Проблема базы данных редко остается только внутри самой базы. Когда единственная копия данных становится медленной, недоступной, поврежденной или перегруженной, бизнес-система над ней сразу ощущает последствия: заказы не оформляются, отчеты не формируются, устройства не загружают записи, пользователи не входят в систему, а восстановление превращается в гонку со временем.
Именно для этого существует репликация базы данных. Она создает одну или несколько дополнительных копий данных и поддерживает их синхронизацию с исходной базой, чтобы системы могли быстрее читать, быстрее восстанавливаться, распределять нагрузку и продолжать работу, когда одного узла базы данных уже недостаточно.
Базовая идея репликации базы данных
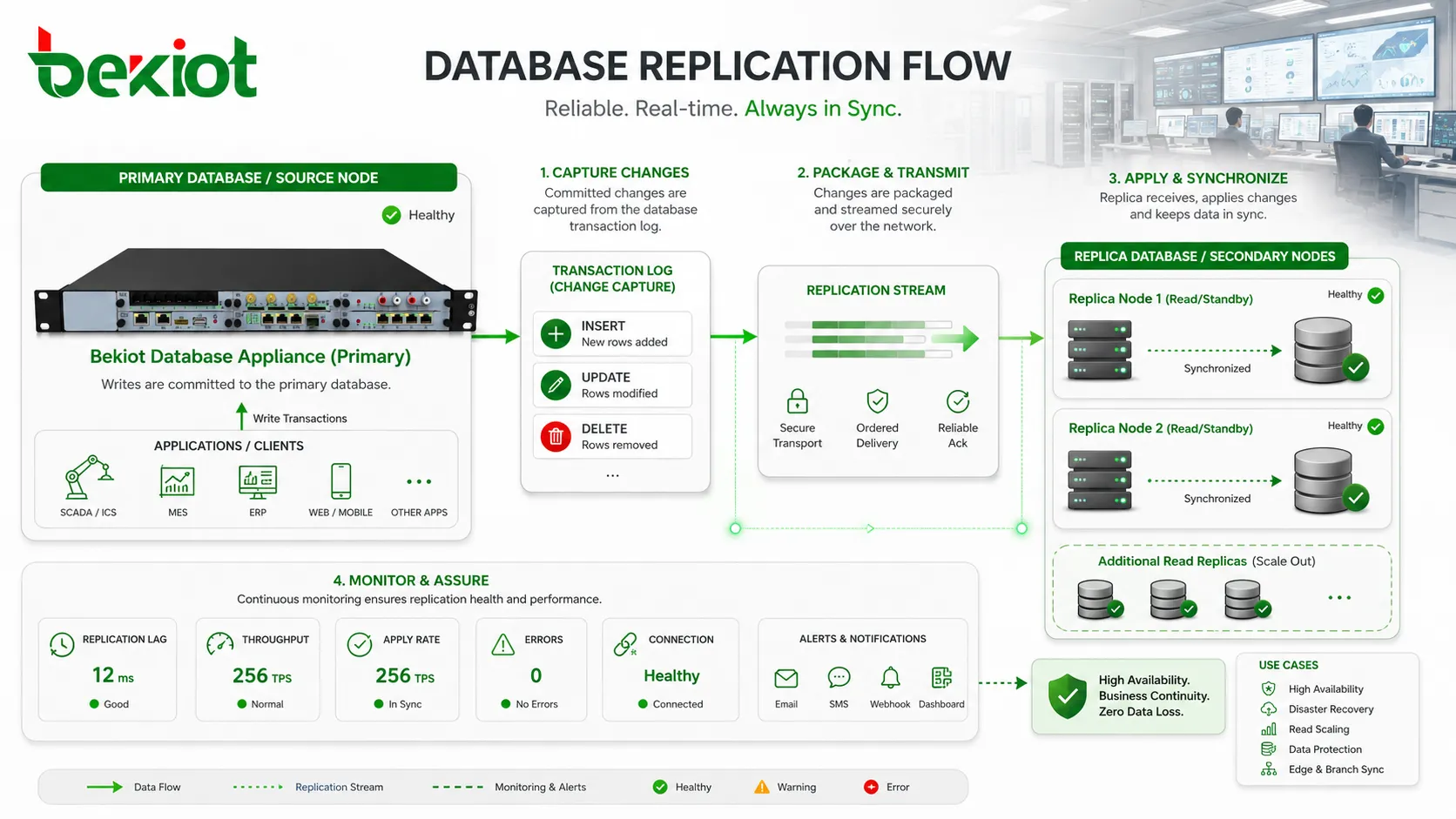
Репликация базы данных — это процесс копирования данных с одного узла базы данных на другой и поддержания этих копий в актуальном состоянии по мере появления изменений. Исходная база может называться первичной, master, publisher или leader в зависимости от технологии. Принимающая база может называться репликой, standby, subscriber, secondary или follower. Названия различаются, но смысл один: изменения, сделанные в одном месте, контролируемо доставляются в другое место.
