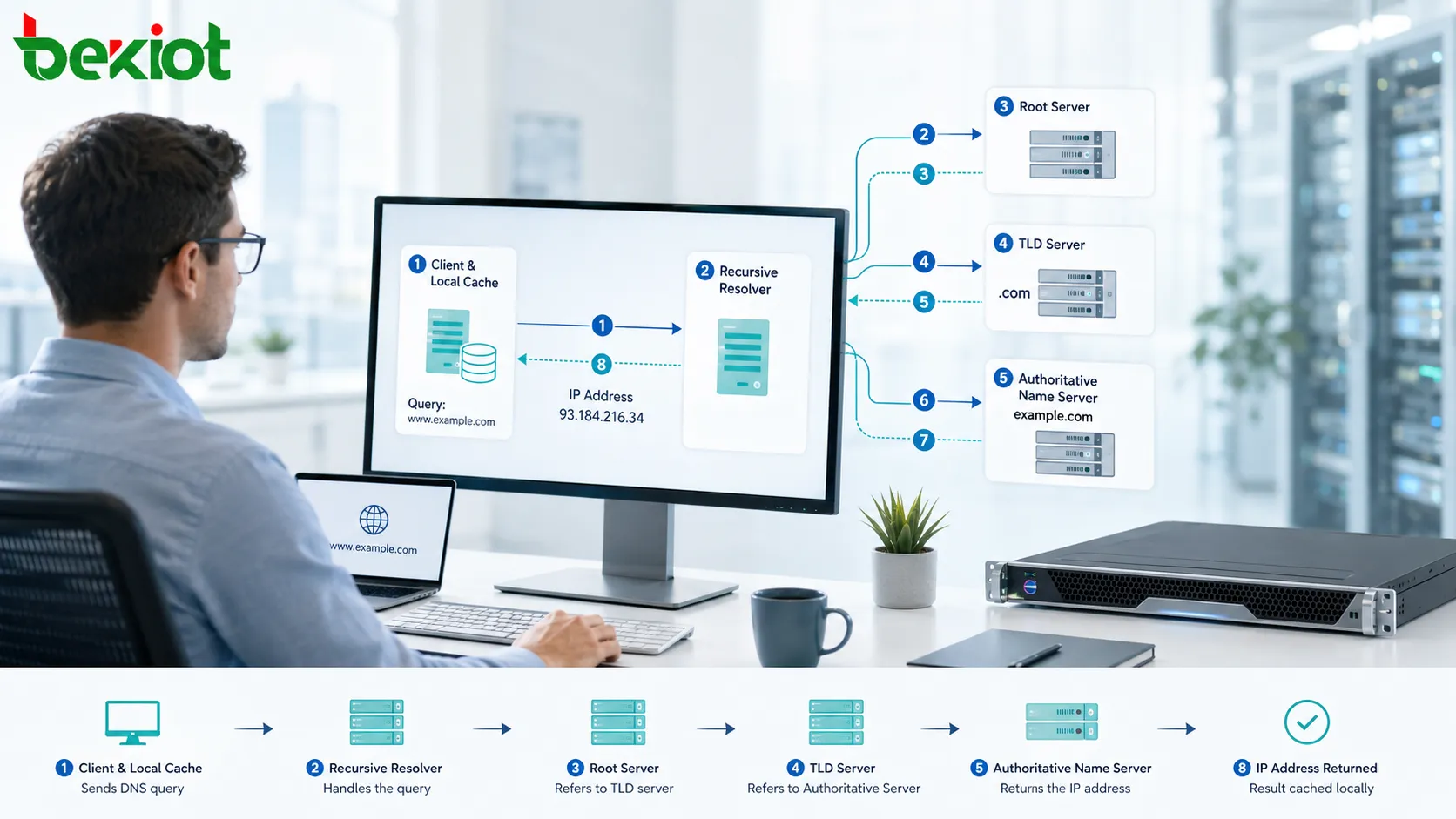
Компания с одним офисом часто может решить сетевую проблему установкой коммутатора, обновлением маршрутизатора или изменением правила межсетевого экрана. Организация с множеством площадок сталкивается с другой задачей: каждый филиал, завод, склад, кампус, ЦОД, облачный регион и удалённая точка доступа становятся частью единой операционной системы. Если соединять эти площадки без планирования, появляются разрозненный доступ, дублирование ресурсов, непоследовательная безопасность, медленное устранение неисправностей и нестабильная совместная работа.
