

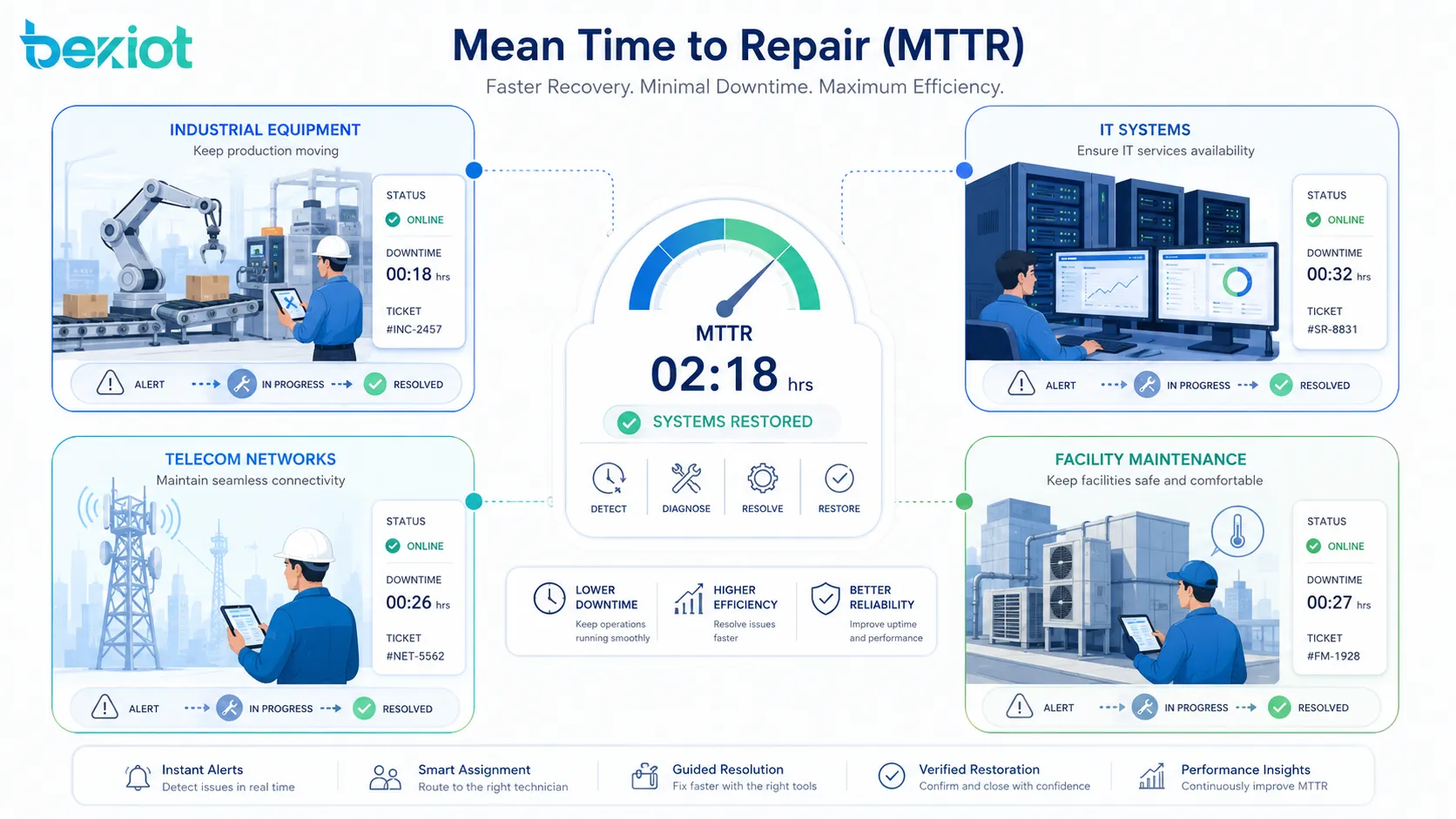
Mean Time to Repair, чаще сокращаемое как MTTR, — это показатель технического обслуживания и надежности, который измеряет среднее время, необходимое для возвращения отказавшего актива, устройства, машины, программного сервиса, сетевого компонента или производственной системы в нормальную работу. Он сосредоточен на процессе ремонта после возникновения отказа и важен для контроля простоя, эффективности сервиса, операционной устойчивости и планирования обслуживания.
