных копий, облачного переключения, мониторинга сервисов и резервного питания для критичных систем.
Может ли высокая доступность защитить от кибератак?
Лишь отчасти. HA способна помочь сохранить работоспособность, если один узел изолирован или восстановлен, но она не заменяет средства кибербезопасности. Программы-вымогатели, кража учётных данных, DDoS-атаки и искажение информации требуют мониторинга безопасности, контроля доступа, установки обновлений, изоляции резервных копий и реагирования на инциденты.
Любое ли приложение поддерживает активно-активное развёртывание?
Нет. Некоторые приложения не рассчитаны на распределённые сессии, разделяемое состояние или многозвенную запись. Прежде чем выбирать активно-активную архитектуру, необходимо убедиться, что программное обеспечение, база данных, лицензионная модель и сетевая структура допускают такой режим работы.