Отраслевой взгляд:ценность распределённой сети уже не ограничивается базовой связностью. Современные организации используют её для доступа к облаку, унифицированных коммуникаций, удалённого мониторинга, видеонаблюдения, IoT-платформ, централизованного управления, аварийного восстановления, доступа по принципам zero trust и бизнес-приложений реального времени. Вопрос не только в том, как соединить разные места, а в том, как превратить эти соединения в управляемую и интеллектуальную сервисную основу.
Полное использование такой архитектуры означает отношение к ней как к стратегической цифровой платформе. Каждая площадка не должна работать как отдельный остров. Она должна делиться нужными ресурсами, соблюдать правильные правила безопасности, обмениваться нужными данными и сохранять устойчивость при отказе каналов, устройств или сервисов.
От подключения филиалов к операционной интеграции
Первоначальная цель соединения нескольких площадок обычно была простой: позволить пользователям филиалов обращаться к системам головного офиса. Для этого применялись арендованные линии, VPN-туннели, частные WAN-каналы или соединения точка-точка. Это решало вопрос доступа, но не всегда создавало гибкие цифровые операции.
Сегодня операционная среда сложнее. Приложения могут работать в публичном облаке, частном облаке, на edge-серверах, в локальных ЦОД или на SaaS-платформах. Пользователи работают из офисов, автомобилей, удалённых домов, полевых объектов и мобильных устройств. Угрозы могут приходить из Интернета, с скомпрометированных конечных точек, из неправильно настроенных облачных сервисов или через внутреннее горизонтальное перемещение.
Поэтому распределённая архитектура должна поддерживать больше, чем передачу трафика. Она должна обеспечивать производительность приложений, доступ на основе личности, централизованные политики, сегментацию, мониторинг, автоматизацию и устойчивость на всех подключённых площадках.

Определить роль каждой площадки
Не все площадки выполняют одинаковую функцию. Головной офис может размещать ключевые бизнес-системы, руководящие команды, серверные комнаты и центральное оборудование безопасности. Завод может отдавать приоритет операционным технологиям, мониторингу производства, промышленным терминалам и локальным системам управления. Склад может быть сосредоточен на штрихкодах, логистических платформах, камерах, беспроводном покрытии и ручных терминалах. Малому офису может требоваться только безопасный доступ к облачным приложениям и общим голосовым сервисам.
Перед оптимизацией каждую площадку следует классифицировать по бизнес-роли, зависимостям приложений, количеству пользователей, типу трафика, требованиям доступности и чувствительности безопасности. Такая классификация помогает определить полосу пропускания, маршрутизацию, резервирование, сегментацию, выбор устройств, глубину мониторинга и модель поддержки.
Без этого шага организации могут избыточно строить малые площадки и недостаточно защищать критические. Сильный проект соотносит уровень сети с бизнес-важностью каждой площадки.
Построить понятную модель подключения
Распределённая среда может использовать MPLS, широкополосный Интернет, 4G/5G, частное волокно, радиорелейные линии, спутник, VPN, SD-WAN или гибридное подключение. Каждый вариант отличается производительностью, стоимостью, надёжностью и управляемостью.
Традиционные частные WAN-каналы дают контролируемую производительность, но могут быть дорогими и медленными в развёртывании. VPN через Интернет гибок и экономичен, но производительность может колебаться. SD-WAN объединяет несколько каналов, направляет трафик по политикам приложений и обеспечивает централизованную оркестрацию. Сотовые каналы подходят для быстрого развёртывания или резерва. Спутник закрывает удалённые объекты без наземной связи.
Лучшей моделью часто становится гибрид. Критические площадки используют два канала. Малые филиалы применяют широкополосный доступ с сотовым резервом. Удалённые промышленные объекты могут использовать частное волокно или беспроводной backhaul. Облачный трафик может идти напрямую в облако, не возвращаясь через головной офис.