На заводах, в дата-центрах, телекоммуникационных сетях, транспортных системах, энергетических объектах, больницах, зданиях и ИТ-средах отказы невозможно полностью исключить. Важно, насколько быстро организация обнаруживает проблему, диагностирует причину, выполняет ремонт, проверяет результат и возвращает систему в сервис. MTTR помогает измерять эту способность к восстановлению.
Базовое значение в управлении надежностью
Mean Time to Repair показывает среднюю продолжительность ремонта по нескольким событиям отказа. Это не время между отказами и не суммарный простой всей системы за длительный период. Показатель отвечает на практический вопрос: когда что-то выходит из строя, сколько обычно занимает восстановление?
Метрика используется инженерами по обслуживанию, управляющими объектами, ИТ-службами, инженерами по надежности, производителями оборудования и операционными руководителями. Более низкое MTTR обычно означает более быстрое восстановление, лучшую реакцию обслуживания, готовность запасных частей, более понятные процедуры и более эффективную диагностику.
Что именно измеряет MTTR
MTTR обычно включает активное время ремонта, необходимое для возврата актива в рабочее состояние. В зависимости от принятого определения оно может включать подтверждение отказа, диагностику, замену запасных частей, восстановление конфигурации, функциональные испытания и окончательное восстановление сервиса.
Например, если производственная машина остановилась из-за неисправного датчика, время ремонта может включать выезд техника, проверку датчика, замену, калибровку и проверку перезапуска. Если отказал сервер, оно может включать анализ инцидента, замену компонента, восстановление данных, перезагрузку и проверку сервиса.
Почему определение должно быть ясным
Разные организации могут рассчитывать MTTR немного по-разному. Одни считают с момента сообщения о неисправности, другие — с начала ремонта. Одни включают ожидание запасных частей, другие учитывают только фактическое техническое время ремонта.
Поэтому перед сравнением эффективности MTTR нужно определить однозначно. Без единого подхода показатель может вводить в заблуждение. Команда может казаться медленной только потому, что в расчет включены ожидание, согласование или дорога, а другая команда измеряет только реальную ремонтную работу.
Как работает расчет
Стандартная формула MTTR проста. Нужно сложить время ремонта по всем событиям за выбранный период и разделить сумму на количество ремонтных событий. Результат показывает среднее время, необходимое для восстановления отказавшего актива или системы.
Например, если пять ремонтов заняли 2 часа, 3 часа, 1 час, 4 часа и 5 часов, общее время ремонта равно 15 часам. Деление 15 часов на пять событий дает MTTR 3 часа. Это означает, что один ремонт в среднем занимает 3 часа.
Сбор времени ремонта
Точный MTTR зависит от точных ремонтных записей. Команды должны фиксировать, когда отказ обнаружен, когда начат ремонт, какие действия выполнены, когда сервис восстановлен и была ли проверена работоспособность. Системы управления обслуживанием, тикет-платформы, журналы SCADA, service desk и CMMS помогают собирать эти данные.
Ручные записи тоже возможны, но они должны быть последовательными. Если техники забывают закрывать наряды, указывают неполное время или по-разному классифицируют инциденты, итоговое MTTR может не отражать реальную эксплуатационную эффективность.
Простой пример ремонта оборудования
Представим объект с вентиляционной установкой, которая отказала три раза за месяц. Первый ремонт занял 90 минут, второй 120 минут, третий 60 минут. Общее время ремонта составило 270 минут.
По формуле MTTR 270 минут, разделенные на 3 ремонтных события, дают 90 минут. Следовательно, MTTR этой вентиляционной установки равен 90 минутам. Управляющие объектом могут использовать это число для оценки реакции, нагрузки техников, доступности запасных частей и необходимости профилактики.
