

Поддержание работы сервисов при сбоях
Отказоустойчивое переключение — это механизм надежности, который автоматически или вручную переводит работу с отказавшего основного компонента на резервный компонент. Он помогает сохранять доступность приложений, сетей, серверов, баз данных, коммуникационных систем, облачных сервисов и промышленных платформ, когда оборудование, программное обеспечение, каналы или службы перестают работать.
По сути, оно отвечает на один практический вопрос: если основная система отказала, что принимает работу на себя? Хорошо спроектированная архитектура сокращает простой, защищает непрерывность сервиса и ускоряет восстановление после отказов, перегрузок, обслуживания или неожиданных отключений.
Отказоустойчивое переключение не предотвращает все сбои. Его ценность в том, что при отказе у системы уже есть подготовленный путь восстановления.
Базовое значение и роль в системе
Отказоустойчивое переключение обычно применяется в проектах высокой доступности. Основной ресурс выполняет штатную работу, а один или несколько резервных ресурсов остаются готовыми принять сервис, если основной ресурс становится недоступным. Резервом может быть сервер, маршрутизатор, узел базы данных, сетевой канал, дата-центр, облачный регион, хранилище или экземпляр приложения.
Цель состоит в сокращении перерыва в обслуживании. Система не ждет, пока специалисты восстановят отказавший компонент, а переводит трафик, рабочие нагрузки, сеансы или запросы на другой доступный ресурс.
Основные и резервные ресурсы
Основной ресурс — активный компонент, который обычно предоставляет сервис. Резервный ресурс подготовлен к принятию работы при отказе основного. В одних системах резерв пассивен и ожидает срабатывания переключения, а в других несколько ресурсов одновременно активно разделяют трафик.
Например, сайт может работать на двух серверах приложений. Если первый сервер отказывает, трафик направляется на второй. Маршрутизатор может использовать резервный WAN-канал при падении основного интернет-соединения. База данных может повысить реплику до нового основного узла.
Обнаружение отказов
Переключение зависит от обнаружения отказов. Система должна понимать, когда основной компонент работает неправильно. Для этого применяются heartbeat-сигналы, проверки работоспособности, мониторинг каналов, сервисные пробы, состояние репликации, проверки ответа приложения и тесты сетевой доступности.
