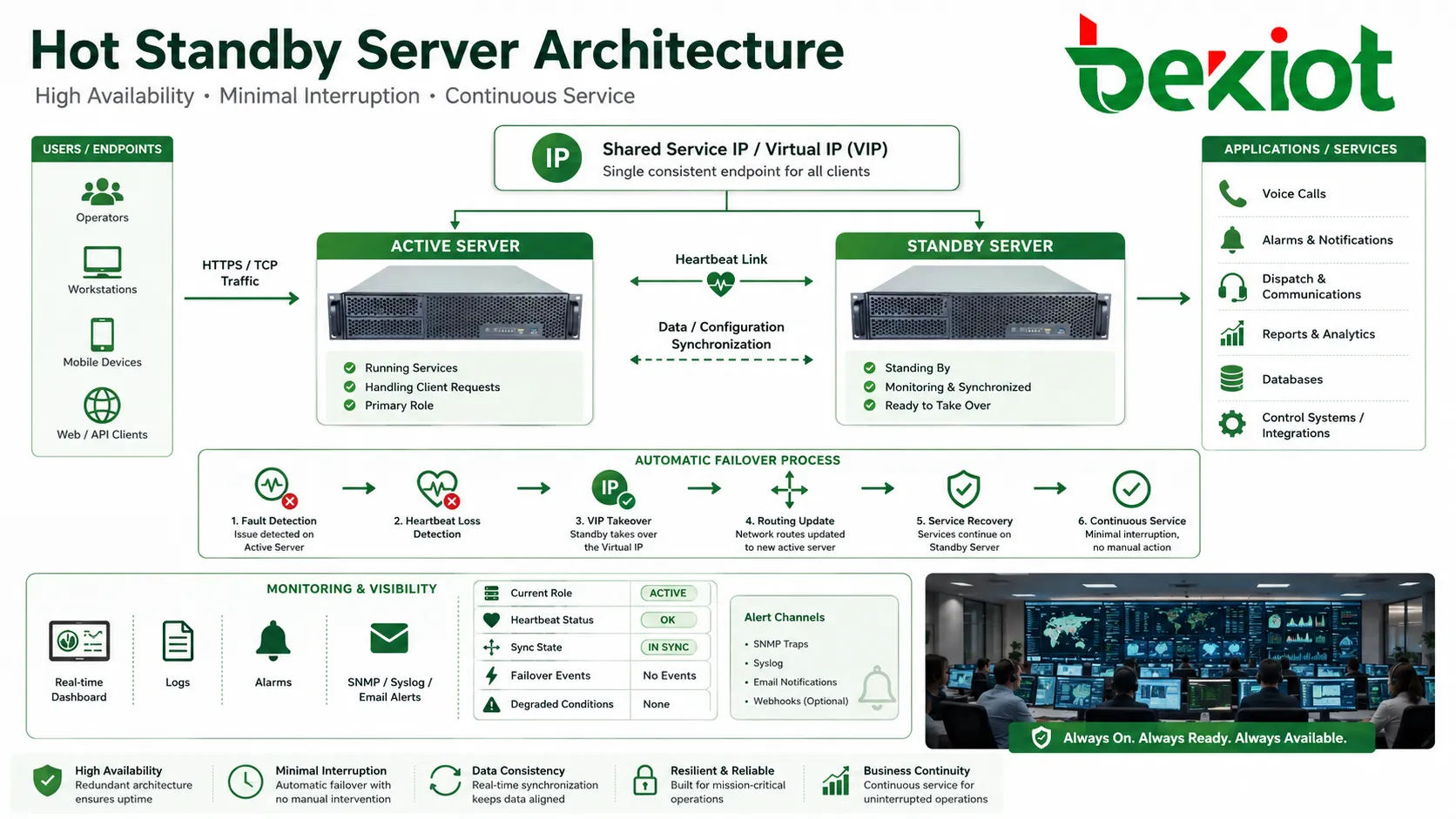
Горячий резерв — это схема высокой доступности, при которой резервное устройство, сервер, контроллер, шлюз или платформа остаются включенными, синхронизированными и готовыми принять работу при отказе активного узла. Вместо ручного ремонта или холодного запуска резервная сторона выполняет автоматический failover, сокращая простой и сохраняя непрерывность критических систем.