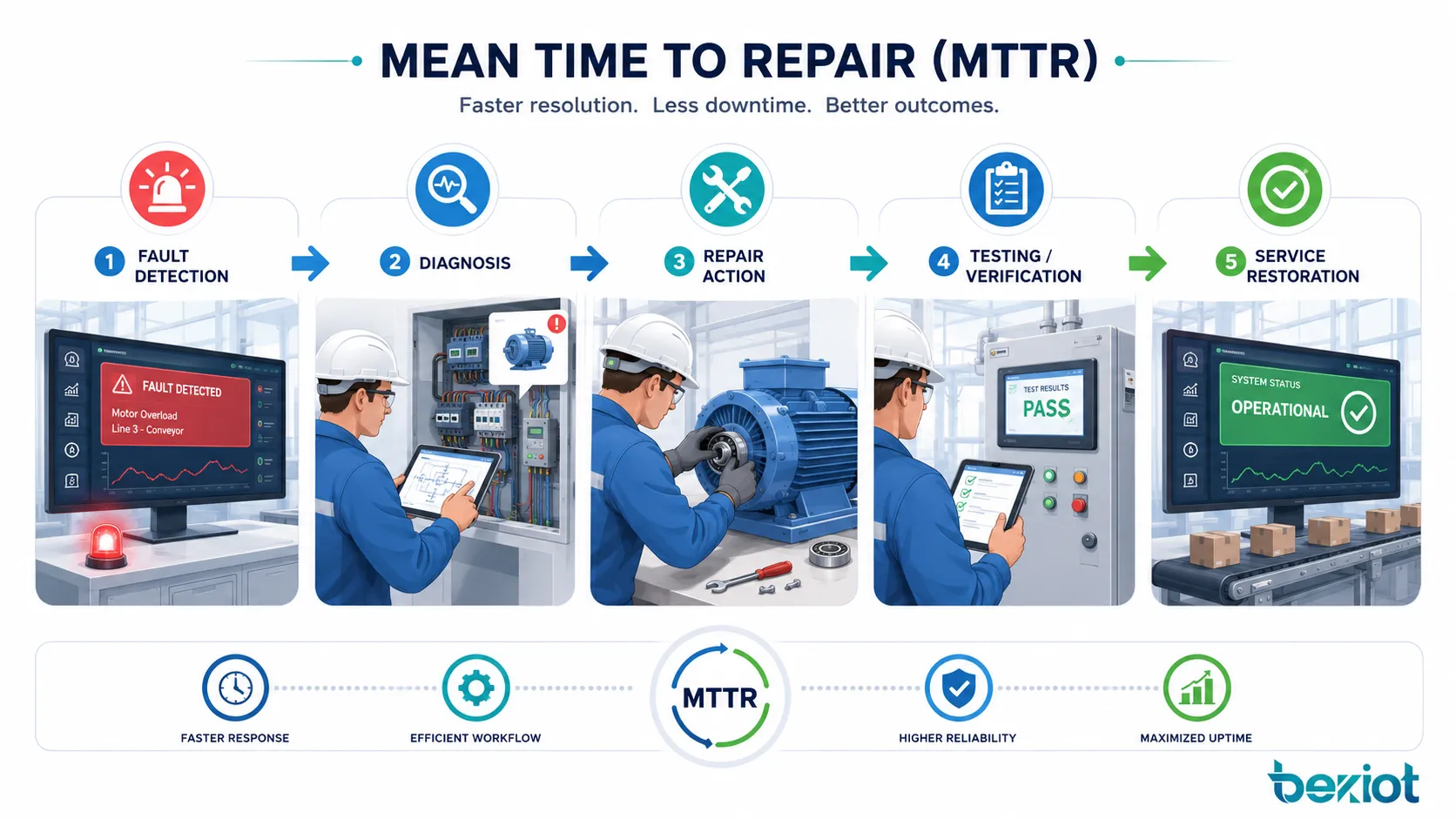
Что происходит во время ремонтного цикла
MTTR — это не только математическое среднее. Он отражает полный рабочий процесс ремонта за каждым отказом. Долгое время может быть связано с медленным обнаружением, неясными шагами диагностики, отсутствием запасных частей, плохой документацией, сложным доступом к оборудованию или нехваткой обученного персонала.