Использовать централизованное управление без потери локальной устойчивости
Централизованное управление позволяет администраторам настраивать, контролировать, обновлять и защищать многие площадки из одной платформы. Это снижает ошибки ручной настройки, повышает стандартизацию и делает крупномасштабную эксплуатацию эффективнее.
Но централизация не должна создавать единую точку отказа. Филиал не должен полностью останавливаться только из-за временной потери связи с центральным контроллером. В зависимости от важности площадки могут потребоваться локальный выход, кэшированные политики, резервная маршрутизация, локальный DHCP, локальная пересылка DNS и аварийные каналы связи.
Цель проекта — сбалансированный контроль. Организация должна управлять единообразно из центра, но позволять площадкам продолжать ключевые операции при отказе каналов или контроллера.
Сегментировать трафик по функции и риску
Сегментация необходима в распределённой архитектуре. Пользовательский трафик, голос, видеонаблюдение, гостевой Wi-Fi, промышленные системы управления, платежи, серверный трафик, интерфейсы управления и IoT-устройства не должны находиться в одном пространстве безопасности.
VLAN, VRF, зоны межсетевых экранов, списки контроля доступа, микросегментация, политики zero trust и программно определяемые группы безопасности помогают разделять трафик. Цель — снизить риск, управлять доступом и не дать одной скомпрометированной зоне повлиять на всю организацию.
Сегментация должна следовать бизнес-логике. Например, гость Wi-Fi не должен достигать внутренних серверов. Сеть камер может отправлять видео в хранилище, но не должна обращаться к офисным устройствам. Промышленные терминалы могут требовать строгих путей к системам управления и серверам мониторинга.
Оптимизировать пути приложений
Производительность приложений — одна из главных причин модернизации межплощадочной связности. Пользователи оценивают сеть не по схемам каналов, а по ясности звонков, скорости панелей, синхронизации файлов, стабильности видео и отклику бизнес-систем.
Маршрутизация с учётом приложений выбирает пути по задержке, потере пакетов, джиттеру, полосе и приоритету сервиса. Голос и видео требуют малой задержки и джиттера. Большие файлы терпят задержку, но требуют полосы. Облачные приложения выигрывают от прямого выхода в Интернет. Чувствительные данные могут требовать проверки через шлюзы безопасности.