Эта функция применяется в коммуникационных платформах, дата-центрах, промышленном управлении, системах безопасности, энергетике, транспорте, облачных сервисах, телеком-шлюзах, аварийных системах и корпоративных приложениях. Ее ценность не в одной запасной машине, а в том, что резервный узел подключен, контролируется, синхронизирован и проверен для реального перехода.
От резервного устройства к проектированию непрерывности сервиса
Обычная резервная копия может не использоваться до момента аварии. Горячий резерв отличается тем, что резервный элемент уже входит в работающую архитектуру: принимает heartbeat, получает изменения конфигурации, отслеживает состояние сервиса и готовится к переходу с минимальным перерывом.
Для пользователя результат должен быть простым: звонки продолжаются, сессии восстанавливаются, аварии остаются видимыми, системы управления доступны, а операторам не нужно вручную заново строить сервис. За этим стоят синхронизация данных, захват IP, состояние служб, обновление маршрутов, обнаружение отказа и порядок восстановления.
В бизнесе и промышленности высокая доступность часто важнее максимальной производительности. Система, которая немного медленнее, но постоянно доступна, может быть ценнее мощной системы без защиты от отказа.
Как работает процесс перехода
Обнаружение по heartbeat
Активный и резервный узлы обычно обмениваются сигналами heartbeat. Они подтверждают, что обе стороны работают и что первичный узел по-прежнему обслуживает сервис. Такой трафик может идти по выделенному кабелю, сети управления, частному VLAN или резервному маршруту.
Если резервный узел перестает получать корректные heartbeat за заданное время, он может считать активный узел отказавшим. Затем запускается логика failover. Ее нужно проектировать осторожно, потому что слишком быстрая реакция на краткую задержку сети может вызвать ложный переход.
Синхронизация состояния
Для плавного перехода резервной стороне нужны актуальные сведения: конфигурации, пользовательские данные, таблицы маршрутизации, записи сессий, состояния звонков, тревоги, записи базы данных, лицензии, регистрации устройств и логика управления.
Одни системы синхронизируют только конфигурацию, другие — состояние сервиса в реальном времени. Чем глубже синхронизация, тем мягче failover, но тем выше сложность и зависимость от сети.
Решение об отказе
После обнаружения возможной аварии система должна решить, действительно ли активный узел недоступен. Для этого проверяются heartbeat, процессы, диск, интерфейсы, ответ базы данных, нагрузка CPU, питание или внешние сигналы мониторинга.
Хорошая архитектура не принимает решение по одному признаку. Например, потеря одного heartbeat-канала не должна автоматически запускать takeover, если другой путь управления показывает, что активный узел здоров.
Переключение ролей
Когда failover подтвержден, резервный узел меняет роль и становится активным. Он может принять виртуальный IP, запустить сервисы, объявить маршруты, зарегистрироваться у соседних систем, активировать транки, стать мастером базы данных и обрабатывать звонки или тревоги.
Бывший активный узел можно изолировать, перезагрузить, отремонтировать или позже вернуть как резервный. Его повторное присоединение должно контролироваться, чтобы не возник конфликт сервисов.
Ключевые архитектурные модели
Пара active-standby
Самая распространенная модель использует один активный и один резервный узел. Активный узел ведет продуктивный сервис, а резервный ожидает и синхронизируется; при отказе активной стороны он принимает работу.
Эта модель понятна и широко применяется в PBX, межсетевых экранах, маршрутизаторах, контроллерах, базах данных, системах хранения и промышленных платформах. Ее ограничение в том, что резервный ресурс в нормальном режиме может использоваться мало.