Понимание ремонтного цикла помогает устранять реальные причины простоя, а не смотреть только на итоговое число.
Обнаружение и сообщение об отказе
Ремонтный цикл начинается, когда отказ обнаружен. В одних системах обнаружение автоматическое — через тревоги, датчики, панели мониторинга, самодиагностику или коды ошибок. В других случаях оператор, пользователь или техник замечает проблему и сообщает о ней вручную.
Быстрое обнаружение снижает общий эффект отказа. Если неисправность машины найдена сразу, ремонт начинается до того, как проблема повлияет на качество, безопасность или последующее оборудование. В ИТ и сетевых операциях автоматические оповещения значительно сокращают время реакции.
Диагностика и определение первопричины
После обнаружения техники или инженеры должны определить причину. Диагностика может включать визуальный осмотр, анализ журналов, электрические испытания, механические проверки, анализ ПО, трассировку сети или сравнение с историей отказов.
Диагностика часто является одним из главных факторов MTTR. Команда с хорошей документацией, понятными кодами ошибок, удаленным мониторингом и опытными специалистами быстрее находит проблемы, чем команда, полагающаяся только на метод проб и ошибок.
Ремонт, замена и проверка
Фактический ремонт может включать замену компонента, перезапуск ПО, исправление конфигурации, ремонт кабеля, механическую регулировку, восстановление прошивки, очистку, смазку, повторную калибровку или полную замену оборудования.
После завершения ремонта систему следует протестировать до возврата в обычную работу. Проверка может включать пусковые тесты, проверки безопасности, пробный производственный запуск, тесты сетевого соединения, подтверждение сброса тревоги или приемку пользователем. Без проверки система может выглядеть исправной и вскоре снова отказать.
Почему эта метрика важна
MTTR важен, потому что простой имеет реальные последствия. Он может остановить производство, задержать оказание услуг, снизить удовлетворенность клиентов, увеличить расходы, создать риски безопасности и нарушить непрерывность бизнеса. Отслеживая время ремонта, организации находят слабые места обслуживания и улучшают восстановление.
MTTR наиболее полезен, когда приводит к действиям. Цель не только в расчете среднего времени ремонта, но и в понимании, почему ремонт занимает столько времени и как улучшить процесс.
Снижение влияния простоя
Более низкий MTTR означает, что оборудование или системы быстрее возвращаются к работе после отказа. В производстве это снижает потери выпуска. В телекоммуникациях и ИТ уменьшает прерывание сервиса. В зданиях и инфраструктуре повышает комфорт, безопасность и доступность.
Снижение простоя особенно важно для критически важных систем. Платформы экстренной связи, распределение электроэнергии, медицинские системы, управление движением, системы безопасности и производственные линии требуют быстрого восстановления, так как отказ может иметь серьезные последствия.
Повышение эффективности обслуживания
MTTR дает службам обслуживания способ оценить эффективность реакции на проблемы. Если среднее время растет, руководители могут выяснить, связана ли причина с задержкой запчастей, недостатком обучения, трудным доступом, медленной эскалацией или неясными инструкциями.
Сравнивая MTTR по типам оборудования, площадкам, сменам или сервисным командам, организация определяет зоны улучшения. Это поддерживает лучшее планирование персонала, целевое обучение, улучшенную документацию и более разумное управление запасными частями.
Поддержка целей надежности и доступности
Доступность системы зависит и от частоты отказов, и от скорости восстановления. Даже если оборудование иногда выходит из строя, быстрый ремонт помогает сохранять приемлемую доступность сервиса. Поэтому MTTR часто используют вместе с MTBF, процентом uptime, целями уровня сервиса и надежности.
Система с частыми отказами и долгим ремонтом будет иметь плохую доступность. Система с редкими отказами и быстрым ремонтом обычно намного лучше с точки зрения непрерывности работы.