Копироваться могут целые базы, выбранные таблицы, разделы, схемы, журналы транзакций или отдельные потоки данных. В одних системах реплика используется только для резервирования или переключения при отказе. В других реплики обслуживают чтение, аналитику, отчеты, региональный доступ или последующую обработку данных. Поэтому репликация — не одна фиксированная функция, а архитектурный метод для разных операционных задач.
В центре репликации находится отслеживание изменений. Когда данные вставляются, обновляются или удаляются, база должна определить изменение, надежно упаковать его, отправить на другой узел и применить в правильном порядке. Если процесс неаккуратен, реплика может стать несогласованной. Если он слишком медленный, появляется отставание. Если его не контролировать, команда может заметить проблему только в момент восстановления.
Хороший проект репликации отвечает на практические вопросы: какие данные копировать, как быстро они должны приходить, кто может выполнять запись, как решаются конфликты, что происходит при отказе сети и как приложения должны вести себя при недоступности узла. Эти ответы определяют, будет ли репликация средством устойчивости или скрытым источником путаницы.
Что фактически передается между узлами базы данных
Репликация не всегда является простой копией файлов. В большинстве промышленных систем база не отправляет весь набор данных заново при каждом изменении записи. Вместо этого она захватывает изменение и передает только то, что нужно для воспроизведения этого изменения на реплике. Это снижает расход пропускной способности и позволяет реплике оставаться близкой к источнику без полного перестроения.
Распространенный метод — репликация на основе журналов. Первичная база записывает изменения в журналы транзакций, бинарные журналы, журналы предварительной записи или redo logs. Реплика читает эти журналы и применяет те же операции в последовательности. Метод широко используется, потому что журнал уже отражает авторитетный порядок изменений.
Другой подход — репликация на основе операторов, когда SQL-операторы отправляются на реплику. Это может быть проще в некоторых системах, но приводит к различиям, если оператор зависит от недетерминированных функций, времени, случайных значений или особенностей окружения. Репликация на основе строк уменьшает эти риски, передавая реальные изменения строк, а не только оператор.
Некоторые системы используют репликацию снимков. Полная или частичная копия данных создается на определенный момент времени и доставляется в другое место. Это удобно для начальной синхронизации, баз отчетности или периодического распространения данных. Но одних снимков обычно недостаточно для систем с почти реальным временем обновления.
Современные архитектуры также используют change data capture, или CDC. CDC извлекает изменения базы данных и отправляет их в аналитические платформы, поисковые индексы, очереди сообщений или озера данных. В таком случае репликация не только поддерживает еще одну копию базы, а становится частью конвейера движения данных организации.
Репликация primary-replica в ежедневной работе
Самый привычный шаблон — репликация primary-replica. Один узел принимает записи, а одна или несколько реплик получают копии изменений. Приложения отправляют вставки, обновления и удаления в первичный узел. Запросы только на чтение могут отправляться на реплики, если приложение и архитектура это поддерживают.