Обнаружение должно быть быстрым, чтобы уменьшать простой, но не чрезмерно чувствительным, чтобы не запускать лишнее переключение из-за короткой задержки или временной потери пакетов. Такой баланс важен в реальных сетях и приложениях.
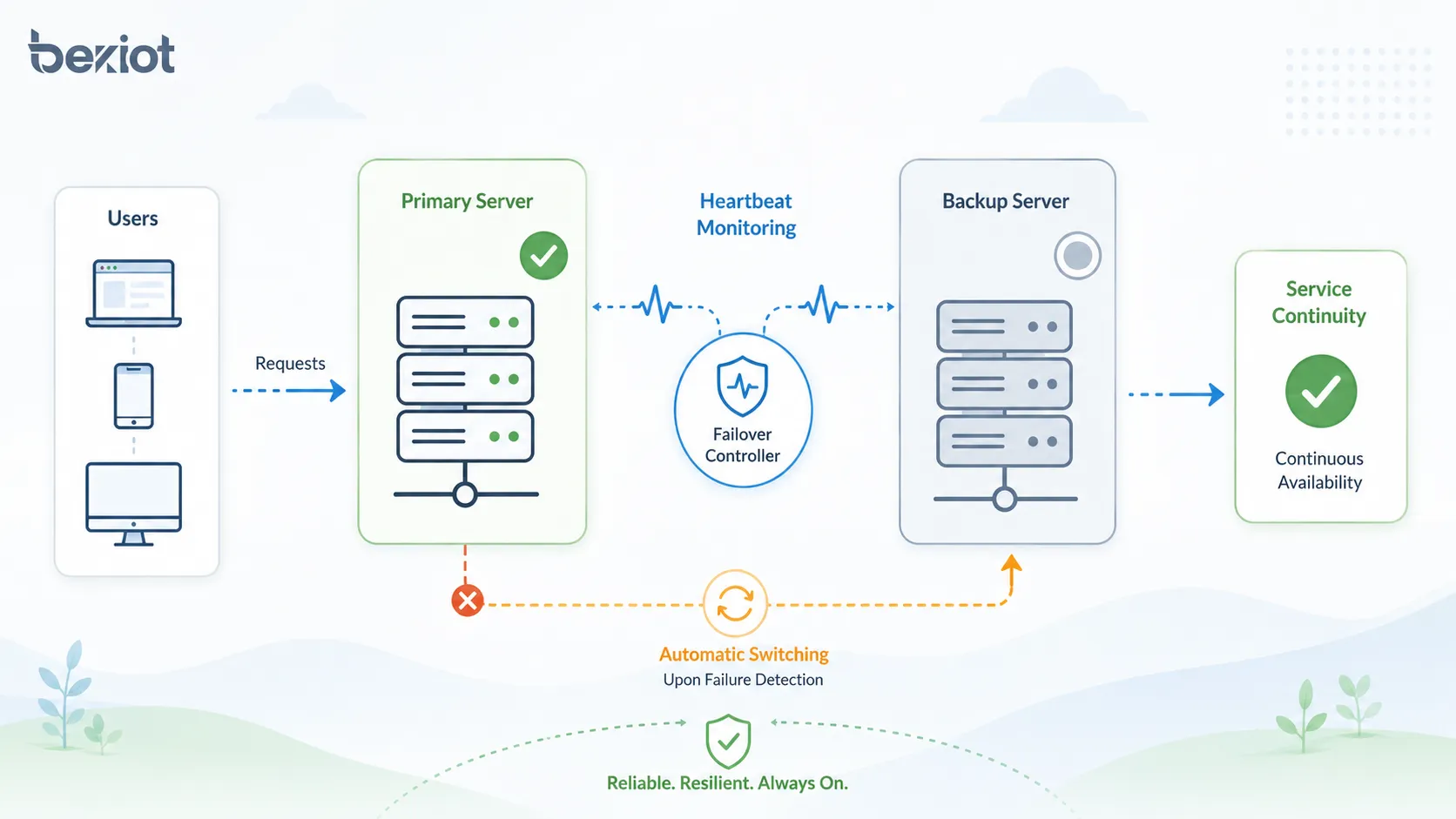
Как работает процесс переключения
Процесс включает мониторинг, обнаружение отказа, принятие решения, перевод сервиса, перенаправление трафика, проверку восстановления и регистрацию событий. Детали зависят от типа системы, но базовая логика остается похожей.
Когда мониторинг видит, что основная система недоступна или работает некорректно, контроллер переключения активирует резервный путь. Пользователи могут заметить краткую паузу, однако сервис должен продолжить работу через резервный компонент.
Мониторинг и проверки работоспособности
Проверки работоспособности подтверждают, что сервис функционирует правильно. Простая проверка может только определить, отвечает ли сервер на ping. Более глубокая проверка убеждается, что приложение обрабатывает запросы, подключается к базе данных и возвращает корректные ответы.
Проверки уровня приложения обычно надежнее простых сетевых проверок. Сервер может отвечать на ping, даже если приложение зависло, перегружено или не может обратиться к нужным backend-сервисам.
Переход на резервные ресурсы
После подтверждения отказа система переводит работу на резервный ресурс. Это может включать изменение таблиц маршрутизации, обновление DNS-записей, перенос виртуального IP, повышение реплики базы данных, активацию резервного сервера или перенаправление через балансировщик нагрузки.
Метод переключения должен соответствовать бизнес-требованиям. Одни системы допускают несколько минут простоя, а критические требуют почти мгновенного переключения с минимальным влиянием на пользователей.
Проверка сервиса после переключения
После переключения резервный сервис необходимо проверить. Система должна подтвердить, что пользователи подключаются, транзакции продолжаются, данные доступны, а зависимые сервисы работают корректно.
Проверка важна, потому что сам перевод трафика на резерв не гарантирует нормальную работу. Резерв должен быть синхронизирован, правильно настроен и способен выдерживать рабочую нагрузку.
Основные типы отказоустойчивого переключения
Схемы переключения выбираются с учетом критичности системы, бюджета, требований к производительности и целей восстановления. Наиболее распространены active-passive, active-active, ручное, автоматическое, локальное и географическое переключение.