Польза для эксплуатации и обслуживания
MTTR ценен тем, что связывает техническую эффективность обслуживания с бизнес-результатами. Он помогает переходить от реактивного ремонта к структурированному улучшению. Вместо общих разговоров о простое руководители могут использовать данные ремонта для решений.
Лучшее планирование запасных частей
Если ремонт затягивается из-за отсутствия запчастей, данные MTTR показывают проблему. Команды могут определить критические компоненты, задать минимальные запасы, улучшить соглашения с поставщиками или использовать сменные модули для более быстрого восстановления.
Для дорогих или связанных с безопасностью активов стоимость запаса может быть намного ниже стоимости длительного простоя. Анализ MTTR помогает обосновать это измеримыми доказательствами.
Более ясное управление уровнем сервиса
В аутсорсинговом обслуживании, ИТ-поддержке, телеком-сервисах и эксплуатации объектов MTTR может поддерживать SLA. Он дает поставщику и заказчику измеримый показатель ремонтной эффективности.
Цели обслуживания должны быть реалистичными. Простое устройство контроля доступа нельзя сравнивать со сложной производственной линией, крупной HVAC-системой или сетевым отказом на нескольких площадках. Нужно учитывать сложность, местоположение, риск и доступ.
Более эффективное обучение и документация
Высокий MTTR может показывать, что техникам нужны обучение или более ясные инструкции. Если один тип отказа снова и снова устраняется долго, организация может создать стандартные руководства, визуальные инструкции, диагностические чек-листы или процедуры удаленной поддержки.
Хорошая документация уменьшает зависимость от индивидуального опыта, помогает новым специалистам ремонтировать увереннее и снижает риск повторных ошибок.
Типичные применения в разных отраслях
Mean Time to Repair используется во многих отраслях, потому что почти каждая организация зависит от активов, систем, устройств или сервисов, которые могут отказать. Конкретный процесс ремонта различается, но потребность измерять и улучшать время восстановления универсальна.
Производство и промышленное оборудование
На производственных предприятиях MTTR измеряет ремонт производственных линий, двигателей, насосов, конвейеров, роботов, станков CNC, упаковочного оборудования, датчиков, шкафов управления и инженерных систем.
Снижение MTTR улучшает непрерывность производства, уменьшает сверхурочную работу, повышает использование активов и поддерживает бережливое обслуживание. Оно также помогает понять, какие машины создают наибольшую ремонтную нагрузку.
ИТ-системы и дата-центры
В ИТ MTTR применяется к серверам, системам хранения, приложениям, базам данных, облачным сервисам, межсетевым экранам, коммутаторам, маршрутизаторам и пользовательским платформам. Он часто используется в управлении инцидентами и Site Reliability Engineering.
Для цифровых сервисов ремонт может означать восстановление программной функции, а не замену физической детали. Процесс включает анализ логов, откат, установку патча, failover, исправление конфигурации, перезапуск или восстановление из резервной копии.
Телекоммуникации и сетевая инфраструктура
Операторы связи и корпоративные сетевые команды используют MTTR для оценки восстановления базовых станций, оптоволоконных линий, оборудования передачи, IP-сетей, коммуникационных шлюзов, маршрутизаторов, коммутаторов и сервисных платформ.
Сетевые отказы могут затронуть многих пользователей сразу. Быстрый ремонт и точная локализация критичны для качества сервиса. Удаленный мониторинг, резервные линии, понятная эскалация и координация выездных работ помогают снижать MTTR.
Объекты, здания и коммунальные системы
Facility-менеджеры используют MTTR для HVAC, лифтов, насосов, управления освещением, контроля доступа, интерфейсов пожарной сигнализации, охранного оборудования, электроснабжения, водных систем и автоматизации зданий.
В зданиях и коммунальной среде MTTR связан с комфортом, безопасностью, соблюдением норм и непрерывностью обслуживания. Долгий ремонт может затронуть арендаторов, посетителей, производственные зоны или пользователей общественной инфраструктуры.