Инжиниринг трафика должен опираться на реальное поведение приложений. Общая модель «весь трафик через головной офис» становится неэффективной, когда большинство приложений размещено в облаке.
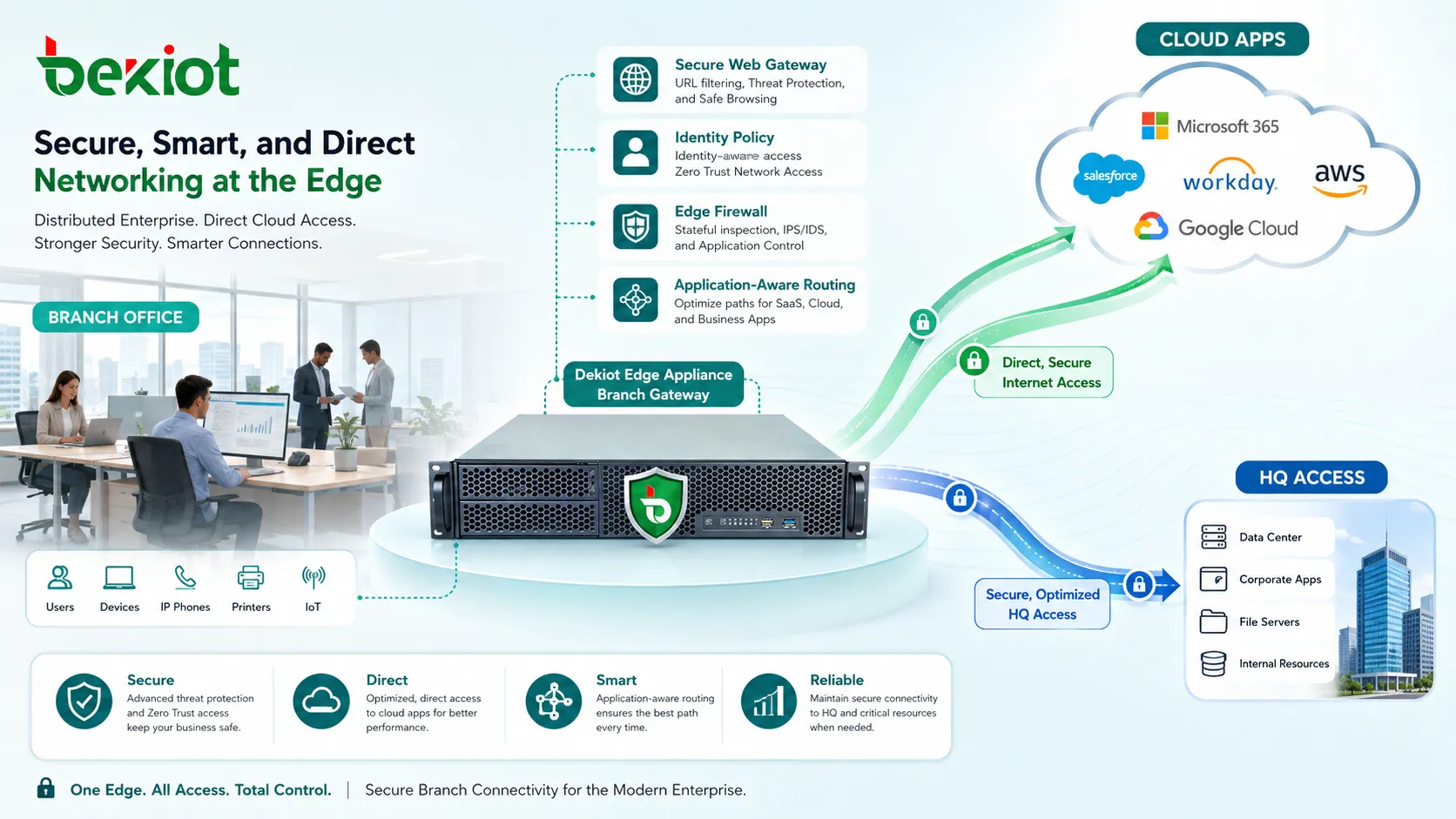
Усилить доступ к облаку и SaaS
Доступ к облаку изменил сетевой дизайн. Многие организации используют SaaS, рабочие нагрузки публичного облака, сервисы идентификации, облачное хранение, удалённые рабочие столы и API-ориентированные бизнес-системы. Если весь облачный трафик принудительно проходит через центральный ЦОД, пользователи получают лишнюю задержку.
Прямой доступ к облаку улучшает производительность, но должен быть защищён. Это может включать защищённые веб-шлюзы, функции CASB, политики на основе идентичности, DNS-безопасность, проверку состояния конечных точек и инспекцию шифрованного трафика там, где это уместно.
Облачную связность также нужно планировать на надёжность. Критические нагрузки могут требовать резервных облачных регионов, выделенных interconnect, резервных Интернет-каналов или политик failover.
Поддерживать унифицированные коммуникации между площадками
Голос, видео, сообщения, конференции, интерком, оповещение и диспетчерские системы часто зависят от одной сетевой основы. Плохая маршрутизация, джиттер, потеря пакетов или ошибка firewall быстро влияют на качество связи.
Хорошо спроектированная распределённая сеть должна классифицировать медиатрафик реального времени, приоритизировать чувствительные к задержке потоки, обеспечивать NAT traversal при необходимости и контролировать показатели качества голоса. Она также должна поддерживать локальную живучесть критической связи, если центральные сервисы недоступны.
Для организаций с множеством площадок унифицированные коммуникации нужно интегрировать с каталогами, планами нумерации, аварийной маршрутизацией, политиками записи и правилами безопасности. Это исключает коммуникационные острова и улучшает координацию в обычной работе и при инцидентах.
Масштабировать видео и IoT
Видеонаблюдение, датчики, контроль доступа, экологический мониторинг, умные счётчики, промышленные терминалы и IoT могут создавать большой объём трафика. Их характеристики безопасности также отличаются от обычных пользовательских устройств.