Этот шаблон понятен и широко применяется, потому что ясно определяет владельца записи. Первичный узел является источником истины для изменений, а реплики следуют его состоянию. Если реплика выходит из строя, первичный узел продолжает работу. Если выходит из строя первичный узел, одна реплика может быть повышена до новой первичной в соответствии с проектом failover.
Практическая польза — разделение нагрузки. Транзакционные записи, действия пользователей и бизнес-обновления остаются на первичном узле, а отчеты, панели, поисковые запросы или сервисы с большим чтением могут использовать реплики. Это снижает давление на основную базу и улучшает время отклика.
Однако приложения должны понимать, что реплики не всегда абсолютно актуальны, особенно при асинхронной репликации. Пользователь, записавший данные в primary и сразу прочитавший их с отстающей реплики, может не увидеть последнее изменение. Это не обязательно сбой, а проектный компромисс, который нужно учитывать.
Multi-primary и распределенные схемы
Некоторым средам нужен не один записываемый узел. При multi-primary репликации несколько узлов могут принимать записи и затем обмениваться изменениями. Это поддерживает распределенные площадки, региональные операции, локальную запись или высокую доступность между дата-центрами. Схема привлекательна, но сложнее, чем primary-replica.
Главная проблема — конфликты. Если два узла одновременно обновляют одну запись, система должна решить, какое изменение победит или как их объединить. Правила могут основываться на времени, версиях, логике приложения, приоритете узла или ручном решении. Плохая обработка конфликтов ухудшает качество данных.
Распределенная репликация используется также в edge-системах, розничных филиалах, промышленных площадках, мобильных приложениях и удаленных операциях, где локальные данные должны быть доступны при нестабильной центральной сети. Локальный узел может временно хранить и изменять данные, а затем синхронизироваться с центром. Это повышает локальную непрерывность, но требует строгих правил.
Multi-primary стоит выбирать только тогда, когда бизнес-потребность оправдывает сложность. Для многих приложений проще один записывающий primary с читающими репликами. Если локальная запись в нескольких местах действительно необходима, управление конфликтами, владение данными и мониторинг должны быть спроектированы до внедрения.