Сравнение MTTR с родственными метриками
MTTR часто рассматривается вместе с другими метриками надежности и обслуживания. Понимание различий помогает выбрать правильный показатель. MTTR фокусируется на скорости ремонта, а другие метрики — на частоте отказов, доступности сервиса или времени реакции на инцидент.
| Метрика | Значение | Основное назначение |
|---|---|---|
| MTTR | Среднее время ремонта | Измеряет среднее время восстановления отказавшего актива или системы |
| MTBF | Среднее время между отказами | Измеряет среднее время работы между отказами |
| MTTF | Среднее время до отказа | Оценивает ожидаемый срок службы до отказа для неремонтируемых элементов |
| MTTA | Среднее время подтверждения | Измеряет время, нужное для обнаружения и подтверждения инцидента |
| Availability | Коэффициент эксплуатационной доступности | Показывает, как часто система доступна для использования |
MTTR и MTBF
MTBF измеряет, как часто происходят отказы, а MTTR — как быстро они ремонтируются. Оба показателя важны. Система может иметь высокий MTBF, но вызывать серьезные нарушения, если каждый ремонт занимает долгое время.
Машина, которая выходит из строя только дважды в год, все равно может быть проблемой, если каждый ремонт длится три дня. Менее критичное устройство может ломаться чаще, но ремонтироваться за минуты. MTBF и MTTR нужно анализировать вместе.
MTTR и доступность
Доступность сильно зависит от MTTR. Если время ремонта сокращается при той же частоте отказов, доступность может вырасти. Поэтому снижение MTTR — распространенная стратегия для систем, которые нельзя сразу перепроектировать для меньшего числа отказов.
Практически команды улучшают доступность, предотвращая отказы, ремонтируя быстрее, добавляя резервирование, улучшая мониторинг или проектируя системы, продолжающие работу в деградированном режиме во время ремонта.
Как сократить время ремонта
Снижение MTTR требует не просто просить техников работать быстрее. Устойчивое улучшение обычно приходит через лучший дизайн системы, лучшую информацию, подготовку и координацию. Цель — убрать задержки из ремонтного процесса.
Использовать мониторинг и раннее обнаружение
Автоматический мониторинг обнаруживает ненормальные условия до крупных отказов. Датчики, журналы, тревоги, панели, системы контроля состояния и предиктивное обслуживание помогают реагировать раньше и диагностировать быстрее.
Раннее обнаружение особенно полезно при признаках вибрации, роста температуры, изменения давления, колебания напряжения, кодов ошибок или нестабильной связи. Реакция на эти сигналы снижает и время ремонта, и эффект отказа.
Стандартизировать процедуры диагностики
Скорость ремонта растет, когда техники следуют ясным процедурам. Чек-листы, деревья отказов, руководства, схемы проводки, списки запчастей, шаги восстановления ПО и правила эскалации уменьшают неопределенность.
Стандартные процедуры делают работу более стабильной между техниками и сменами. Они помогают обрабатывать одну и ту же проблему одинаково надежно каждый раз.
Улучшить доступ к запчастям и инструментам
Многие ремонты задерживаются не из-за сложности отказа, а из-за отсутствия детали, инструмента, пароля, образа ПО, кабеля или тестового прибора. Ремонтные наборы и критические запасы значительно сокращают восстановление.
Для распределенных площадок местные запчасти, региональные сервисные центры или модульная замена помогают избежать долгих поездок и доставки. В цифровых системах готовые резервные копии и шаблоны конфигурации выполняют схожую роль.
Ограничения и неправильное использование MTTR
Хотя MTTR полезен, он не должен быть единственным показателем обслуживания. Низкий MTTR не всегда означает надежную систему. Возможно, команда просто хорошо ремонтирует повторяющиеся отказы. Если один и тот же актив продолжает ломаться, первопричина требует внимания.
MTTR может скрывать разброс. Среднее значение может выглядеть приемлемым, хотя несколько критических инцидентов заняли намного больше времени. Для важных систем нужно отдельно смотреть распределение времени, худшие случаи, повторные отказы и высокорисковое оборудование.
Не игнорировать профилактику отказов
Скорость ремонта важна, но предотвращение предотвратимых отказов обычно лучше. Профилактика, контроль состояния, улучшение конструкции, правильная установка, обучение операторов и защита среды снижают частоту отказов.