Active-Passive переключение
В схеме active-passive одна система активно обрабатывает производственный трафик, а другая находится в режиме ожидания. Если активная система отказывает, пассивная становится активной и принимает сервис.
Модель проста и широко применяется для серверов, firewall, баз данных, PBX, контроллеров хранения и сетевых шлюзов. Ее преимущество — ясное разделение ролей, а ограничение — недостаточное использование резерва в обычной работе.
Active-Active переключение
В схеме active-active две или более системы одновременно обрабатывают трафик. Если одна отказывает, остальные продолжают обслуживать пользователей и принимают дополнительную нагрузку.
Эта модель повышает использование ресурсов и масштабируемость, но усложняет проектирование. Балансировка нагрузки, синхронизация данных, управление сеансами, контроль конфликтов и расчет емкости требуют большего внимания.
Ручное и автоматическое переключение
Ручное переключение запускается оператором или администратором. Оно дает человеческий контроль и полезно при обслуживании, плановой миграции или чувствительных изменениях.
Автоматическое переключение запускается правилами системы. Оно быстрее и лучше подходит для высокой доступности, но требует осторожной настройки, чтобы избежать ложного срабатывания, split-brain или частого переключения между узлами.
Локальное и географическое переключение
Локальное переключение происходит в пределах одного объекта, стойки, дата-центра или сетевой зоны. Оно защищает от локального отказа сервера, канала, питания или устройства.
Географическое переключение переносит сервис в другой дата-центр, облачный регион или удаленную площадку. Оно защищает от крупных инцидентов, включая отказ дата-центра, региональную сетевую проблему, потерю питания, пожар, наводнение или сбой инфраструктуры.
Ключевые свойства надежного дизайна
Хорошая система должна не только быстро переключаться. Она должна делать это безопасно, последовательно и предсказуемо. Важны мониторинг, резервирование, синхронизация, управление трафиком, журналирование и план восстановления.
Резервированные компоненты
Резервирование означает наличие запасных компонентов до возникновения отказа. Это могут быть серверы, источники питания, сетевые каналы, маршрутизаторы, коммутаторы, пути хранения, базы данных, экземпляры приложений и облачные регионы.
Резервирование должно быть реальным. Резервный сервер, подключенный к тому же отказавшему источнику питания или к одному коммутатору, не дает настоящей устойчивости. Нужно исключать скрытые единые точки отказа.
Heartbeat и мониторинг состояния
Heartbeat-сигналы помогают проверить, жив ли основной узел. Если резервный узел перестает получать такие сообщения в заданный период, он может считать основной узел отказавшим.
При проектировании heartbeat учитываются задержка сети, потеря пакетов и надежность управляющего канала. Неверная настройка может привести к split-brain, когда два узла одновременно считают себя активными.
Синхронизация данных
Многие системы требуют синхронизации данных между основным и резервным узлами. Это может быть репликация базы данных, синхронизация файлов, зеркалирование хранения, резервное копирование конфигурации или обмен состоянием.
Синхронизация влияет на качество восстановления. Если резерв содержит устаревшие данные, сервис восстановится, но последние транзакции могут быть потеряны. Если синхронизация слишком медленная, цели RPO не выполняются.
Автоматическое перенаправление трафика
Перенаправление трафика позволяет пользователям и системам попасть на резервный сервис после переключения. Для этого используются балансировщики нагрузки, виртуальные IP, протоколы маршрутизации, DNS failover, политики SD-WAN или шлюзы приложений.
Метод перенаправления должен соответствовать ожидаемому времени восстановления. DNS-переключение просто, но может быть медленнее из-за кэша. Балансировщик или виртуальный IP обычно быстрее в локальных средах высокой доступности.