Синхронная и асинхронная репликация
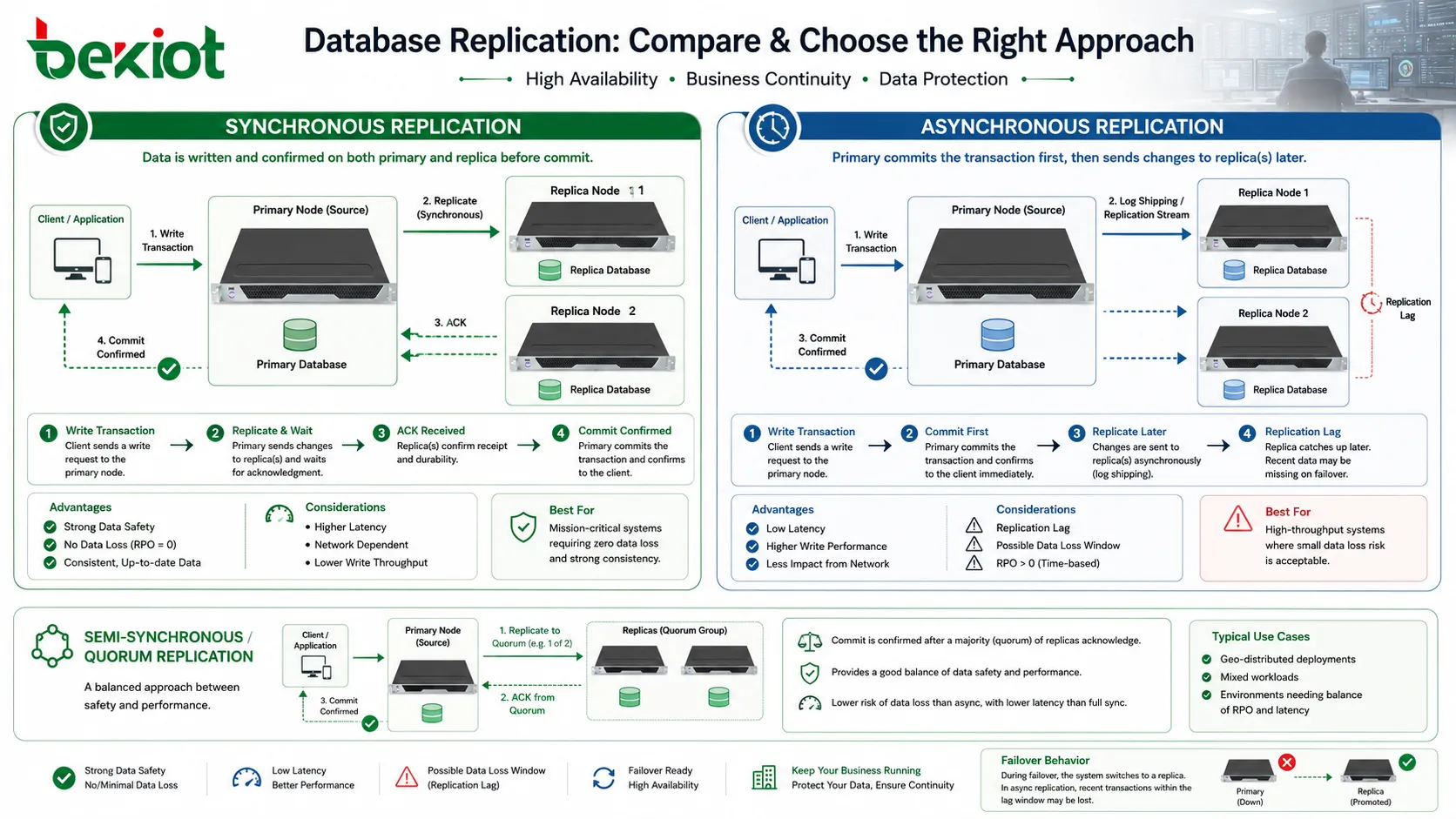
Время репликации — одно из ключевых проектных решений. При синхронной репликации транзакция не считается полностью подтвержденной, пока другой узел базы данных не подтвердит изменение. Это повышает безопасность данных, потому что реплика получает изменение до того, как приложение увидит успех. Если primary откажет вскоре после commit, подтвержденные данные с большей вероятностью уже есть на другом узле.
Цена — задержка. Если реплика далеко или сеть медленная, primary должен дольше ждать завершения транзакции. Это влияет на отклик приложения. Синхронная репликация обычно применяется там, где допустимая потеря данных очень мала, а сетевой путь между узлами достаточно надежен.
При асинхронной репликации primary сначала фиксирует транзакцию, а затем отправляет изменение репликам. Это улучшает скорость записи, потому что приложение не ждет удаленного подтверждения. Такой режим часто используется для отчетности, масштабирования чтения или аварийного восстановления на больших расстояниях.
Компромисс — отставание репликации. Если primary откажет до доставки изменений на реплику, часть недавних транзакций может быть потеряна или потребует восстановления из журналов. Поэтому асинхронная репликация должна соответствовать понятным целям восстановления: допустимой потере данных и ожидаемой скорости догоняния.
Некоторые системы используют полусинхронные или quorum-методы, чтобы сбалансировать производительность и безопасность. Они подтверждают транзакцию после ответа одной или нескольких реплик, но не обязательно ждут всех. Выбор зависит от бизнес-риска, качества сети, объема транзакций и требований к восстановлению.
Преимущества доступности и failover
Самая прямая выгода репликации — повышение доступности. Если первичная база выходит из строя, реплика может быть повышена и продолжить обслуживание. Без репликации восстановление часто зависит от возврата из резервной копии, что занимает больше времени и может потерять больше свежих данных. Репликация дает почти живую копию для более быстрого восстановления.