Сильная стратегия обслуживания должна сочетать быстрый ремонт и долгосрочную надежность. MTTR показывает скорость восстановления, но без анализа причин не объясняет, почему отказы происходят.
Не сравнивать без контекста
Сравнение MTTR между разными системами может вводить в заблуждение. Простая замена датчика не сопоставима с ремонтом турбины, сетевым сбоем, отказом лифта или восстановлением базы данных. У каждого актива свои сложность, риск, доступ и требования.
Осмысленные сравнения выполняются внутри похожих групп оборудования, похожих условий или одного актива во времени. Так команды видят реальные улучшения, а не создают несправедливые оценки.
Лучшие практики практического использования
Чтобы эффективно использовать MTTR, организация должна ясно определить метрику, собирать надежные данные, анализировать причины долгого ремонта и связывать выводы с действиями. Показатель должен помогать решениям, а не быть только числом в отчете.
Определить начальную и конечную точки
Каждая организация должна решить, когда начинается и заканчивается время ремонта. Оно может начинаться при сообщении об отказе, открытии тикета, прибытии техника или начале активного ремонта, а заканчиваться при перезапуске, завершении тестов или подтверждении пользователя.
Выбранное определение должно соответствовать цели измерения. Для улучшения клиентского сервиса более важен общий простой. Для оценки эффективности техников лучше подходит активное время ремонта.
Сегментировать данные
Вместо одного общего MTTR по всем активам команды должны сегментировать данные по типу оборудования, площадке, категории отказа, серьезности, команде, смене, поставщику или функции системы. Так метрика становится полезной и применимой.
Объект может обнаружить, что насосы ремонтируются быстро, а лифты медленно из-за внешних поставщиков запчастей. ИТ-команда может увидеть, что инциденты приложений решаются быстро, а сетевые требуют долгой диагностики. Сегментация показывает, где начинать улучшение.
Связать MTTR с анализом первопричин
При высоком времени ремонта команды должны выяснить причину. Был ли отказ труден для диагностики? Не хватало документации? Не было запасной части? Задержалось согласование? Не работал удаленный доступ? Было ли оборудование труднодоступным?
Анализ первопричин превращает MTTR из пассивного измерения в активный инструмент улучшения. Со временем это снижает простой, повышает надежность и делает планирование обслуживания более предсказуемым.
FAQ
Что означает Mean Time to Repair?
Mean Time to Repair — это среднее время, необходимое для восстановления отказавшего актива, системы, устройства или сервиса до нормальной работы. Оно рассчитывается как общее время ремонта, деленное на количество ремонтных событий за заданный период.
MTTR — это то же самое, что простой?
Не всегда. MTTR обычно фокусируется на длительности ремонта, а простой может включать обнаружение, задержку сообщения, ожидание, задержку запчастей, согласование и перезапуск. Организация должна точно определить, что входит в показатель.
Какое значение MTTR считается хорошим?
Хороший MTTR зависит от оборудования, отрасли, требований сервиса и серьезности отказа. Для перезапуска цифрового сервиса могут ожидаться минуты, для сложного промышленного оборудования — несколько часов. Лучший ориентир — сравнение с похожими активами или прошлой производительностью.
Как компания может снизить MTTR?
Компания может снизить MTTR, улучшив мониторинг, ускорив обнаружение, стандартизировав диагностику, обучив техников, обеспечив критические запчасти, используя удаленную диагностику, улучшив документацию и упростив доступ к оборудованию.
Почему MTTR важен для надежности?
MTTR важен, потому что скорость ремонта напрямую влияет на простой и доступность. Даже надежные системы могут отказывать, поэтому быстрое восстановление снижает операционные последствия, перебои сервиса, производственные потери и недовольство клиентов.
В чем разница между MTTR и MTBF?
MTTR измеряет длительность ремонта после отказа. MTBF измеряет среднее время между отказами. MTTR фокусируется на скорости восстановления, MTBF — на частоте отказов. Оба показателя помогают понять надежность и доступность.