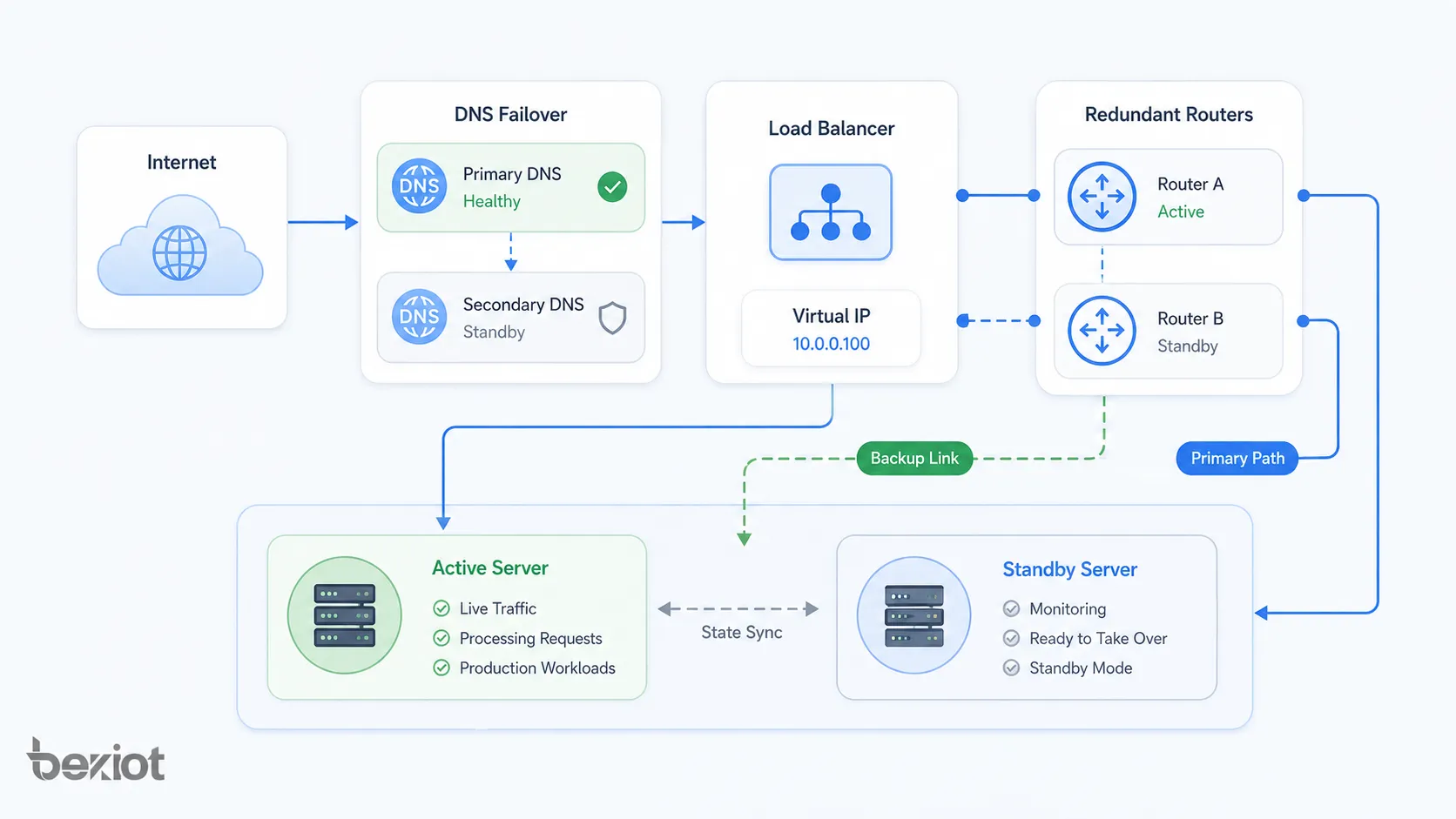
Шаблоны сетевой архитектуры
Архитектура переключения применяется на разных уровнях сети и системного стека. Она может защищать физические каналы, маршруты, серверные кластеры, базы данных, облачные регионы и прикладные сервисы.
Переключение на уровне сервера
Серверное переключение использует два или более серверов для одного сервиса. Если один сервер отказывает, другой принимает работу. Это распространено для серверов приложений, веб-серверов, файловых, коммуникационных и управляющих серверов.
Такое переключение может использовать кластерное ПО, виртуализацию, балансировщики нагрузки, оркестрацию контейнеров или сервисы высокой доступности. Согласованность конфигурации между серверами обязательна.
Переключение сетевого канала
Переключение сетевого канала использует резервные пути, когда основное соединение отказывает. Примеры включают dual WAN, резервную оптику, LTE или 5G backup, резервных ISP и переключение SD-WAN.