Failover может быть ручным или автоматическим. Ручной режим дает администраторам больше контроля, что важно в сложной среде или при риске split-brain. Автоматический режим сокращает простой, но должен быть спроектирован так, чтобы два узла не считали себя primary одновременно. В системах высокой доступности решение обычно поддерживают мониторинг, health checks, quorum или кластерное управление.
Доступность зависит и от поведения приложений. Повысить реплику недостаточно, если приложения не переподключаются, DNS обновляется медленно, пул соединений продолжает использовать старый адрес или пользователям приходится менять настройки вручную. Репликацию нужно планировать вместе с маршрутизацией приложений, балансировщиками, строками подключения, service discovery и операционными процедурами.
Реплика также помогает при обслуживании. Во время плановых обновлений, установки патчей, замены оборудования или миграции хранилища часть нагрузки иногда можно перенести на другой узел. Это уменьшает плановые остановки и дает администраторам гибкость. Сильные проекты поддерживают и аварийное восстановление, и обычное обслуживание.
Масштабирование чтения без изменения основной модели данных
Многие базы перегружаются не из-за записей, а из-за роста чтений. Панели, отчеты, страницы поиска, клиентские порталы, мониторинг и API могут читать одну и ту же базу. Если все чтения идут на primary, обычные транзакции замедляются. Репликация позволяет распределить чтения по репликам.
Читающие реплики часто используются для отчетности и аналитики. Длинные запросы могут выполняться на репликах, не блокируя и не замедляя критическую транзакционную работу на primary. Это полезно, когда бизнесу нужны частые отчеты, а производственная база должна оставаться отзывчивой.
Разделение чтения и записи в приложении также улучшает масштабируемость. Приложение отправляет записи на primary, а часть чтений — на реплики. Это требует осторожности, потому что реплики могут отставать. Данные, которым нужна немедленная согласованность, могут читаться с primary; данные, терпящие небольшую задержку, подходят для реплик.