Чтобы использовать эти системы эффективно, сеть должна определить, где обрабатываются данные. Часть видеоаналитики выполняется на edge. Некоторые записи хранятся локально и синхронизируются с центром. Данные отдельных датчиков отправляются в облако. Не каждый поток должен постоянно проходить через WAN.
Edge-обработка снижает нагрузку на полосу и ускоряет отклик. Центральные платформы дают видимость и управление. Лучший подход зависит от площадки, приложения, ценности данных и требований хранения.
Использовать безопасность на основе политик
Традиционная безопасность часто фокусировалась на периметре площадки. Современным распределённым средам нужен более детальный контроль. Пользователь может обращаться из филиала, домашнего офиса, мобильного устройства или облачного рабочего пространства. Устройство может переходить между сетями. Сервис может работать в нескольких регионах.
Политики должны учитывать личность, состояние устройства, местоположение, приложение, чувствительность данных и уровень риска. Здесь полезны принципы zero trust. Доступ должен предоставляться по проверенному контексту, а не потому, что площадка находится внутри WAN.
Политическая безопасность также улучшает согласованность. Вместо ручной разной настройки каждого firewall и маршрутизатора организация задаёт стандартные модели доступа и распространяет их по площадкам.
Проектировать отказ, а не только нормальную работу
Распределённая система обязательно столкнётся с отказами. Интернет-каналы падают, питание пропадает, устройства зависают, облачные сервисы могут быть недоступны, волокно может быть повреждено, а изменения конфигурации могут вызвать неожиданную маршрутизацию. Настоящая проверка — продолжают ли работать или быстро восстанавливаются критические функции.
Планирование устойчивости должно включать резервные каналы, резервное питание, дублирующие устройства, автоматический failover, локальную живучесть, внеполосное управление, резервные копии конфигурации и процедуры аварийного восстановления. Критические площадки нуждаются в большей защите.
Failover необходимо тестировать. Резервный канал, который никогда не проверялся, может отказать в самый нужный момент. Тесты должны охватывать маршрутизацию, политики безопасности, голос, доступ к приложениям и мониторинговые оповещения.
Повысить видимость с помощью мониторинга и телеметрии
Большими распределёнными средами нельзя управлять ручным наблюдением. Администраторам нужны текущие и исторические данные о статусе каналов, использовании полосы, задержке, потере пакетов, здоровье устройств, производительности приложений, событиях безопасности, пользовательском опыте и изменениях конфигурации.
Мониторинг должен быть многоуровневым. Мониторинг устройств показывает, онлайн ли оборудование. Мониторинг каналов показывает качество транспорта. Мониторинг приложений показывает, могут ли пользователи выполнять задачи. Мониторинг безопасности выявляет подозрительное поведение. Анализ журналов показывает, что изменилось перед инцидентом.
Хорошая видимость сокращает время устранения неисправностей. Вместо вопроса «это сеть?» инженеры видят, проблема ли в DNS, перегрузке WAN, блокировке firewall, сбое облачного сервиса, Wi-Fi или конечной точке.

Автоматизировать повторяющиеся операции
Автоматизация сокращает повторную ручную работу. Типовые задачи включают ввод устройств, шаблоны конфигурации, развертывание политик, обновления прошивки, продление сертификатов, резервное копирование конфигурации, реакцию на оповещения и проверки соответствия.
Шаблонная настройка особенно ценна для новых филиалов. Вместо ручного восстановления маршрутов, VLAN, VPN, правил firewall и мониторинга администраторы применяют стандартный профиль и меняют только параметры площадки.
Автоматизация должна контролироваться через утверждение, отслеживание версий, тестирование и откат. Быстрое внедрение полезно только тогда, когда изменения надёжны.
Стандартизировать адресацию и именование
Планирование адресов усложняется, когда многие площадки растут независимо. Пересекающиеся IP-диапазоны, неясные имена VLAN, несогласованные DNS-записи и недокументированные подсети вызывают конфликты маршрутизации и задержки диагностики.