Два активных узла с резервной логикой
В некоторых средах оба узла работают активно, но между ними сохраняется логика отказоустойчивости. Каждый узел несет часть нагрузки, а при отказе одного другая сторона принимает больше трафика.
Такой подход лучше использует ресурсы, но требует более точного балансирования, синхронизации, обработки сессий и планирования емкости. Если оба узла почти полностью загружены, при отказе может не хватить резерва.
Кластерная избыточность
Крупные системы могут использовать кластер вместо простой пары. Несколько узлов совместно предоставляют сервисы, наблюдают друг за другом и перераспределяют нагрузку при отказе одного участника.
Кластеры дают лучшую масштабируемость и устойчивость, но сложнее в развертывании и обслуживании. Им нужны координация, quorum, проверки здоровья и единое управление конфигурацией.
Географически разнесенная защита
Некоторые критические системы размещают резервные ресурсы в другом здании, кампусе, дата-центре или регионе. Это защищает от локального отключения питания, пожара, затопления, отказа серверной или нарушения на уровне площадки.
Географическая защита улучшает аварийное восстановление, но создает вопросы задержки, согласованности данных, маршрутизации и операционного согласования. Не каждый сервис может плавно переключаться на большие расстояния.
| Модель | Лучшее применение | Главная проектная задача |
|---|---|---|
| Active-standby | Простые пары высокой доступности для серверов, шлюзов, PBX и контроллеров. | Использование резервного ресурса и момент failover. |
| Dual active | Системы, которым нужны распределение нагрузки и резервирование одновременно. | Резерв емкости, распределение сессий и управление failback. |
| Кластер | Крупные платформы с несколькими сервисными узлами и масштабируемой нагрузкой. | Quorum, синхронизация, предотвращение split-brain и сложность эксплуатации. |
| Удаленная защита | Аварийное восстановление и устойчивость уровня площадки. | Задержка, согласованность данных, маршрутизация и процедура восстановления. |
Сетевые элементы, определяющие надежность
Путь heartbeat
Heartbeat-канал должен быть надежным и желательно резервным. Если heartbeat идет по той же нестабильной сети, что и обычный сервисный трафик, резервный узел может неверно оценить состояние при перегрузке или отказе коммутатора.
В критических внедрениях часто используют два heartbeat-пути, отдельные физические линии или разные пути через коммутаторы. Это снижает риск ошибочного перехода из-за одного сетевого сбоя.
Виртуальный сервисный адрес
Многие системы используют виртуальный IP или плавающий сервисный адрес. Пользователи и соседние системы подключаются к стабильному адресу, а не к физическому адресу конкретного узла; при failover адрес переходит на резервную сторону.
Такой метод упрощает настройку клиентов, но сетевое оборудование должно быстро обновить ARP, маршруты, DNS или таблицы сессий. Медленное обновление адреса делает failover видимым как задержку, даже если резервный узел уже активен.
Общие или реплицированные данные
Одни системы используют общее хранилище, другие реплицируют данные между узлами. Общее хранилище упрощает консистентность, но без защиты может стать единой точкой отказа. Репликация повышает независимость, но требует учета задержек, конфликтов и незавершенных записей.
Выбор метода зависит от того, нужна ли системе непрерывность конфигурации, транзакционная согласованность, целостность записей, сохранение сессий или простой перезапуск службы.
Поведение маршрутов и транков
Коммуникационные системы могут быть связаны с SIP-транками, радио- и PSTN-шлюзами, диспетчерскими консолями, внешними API, платформами мониторинга и удаленными терминалами. Эти внешние системы должны знать, куда отправлять трафик после failover.
Если резервный узел стал активным, но транки, маршруты или регистрации соседних систем не обновились, пользователи все равно почувствуют перерыв. Поэтому тесты должны включать не только два локальных узла, но и upstream/downstream-системы.
Уровень управления и мониторинга
Высокая доступность должна быть видна администраторам. Панели, журналы, тревоги, SNMP traps, syslog, email-уведомления и мониторинг должны показывать роль, heartbeat, синхронизацию, события failover и деградированные состояния.