Такой подход увеличивает емкость чтения без полного изменения модели данных. Вместо немедленного перехода на новую архитектуру команда может добавить реплики, оптимизировать маршрутизацию запросов и отделить отчетные нагрузки. Это часто практический промежуточный шаг масштабирования.
Аварийное восстановление и географическая устойчивость
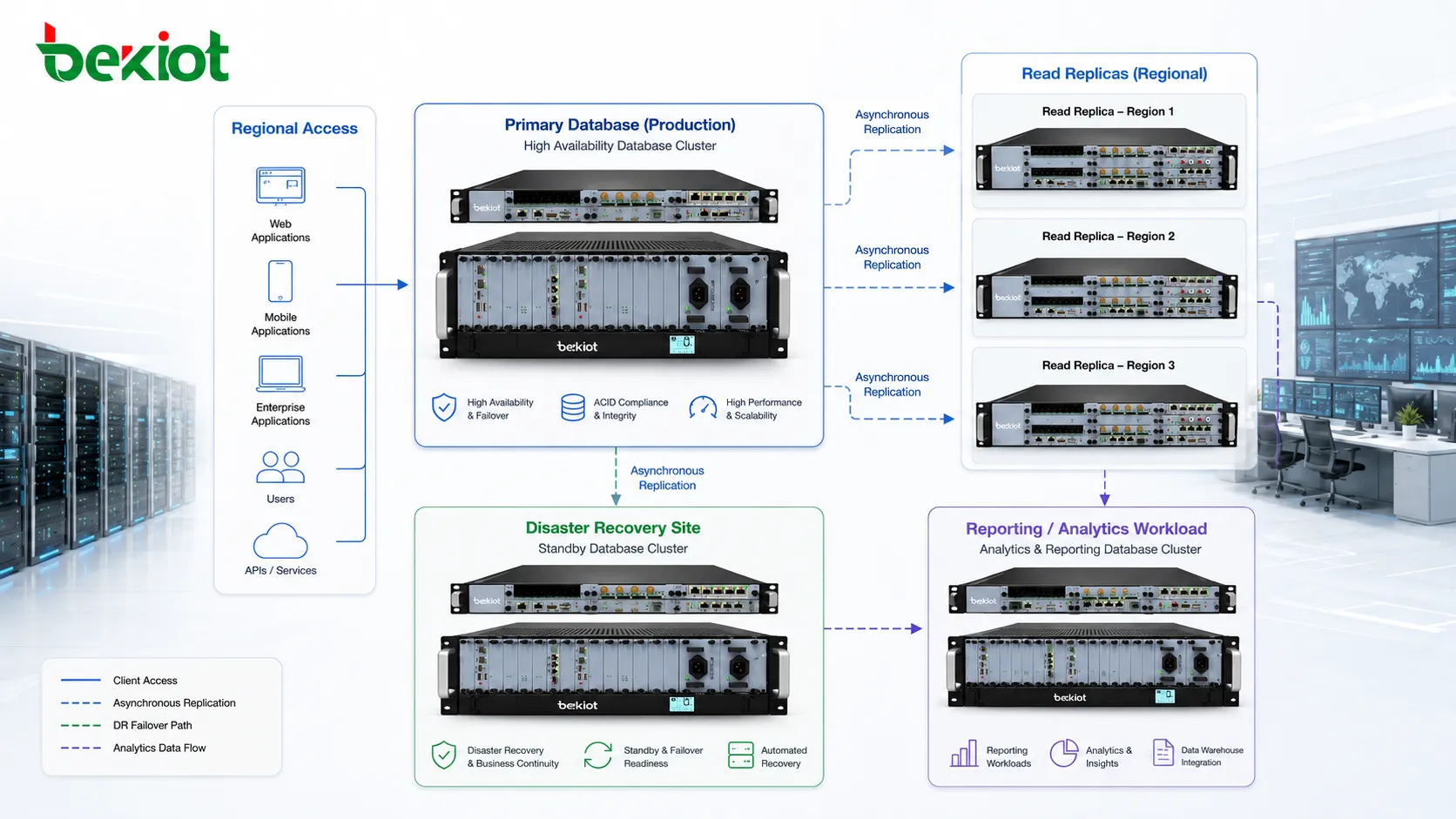
Репликация часто используется для disaster recovery. Реплика в другом дата-центре, облачном регионе или физическом месте защищает от пожара, отключения питания, сетевого сбоя, отказа хранилища или катастрофы площадки. Если primary-сайт недоступен, удаленная реплика может стать путем восстановления.
Географическая репликация требует осторожного планирования, потому что расстояние увеличивает задержку. Синхронная репликация на дальние расстояния может быть слишком медленной. Асинхронная чаще используется для удаленного восстановления, но допускает потерю данных, если primary-сайт отказал до копирования всех изменений.
План восстановления должен определить RTO и RPO. RTO описывает, как быстро сервис должен вернуться. RPO описывает, сколько данных допустимо потерять. Строгий RPO может требовать более синхронной защиты или минимального отставания. Более гибкий RPO может использовать асинхронную репликацию с регулярными проверками.
Аварийное восстановление нужно тестировать. Реплика, которую никогда не повышали, не проверяли с приложениями и не восстанавливали в реалистичном сценарии, может оказаться ненадежной во время реальной аварии. Репликация дает техническую основу, но учения подтверждают процесс.
Локальность данных и региональная производительность
Репликация может приблизить данные к пользователям, филиалам или региональным приложениям. Когда пользователи в разных местах читают с ближайшей реплики, время отклика может улучшиться. Это полезно для глобальных приложений, multi-region сервисов, розничных сетей, логистики, финансовых платформ и распределенных корпоративных систем.
Региональные реплики также снижают нагрузку на центральные каналы. Вместо отправки каждого запроса через дальнее соединение локальные пользователи или сервисы читают из ближайшей копии. Это особенно полезно при большом чтении и управляемых требованиях к свежести данных.