Центральный план адресации должен определять коды площадок, IP-блоки, диапазоны VLAN, loopback-адреса, управляющие сети, DHCP-области и резервные диапазоны. Правила именования должны ясно показывать площадку, тип устройства, функцию и роль.
Хорошие имена и адреса уменьшают путаницу. Они также облегчают автоматизацию, мониторинг, политики firewall и ведение документации.
Последовательно планировать Wi-Fi и edge-доступ
Многие площадки сильно зависят от Wi-Fi, ручных терминалов, мобильных устройств, сканеров штрихкодов, планшетов, камер, датчиков и гостевого доступа. Беспроводной дизайн должен быть достаточно единообразным для роуминга, безопасности и управления, но гибким для местной планировки здания.
Централизованные беспроводные контроллеры или облачно управляемые точки доступа упрощают развертывание политик. Но радиопланирование всё равно требует обследования площадки, проектирования каналов, анализа помех и планирования ёмкости.
Edge-доступ также должен учитывать физическую безопасность. Сетевые порты в публичных зонах, складах и промышленных местах не должны давать неограниченный внутренний доступ.
Осторожно подключать операционные технологии
Промышленные и инженерные системы часто включают операционные технологии: PLC, SCADA-терминалы, датчики, контроль доступа, энергосистемы и производственное оборудование. Эти системы могут требовать малой задержки, стабильной работы, строгой сегментации и контролируемых окон обслуживания.
Подключение операционных сетей к корпоративным системам улучшает мониторинг и анализ данных, но также приносит киберриск. Доступ должен контролироваться через firewall, шлюзы, jump host, проверки личности и журналирование.
Команды IT и OT должны согласовать владельцев, процедуры обслуживания, аварийный доступ и управление изменениями. Изменение, безвредное в офисной сети, может повлиять на производство, если применить его неосторожно.
Стратегически использовать локальный выход
Локальный выход в Интернет позволяет филиалу обращаться к облаку и Интернету напрямую, а не отправлять весь трафик в головной офис. Это снижает задержку и улучшает опыт приложений.
Риск в том, что трафик филиала может обойти центральные средства безопасности. Чтобы избежать этого, локальный выход нужно сочетать с защищёнными веб-шлюзами, DNS-фильтрацией, защитой конечных точек, облачными сервисами безопасности и проверкой по политикам.
Не весь трафик должен выходить локально. Чувствительные внутренние приложения могут оставаться на частных путях, а SaaS и низкорисковый веб-трафик — использовать контролируемый локальный выход.
Согласовать сеть с непрерывностью бизнеса
План непрерывности бизнеса должен определить, какие сервисы должны выживать в разных сценариях отказа. Розничной точке может требоваться обработка платежей, больнице — клинический доступ и аварийная связь, заводу — мониторинг производства, складу — сканирование и логистика.
После определения критических функций сеть может предоставить нужный уровень резервирования и локальной живучести. Это могут быть локальные серверы, кэшированная аутентификация, резервный WAN, сотовый failover, локальная маршрутизация голоса или аварийные процедуры.
Непрерывность бизнеса нужно проверять реальными сценариями. Письменного плана недостаточно, если пользователи не знают, как действовать при сетевом сбое.
Управление и контроль изменений
Многоузловым средам нужна дисциплинированная governance. Быстрое изменение firewall на одной площадке может повлиять на доступ с другой. Новое облачное соединение может изменить маршрутизацию. Временный VPN может стать постоянным без проверки.
Контроль изменений должен включать причину запроса, затронутые площадки, уровень риска, план отката, метод тестирования, окно обслуживания, утверждение и обновление документации. Аварийные изменения следует анализировать после инцидента.
Governance не означает замедлять всё. Она делает изменения безопасными, отслеживаемыми и повторяемыми.
Оптимизация затрат
Полное использование распределённой архитектуры означает и контроль затрат. Некоторые организации переплачивают за полосу там, где трафик мал, и недоинвестируют в критические каналы. Другие сохраняют старые частные линии после изменения облачных сценариев.
Анализ затрат должен сравнивать бизнес-ценность, требования к производительности, уровень риска и необходимость резервирования. Дорогой канал оправдан для критической площадки, но может быть лишним для малого офиса с облачными приложениями.