Это важно для филиалов, удаленных площадок, розничных сетей, промышленных объектов и облачных систем. Если основной канал отказывает, резерв сохраняет связь, хотя пропускная способность или задержка могут измениться.
Переключение маршрутизатора и firewall
Маршрутизаторы и firewall часто поддерживают пары высокой доступности. Одно устройство может быть активным, другое резервным, или оба могут делить нагрузку. Виртуальный адрес шлюза позволяет клиентам не знать, какое физическое устройство активно.
Firewall-переключение должно по возможности синхронизировать состояние сеансов. Без такой синхронизации существующие соединения могут оборваться, даже если новые подключения продолжают работать.
Переключение базы данных
Переключение базы данных защищает сервисы данных, переводя работу с отказавшей основной базы на реплику или резервную базу. Оно используется в корпоративных приложениях, e-commerce, финансовых системах, облачных сервисах и критических операционных платформах.
Оно требует осторожной работы с задержкой репликации, согласованностью транзакций, конфликтами записи и повторным подключением приложений. Плохой дизайн может привести к потере данных или ошибкам приложения.
Облачное и межрегиональное переключение
Облачное переключение переводит сервисы между зонами, регионами или провайдерами. Оно защищает от локальных инфраструктурных отказов и поддерживает аварийное восстановление.
Межрегиональная схема может требовать глобального управления трафиком, реплицированных баз данных, синхронизации объектного хранилища, доступности идентификационного сервиса и проверенных процедур. Дизайн должен соответствовать RTO и RPO.
Метрики и цели планирования
Планирование часто опирается на метрики доступности и восстановления. Они помогают определить нужный уровень резервирования и допустимый простой или потерю данных.
| Метрика | Значение | Почему важно |
|---|---|---|
| RTO | Целевое время восстановления | Максимально допустимое время восстановления сервиса после отказа |
| RPO | Целевая точка восстановления | Максимально допустимый объем потери данных, измеренный временем |
| MTTR | Среднее время ремонта | Среднее время восстановления отказавшего компонента |
| MTBF | Среднее время между отказами | Средняя длительность работы между отказами |
| Доступность | Процент времени, когда сервис работает | Показывает общий уровень uptime сервиса |
Целевое время восстановления
RTO определяет, как быстро сервис должен быть восстановлен после отказа. Некритичный внутренний отчетный инструмент может выдержать часы простоя, а платежная система, аварийная платформа или система управления производством может требовать восстановления за секунды или минуты.
Более низкое RTO обычно требует больших инвестиций в автоматизацию, резервирование, мониторинг и инфраструктуру. Дизайн должен соответствовать бизнес-влиянию, а не одинаково защищать все системы.
Целевая точка восстановления
RPO определяет допустимую потерю данных. Если организация может потерять только несколько секунд данных, нужна почти реальная репликация. Если допустимы часы, может хватить планового backup.
RPO особенно важно для баз данных, файловых систем, транзакционных платформ, клиентских записей и операционных журналов. Переключение без планирования данных может восстановить сервис, но принести недопустимые бизнес-потери.
Польза для бизнеса и эксплуатации
Переключение полезно, потому что простой влияет на выручку, безопасность, продуктивность, доверие клиентов и операционную непрерывность. Хорошая стратегия помогает поддерживать сервис при неожиданных отказах и плановом обслуживании.
Более высокая доступность сервиса
Основная польза — повышение доступности. Когда основной компонент отказывает, резервный продолжает обслуживание. Это сокращает простой и помогает пользователям продолжать работу.
Высокая доступность важна для онлайн-сервисов, коммуникационных систем, медицинских платформ, транспортных сетей, промышленной автоматизации, финансовых систем и публичных приложений.
Снижение операционного риска
Переключение снижает риск того, что отказ одного компонента остановит всю систему. Это особенно важно для систем с одной точкой отказа, например одним интернет-каналом, сервером, базой данных или шлюзом.
Добавляя резервные пути и автоматическую логику восстановления, организации уменьшают влияние аппаратных отказов, сетевых отключений, программных сбоев и перерывов на обслуживание.
Больше гибкости обслуживания
Переключение поддерживает плановое обслуживание. Администраторы могут перенести сервис с одного узла на другой, обновить основную систему, проверить изменения и затем вернуть сервис обратно.