Локальность данных поддерживает и местную отчетность. Региональный офис может анализировать свои транзакции, запасы, сервисные записи или операционные данные, не нагружая постоянно центральную production-базу. Локальная реплика дает такой доступ, пока центральная система сосредоточена на основных транзакциях.
Но региональная репликация должна учитывать управление данными. Некоторые данные ограничиваются законами о приватности, внутренними правилами, договорами с клиентами или отраслевыми нормами. Копирование в другую страну или регион может требовать согласования, шифрования, контроля доступа или минимизации. Репликация должна улучшать производительность без ослабления governance.
Резервная копия — не то же самое, что репликация
Репликация и backup часто упоминаются вместе, но решают разные задачи. Репликация поддерживает другую копию базы актуальной для доступности, производительности или распределения. Backup создает восстанавливаемые исторические копии после удаления, повреждения, ransomware, случайных изменений или долгосрочной потери данных.
Реплика может точно скопировать ошибку. Если пользователь удалит важные записи на primary, репликация быстро удалит их и на реплике. Если приложение запишет поврежденные данные, реплика получит тот же испорченный статус. В этом случае репликация не защищает организацию без point-in-time recovery, задержанной репликации или резервных копий.
Backups восстанавливаются медленнее, но лучше подходят для исторического восстановления. Они позволяют вернуться к состоянию в прошлом. Репликация быстрее для непрерывности сервиса, но не всегда дает исторический откат. Надежная стратегия обычно включает и репликацию, и backup.
Различие должно быть ясно в операционном плане. Для быстрого failover полезна репликация. Для восстановления данных за прошлую неделю нужен backup. Если нужны оба результата, оба процесса следует проектировать и регулярно тестировать.
Мониторинг состояния репликации
Репликацию нужно контролировать постоянно. Реплика, отстающая на часы, может выглядеть онлайн, но быть бесполезной для failover или неверной для отчетности. Обычно отслеживают lag, статус реплики, прогресс отправки журналов, скорость применения, ошибки, соединение, диск, задержку транзакций и неудачные события синхронизации.
Отставание репликации особенно важно. Оно измеряет задержку между изменением на primary и его появлением на реплике. Малое отставание может быть приемлемым для отчетов. Большое отставание ломает предположения приложений или увеличивает риск потери данных при failover. Пороги должны задаваться для каждого сценария.
Хранилище и емкость также важны. Репликация может создавать журналы, временные файлы, relay logs, архивные журналы или промежуточные данные. Если диск заполнится, репликация остановится. Если реплика слишком слабая, она не применит изменения достаточно быстро при пике. Реплика должна быть рассчитана на свою нагрузку.
Оповещения должны быть содержательными. Они должны не только говорить, что репликация упала, но и помогать понять причину: сеть, аутентификация, позиция лога, диск, несовпадение схемы, права или конфликтующие записи. Чем быстрее понятна причина, тем быстрее восстанавливается поток данных.
Безопасность и контроль доступа
Репликация увеличивает число мест, где находятся чувствительные данные. Каждая реплика должна защищаться так же серьезно, как primary. Менее защищенная реплика может стать самым простым путем утечки. План безопасности должен включать шифрование, контроль доступа, аудит, сетевые ограничения и управление учетными данными для каждого узла.
Трафик репликации следует защищать, особенно если он идет между дата-центрами, облачными регионами, публичными сетями или сторонними каналами. Шифрование в пути снижает риск перехвата. Аутентификация между узлами мешает неавторизованным системам присоединиться к репликации. Сегментация сети уменьшает контакт с посторонними системами.
Права доступа на репликах нужно проверять отдельно. Реплика отчетности может быть доступна аналитикам только на чтение, но это не значит, что все таблицы должны быть видны всем. Чувствительные поля могут требовать маскирования, фильтрации или отдельной политики. Иногда реплика должна содержать только данные, нужные для ее задачи.