Данные мониторинга помогают решениям. Реальное использование полосы, потеря пакетов, время отклика приложений и события failover дают лучшие доказательства, чем предположения.
Дорожная карта внедрения
Начните с обследования. Нанесите на карту площадки, каналы, устройства, приложения, пользователей, зоны безопасности, облачные сервисы и операционные зависимости. Найдите дублирующиеся системы, слабые каналы, неуправляемое оборудование и недокументированные потоки.
Затем определите целевую архитектуру. Решите, какие площадки нуждаются в резервировании, какой трафик должен идти частными путями, какие сервисы могут использовать локальный выход, как будет работать сегментация и как будут управляться политики.
После этого внедряйте поэтапно. Сначала стандартизируйте имена и адреса, улучшите мониторинг, разверните сегментацию безопасности, оптимизируйте облачный доступ, добавьте автоматизацию и проверьте устойчивость. Не меняйте все площадки сразу без сильной возможности отката.
Типичные ошибки
Одна ошибка — считать все площадки одинаковыми. У площадок разные риски, профили трафика и бизнес-значимость. Архитектура должна отражать эти различия.
Другая ошибка — сосредоточиться только на полосе. Большая полоса не исправляет ошибки маршрутизации, пробелы безопасности, плохой Wi-Fi, проблемы DNS, задержку приложений или нехватку видимости.
Третья ошибка — допускать неконтролируемый рост локальных исключений. Временные маршруты, неуправляемые коммутаторы, теневые Интернет-линии и неучтённые VPN создают долгосрочный риск.
Четвёртая ошибка — игнорировать пользовательский опыт. По статусу устройств сеть может выглядеть здоровой, а пользователи всё равно будут испытывать медленные приложения или плохое качество голоса.
Пятая ошибка — откладывать документацию. В распределённой среде недокументированный проект становится риском будущего сбоя.
Отраслевые тенденции
Распределённые сети движутся к облачно управляемому контролю, SD-WAN, SASE, zero trust, edge computing, мониторингу с помощью ИИ и более тесной интеграции сети и безопасности. Граница между WAN, облачным доступом, идентичностью и защитой от угроз становится менее отдельной.
Одновременно организации добавляют больше подключённых устройств и сервисов реального времени. Видео, голос, датчики, промышленная телеметрия и удалённые операции усиливают нагрузку на сетевой дизайн.
Наиболее успешное направление — не простое добавление инструментов. Это построение согласованной операционной модели, где связность, безопасность, мониторинг, автоматизация и бизнес-процессы поддерживают друг друга.
Многоузловая сеть полностью используется тогда, когда становится управляемой цифровой основой, соединяющей площадки, защищающей доступ, оптимизирующей приложения, поддерживающей устойчивость и дающей администраторам ясную видимость всей организации.
Частые вопросы
Почему разные филиалы имеют разное качество сети?
Каждый филиал может использовать разные каналы доступа, Wi-Fi-среды, маршруты, модели оборудования, расстояния до облака и локальные нагрузки. Мониторинг должен сравнивать условия по площадкам, а не предполагать одну общую причину.
Должен ли весь трафик возвращаться в головной офис?
Не всегда. Облачный и SaaS-трафик может работать лучше через контролируемый локальный выход, а чувствительный внутренний трафик может всё ещё требовать частной маршрутизации или центральной инспекции.
Как защитить малые площадки без сложного оборудования?
Используйте стандартизированные шаблоны, управляемые firewall, защищённые облачные шлюзы, защиту конечных точек, DNS-фильтрацию, строгую аутентификацию и централизованный мониторинг. Сложность должна соответствовать риску площадки.
Почему сегментация между площадками важна?
Сегментация ограничивает ненужный доступ между пользователями, устройствами, серверами, IoT-системами и операционными сетями. Она снижает влияние компрометации и улучшает контроль политик.
Что проверить перед добавлением нового филиала?
Проверьте потребности в полосе, доступ к приложениям, IP-адресацию, зоны безопасности, Wi-Fi-дизайн, требования резервирования, облачный доступ, интеграцию мониторинга, правила именования и ответственность поддержки.