Это уменьшает потребность в долгих окнах обслуживания. Обновления также становятся безопаснее, потому что сервис остается доступным через резервные ресурсы.
Повышение доверия пользователей
Пользователи могут не видеть сам процесс, но они замечают, что сервисы остаются доступными. Надежные системы повышают доверие клиентов, продуктивность сотрудников и уверенность в цифровой инфраструктуре.
Для критических коммуникационных, промышленных и бизнес-платформ доступность — не только техническая метрика. Это часть качества сервиса.
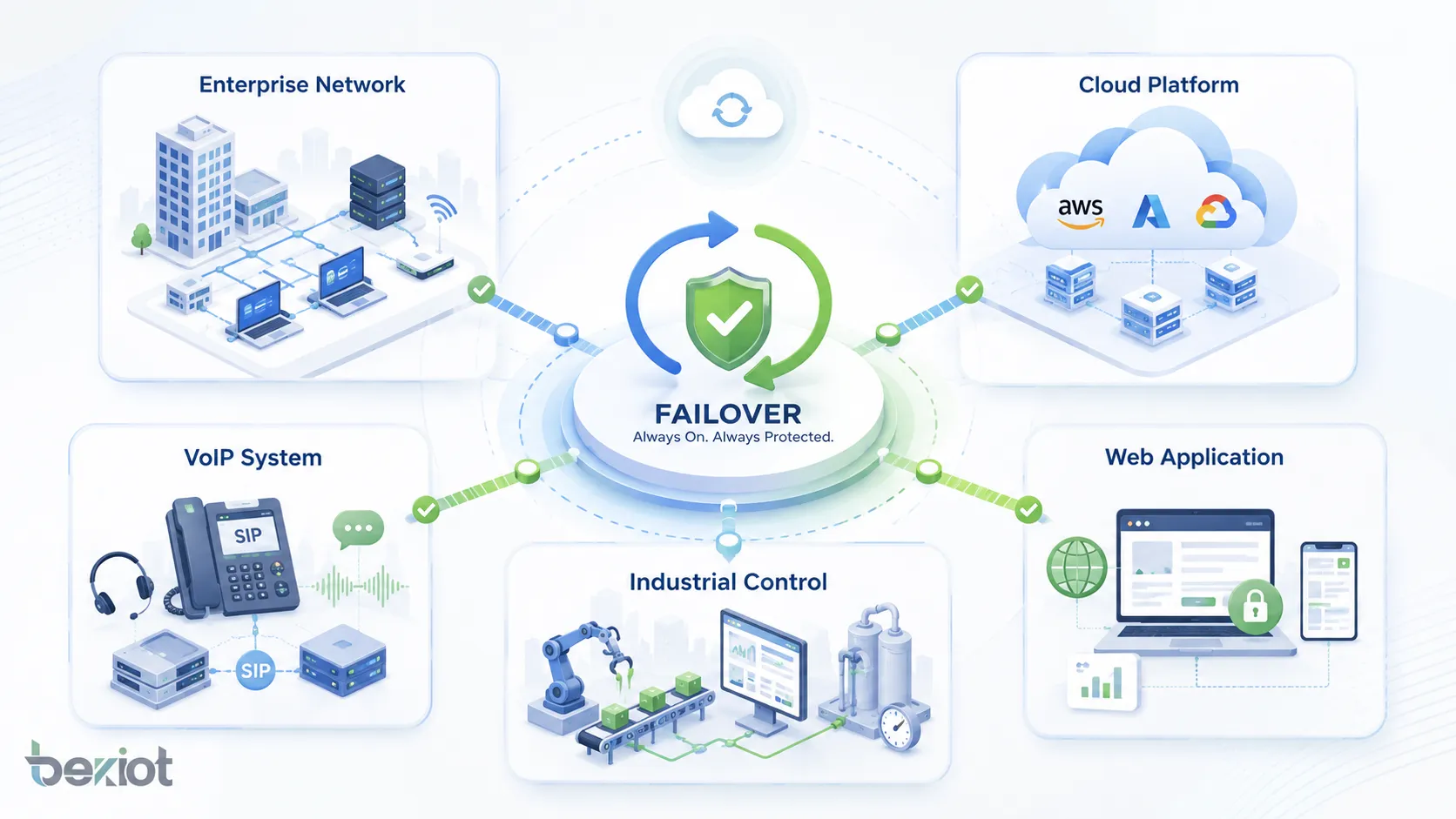
Применение в разных системах
Переключение используется везде, где важна непрерывность. Конкретный дизайн зависит от типа системы, но цель остается одной: избежать прерывания сервиса при отказе.