Без мониторинга система может неделями незаметно работать на резервной стороне. Если затем произойдет еще один отказ, защиты может уже не остаться.
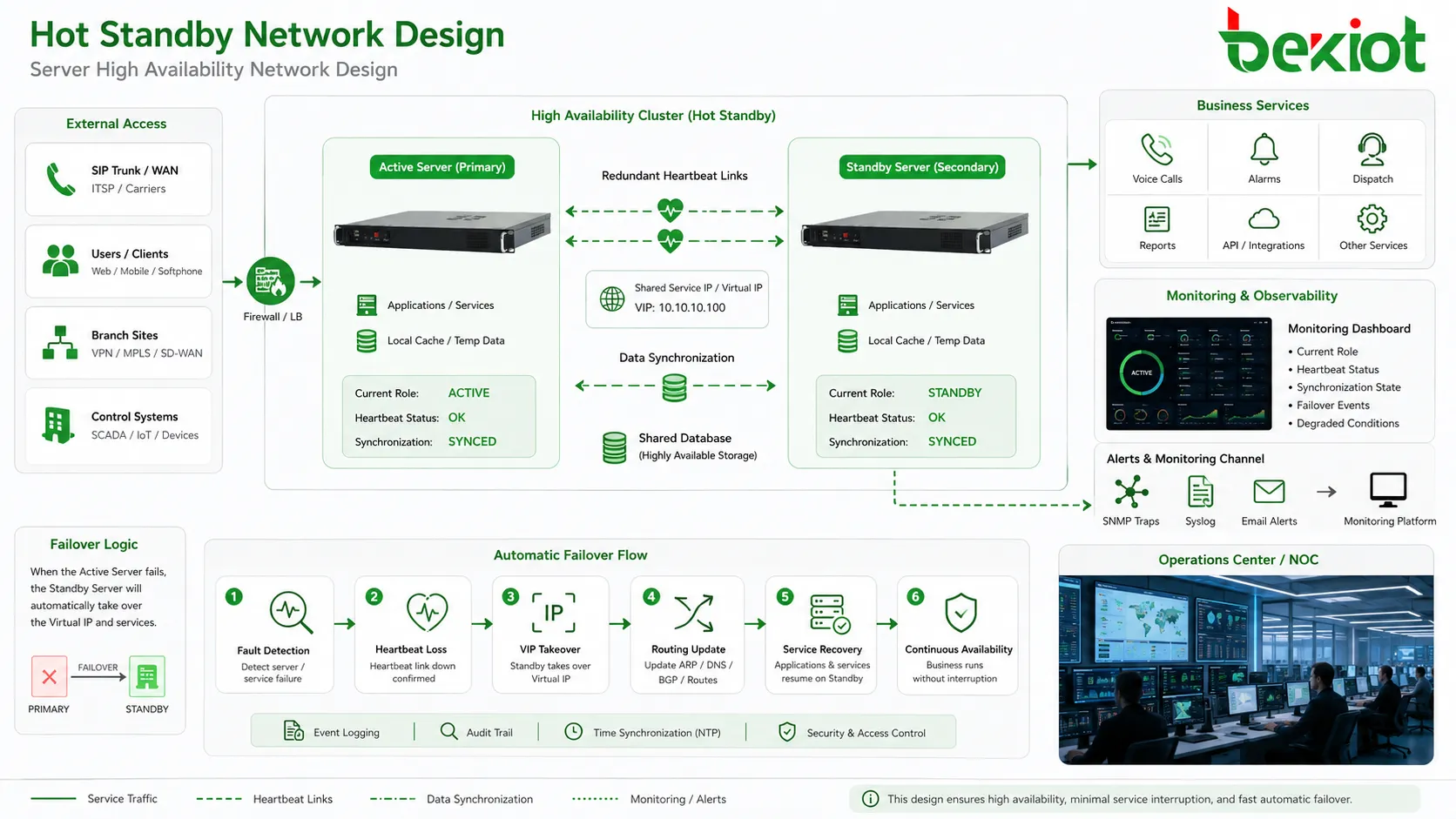
Важные технические функции
Автоматический failover
Автоматический failover позволяет резервной стороне стать активной без ручного вмешательства. Это важно для связи в реальном времени, тревог безопасности, операций управления и сервисов для клиентов.