Административный доступ также требует контроля. Пользователи, способные остановить репликацию, повысить реплику, изменить фильтры или учетные данные, имеют значительную власть. Эти действия нужно логировать и ограничивать авторизованным персоналом. Репликация является частью доверенной границы базы данных, а не только фоновым процессом.
Частые ошибки при внедрении
Частая ошибка — внедрять репликацию без ясной цели. Если цель — доступность, нужны процедура failover и переподключение приложений. Если цель — отчетность, нужно учитывать нагрузку запросов и свежесть данных. Если цель — аварийное восстановление, нужны удаленная площадка, RTO, RPO и учения. Размытая цель создает размытую архитектуру.
Еще одна ошибка — считать, что реплика всегда актуальна. Асинхронные реплики могут отставать. Тяжелые записи, нестабильная сеть, медленные диски, изменения схемы или длинные транзакции задерживают репликацию. Приложения, читающие с реплик, должны учитывать эту задержку.
Некоторые команды не тестируют повышение реплики. Они создают реплики, но не практикуют переключение. В аварии обнаруживаются проблемы прав, подключений приложений, отсутствующих заданий, неполной конфигурации или несогласованных данных. Failover нужно тестировать заранее.
Фильтры репликации тоже создают путаницу. Если копируются только отдельные таблицы или базы, команды должны точно знать, что включено и исключено. Команда отчетности может ожидать все данные, хотя копируется только часть схемы. Документация предотвращает ложные предположения.
Наконец, многие внедрения недооценивают сопровождение. Репликация должна переживать обновления, изменения схем, продление сертификатов, смену паролей, рост хранилища, изменения сети и различия версий. Это не функция «настроил и забыл». Ей нужен владелец.
Когда репликация дает наибольшую ценность
Репликация наиболее ценна, когда у организации есть четкая потребность в доступности, масштабировании чтения, аварийном восстановлении, распределении данных или разделении нагрузки. Она менее полезна, если база мала, простой допустим, чтения немного, а восстановления из backup достаточно. Как любое архитектурное решение, она должна соответствовать проблеме.
Для критичных систем она снижает простой и расширяет варианты восстановления. Для растущих приложений переносит отчеты и чтения с primary. Для распределенных организаций поддерживает региональный доступ. Для data-команд доставляет операционные данные в аналитику, не мешая production-нагрузке.
Самые сильные проекты обычно просты и ясны. Они определяют, какой узел принимает записи, какие узлы обслуживают чтения, как контролируется lag, как работает failover, как поддерживаются backups и кто отвечает за репликационную связь. Сложность стоит добавлять только при сильной бизнес-причине.
Репликация — не магическая копия безопасности. Это дисциплинированный способ держать данные доступными более чем в одном месте. Ее преимущества проявляются, когда технический дизайн, поведение приложений, мониторинг, безопасность и восстановление спланированы вместе.
Частые вопросы
Репликация базы данных используется в основном для backup?
Нет. Она может помогать восстановлению, но не заменяет резервные копии. Реплика может скопировать случайное удаление или поврежденные данные с primary. Backup все равно нужен для исторического восстановления и point-in-time restore.
Что такое отставание репликации?
Это задержка между подтверждением изменения на primary и появлением того же изменения на реплике. Она обычна при асинхронной репликации и должна контролироваться, если реплики используются для чтения или failover.
Могут ли приложения писать в реплики?
В схемах primary-replica реплики обычно только для чтения. Multi-primary системы позволяют запись на нескольких узлах, но требуют обработки конфликтов и более строгого операционного контроля.
Улучшает ли репликация производительность?
Она может улучшить производительность, перенеся чтение, отчеты и аналитику с primary. Но она не ускоряет все нагрузки автоматически. Системам с интенсивной записью могут понадобиться индексы, оптимизация запросов, партиционирование, более мощное оборудование или изменение архитектуры.
Что нужно проверить перед использованием репликации?
Нужно тестировать начальную синхронизацию, lag под нагрузкой, failover, повышение реплики, переподключение приложений, восстановление из backup, оповещения, права безопасности и поведение при сетевом сбое.