Корпоративные сети
Корпоративные сети используют переключение для интернет-каналов, firewall, маршрутизаторов, коммутаторов, VPN-туннелей, беспроводных контроллеров и связи филиалов. Если один путь отказывает, трафик переходит на другой.
В организациях с несколькими филиалами это помогает удаленным офисам оставаться подключенными к облачным сервисам, дата-центрам, коммуникационным системам и бизнес-приложениям.
Дата-центры и облачные платформы
Дата-центры применяют переключение для серверов, хранения, баз данных, кластеров виртуализации, питания, охлаждения и сетевых фабрик. Облака используют зоны доступности, региональное переключение, балансировщики, группы автомасштабирования и управляемые реплики баз данных.
При правильном планировании эти решения помогают приложениям пережить отказ оборудования, хоста, стойки или даже регионального сервиса.
VoIP и коммуникационные системы
VoIP и SIP используют переключение для SIP-серверов, PBX, шлюзов, SBC, SIP-транков, DNS SRV записей, медиасерверов и сетевых каналов. Если сервер или транк отказывает, вызовы направляются по резервному пути.
Это важно для бизнес-коммуникаций, потому что отказ голосовых сервисов влияет на клиентов, внутреннюю координацию, экстренные вызовы и сервисные операции.
Промышленные и операционные технологии
Промышленные среды используют переключение для SCADA-серверов, сетей управления, мониторинговых платформ, HMI, historians, промышленных шлюзов и коммуникационных каналов. Цель — сохранить доступность производства, контроля и операций безопасности.
Промышленный дизайн должен учитывать детерминированную связь, совместимость устройств, условия среды и безопасные процедуры. Автоматическое переключение не должно создавать опасное поведение оборудования.
Веб-приложения и онлайн-сервисы
Веб-приложения применяют переключение через балансировщики нагрузки, реплицированные серверы приложений, реплики баз данных, CDN, DNS failover и многорегиональное развертывание. Это помогает сайтам и API оставаться доступными при сбое сервера или сети.
Для e-commerce, банков, SaaS, streaming и клиентских порталов переключение защищает выручку и пользовательский опыт при неожиданном отключении.
Распространенные проблемы и риски
Переключение повышает устойчивость, но плохой дизайн создает новые проблемы. Резервная система должна быть протестирована, обновлена, синхронизирована и правильно рассчитана по мощности. Иначе она может не сработать в самый важный момент.
Ложное переключение
Ложное переключение происходит, когда система переходит на резерв, хотя основной сервис фактически не отказал. Причинами могут быть временная потеря пакетов, медленный ответ, перегруженный мониторинг или слишком агрессивные пороги.
Ложное переключение может зря прервать пользователей. Проверки работоспособности должны подтверждать настоящий отказ сервиса до выполнения переключения.
Состояние split-brain
Split-brain возникает, когда два узла одновременно считают себя активным основным узлом. Это может случиться, если heartbeat-связь нарушена, но обе системы продолжают работать.
Split-brain опасен для баз данных, хранения и кластеров, потому что вызывает повреждение данных или конфликтующие записи. Кворум, fencing и правильный дизайн кластера уменьшают риск.
Проблемы емкости резерва
Резервный ресурс должен иметь достаточно емкости для нагрузки после переключения. Если резерв слишком мал, сервис может оставаться онлайн формально, но работать плохо.
Планирование емкости должно учитывать пиковую нагрузку, рост, деградированный режим и вероятность нескольких одновременных отказов.
Непроверенные планы восстановления
Дизайн переключения, который никогда не тестировался, ненадежен. Дрейф конфигурации, истекшие сертификаты, старые backup-копии, изменения firewall, DNS-кэш, отсутствующие лицензии или старые версии ПО могут помешать восстановлению.
Регулярные учения необходимы. Тесты по возможности должны включать плановое переключение и сценарии незапланированного отказа.
Лучшие практики надежного внедрения
Переключение должно проектироваться как часть более широкой стратегии высокой доступности и аварийного восстановления. Оно включает архитектурное планирование, мониторинг, документацию, тесты и постоянное улучшение.
Сначала определить критические сервисы
Не каждой системе нужен одинаковый уровень переключения. Организация должна определить, какие сервисы критичны, как простой влияет на операции и какие цели восстановления нужны.
Это помогает расставить приоритеты инвестиций. Критические системы могут требовать автоматического переключения и географического резервирования, а менее критичным достаточно backup и ручного восстановления.
Устранить скрытые единые точки отказа
Переключение может ослабляться скрытыми зависимостями. Резервный сервер может зависеть от того же хранилища, питания, коммутатора, DNS-сервиса или системы аутентификации, что и основной сервер.
Архитектурный обзор должен находить эти зависимости. Настоящая устойчивость требует резервирования по всему пути сервиса, а не только на видимом прикладном уровне.
Поддерживать синхронизацию конфигурации
Основные и резервные системы должны иметь согласованную конфигурацию. Различия в версии ПО, правилах firewall, сертификатах, маршрутизации, пользовательских данных или настройках приложения могут привести к неудачному переключению.
Инструменты управления конфигурацией, шаблоны, backup и контроль изменений помогают сохранять согласованность. После крупных изменений готовность к переключению нужно проверять повторно.
Регулярно тестировать переключение
Регулярные тесты подтверждают работу переключения в реальных условиях. Нужно проверять время обнаружения, время переключения, согласованность данных, поведение приложения, доступ пользователей, журналы и процедуру failback.
Тестирование должно документироваться. Каждый тест должен фиксировать, что проверялось, что произошло, что не сработало и какие улучшения нужны.
Failback и восстановление после переключения
Переключение — только часть восстановления. После ремонта основной системы организация должна решить, нужно ли возвращать сервис обратно и как это сделать. Такой процесс называется failback.
Когда выполнять failback
Failback не должен выполняться слишком быстро. Исходная основная система должна быть полностью отремонтирована, протестирована, синхронизирована и проверена до возврата трафика. Поспешный возврат может вызвать новый отказ и новую паузу.
Некоторые организации оставляют резерв активным до следующего окна обслуживания. Это позволяет выполнить контролируемый возврат вместо немедленного переключения.
Синхронизация данных и состояния
Перед failback данные, созданные во время работы на резерве, должны быть синхронизированы обратно в исходную основную систему. Это особенно важно для баз данных, файлов, транзакций, пользовательских сеансов и изменений конфигурации.
Без правильной синхронизации failback может вызвать потерю данных, устаревшие записи или непоследовательное поведение сервиса.
Разбор после инцидента
После события переключения команды должны разобрать произошедшее. Разбор включает причину отказа, время обнаружения, результат переключения, влияние на пользователей, производительность резерва, коммуникации и действия по улучшению.
Так переключение становится не разовым событием восстановления, а постоянным процессом повышения надежности.
FAQ
Что такое отказоустойчивое переключение?
Это механизм надежности, который переводит сервисы, трафик, рабочие нагрузки или операции с отказавшего основного компонента на резервный компонент. Он сокращает простой и поддерживает непрерывность сервиса.
В чем разница между failover и backup?
Backup хранит данные или конфигурацию для восстановления. Failover переводит активный сервис на другой ресурс при отказе. Backup помогает восстановить информацию, а failover помогает сохранить работу сервиса.
Что такое active-passive failover?
Active-passive failover использует одну активную систему и одну резервную систему. Резерв принимает сервис только при отказе активной системы или ее выводе на обслуживание.
Что такое active-active failover?
Active-active failover использует несколько систем, которые одновременно обрабатывают трафик. Если одна система отказывает, остальные продолжают обслуживать пользователей и принимают дополнительную нагрузку.
Где обычно применяется failover?
Он применяется в корпоративных сетях, облачных платформах, дата-центрах, базах данных, веб-приложениях, VoIP-системах, firewall, маршрутизаторах, системах хранения и промышленных платформах управления.
Как тестировать failover?
Его можно тестировать, имитируя отказ основной системы, контролируемо отключая сетевые пути, выключая тестовые узлы, запуская переключение для обслуживания, проверяя смену сервиса, подтверждая согласованность данных и анализируя журналы после восстановления.