Порог failover нужно настраивать аккуратно. Слишком чувствительный порог вызывает ложные переходы, а слишком медленный увеличивает ненужный простой для пользователей.
Ручное переключение
Ручное переключение позволяет администраторам переносить сервис с одного узла на другой при обслуживании, обновлении, тестировании или плановом ремонте. Это полезно при замене оборудования, установке патчей и проверке готовности standby.
Контролируемое переключение безопаснее ожидания внезапного отказа, потому что команда может запланировать действие, следить за результатом и откатиться при необходимости.
Управление failback
После ремонта исходного активного узла система должна решить, возвращать ли сервис автоматически или оставить его на текущем узле до планового окна. Автоматический failback быстро восстанавливает исходную схему, но может вызвать еще один перерыв.
Многие критические системы предпочитают ручной failback, чтобы операторы проверили здоровье, синхронизацию и трафик перед повторным переносом сервиса.
Предотвращение split-brain
Split-brain возникает, когда оба узла считают себя активными одновременно. Это приводит к дублированию сервисов, конфликтам базы данных, ошибкам маршрутизации вызовов, конфликтам IP и повреждению данных.
Для предотвращения применяют quorum, witness-узлы, fencing, правила приоритета, резервные heartbeat-каналы и строгий контроль ролей. Защита от split-brain является одной из ключевых частей высокой доступности.
Защита целостности данных
Во время failover система должна защищать конфигурационные и операционные данные: транзакции базы, записи вызовов, журналы тревог, состояния регистраций устройств, аудиозаписи и историю событий.
Целостность данных особенно важна, если система используется для соответствия требованиям, биллинга, аварийных записей, диспетчерских журналов или аудита.
Где применяется эта схема
Платформы корпоративной связи
PBX-серверы, SIP-платформы, голосовая почта, серверы записи, контакт-центры и UC-платформы могут использовать standby-защиту для сохранения деловой связи. При отказе активного сервера резервная сторона продолжает регистрации, вызовы, маршруты и сервисную логику.
В проектах критической связи Becke Telcom применяет принципы высокой доступности при планировании коммуникационных систем, помогая учитывать серверную избыточность, непрерывность шлюзов, доступность диспетчеризации и маршруты failover.
Промышленное управление и SCADA
Промышленные системы часто используют резервные контроллеры, дублированные SCADA-серверы, двойные коммуникационные шлюзы и резервные операторские станции. Они поддерживают производство, безопасность, энергетику, коммунальную инфраструктуру и мониторинг процессов.
Failover нужно испытывать в реальных технологических условиях. Система управления, корректно переключающаяся в лаборатории, может вести себя иначе с полевыми устройствами, PLC, historian-системами, тревогами и операторскими консолями.
Системы безопасности и видеонаблюдения
Серверы видеоменеджмента, контроль доступа, серверы тревог, узлы хранения и системы диспетчерских могут нуждаться в standby-защите, чтобы избежать слепых зон и задержек реакции безопасности.
В таких средах failover должен учитывать живое видео, непрерывность записи, управление дверями, подтверждение тревог, журналы событий и права операторов.
Дата-центры и облачные сервисы
Серверы, базы данных, firewall, балансировщики, системы хранения, маршрутизаторы и приложения часто используют высокодоступную архитектуру. Standby-защита может находиться на уровне оборудования, виртуализации, контейнера, базы данных или приложения.
Чем больше уровней участвует, тем важнее определить, какой уровень отвечает за failover. Несколько независимых механизмов могут конфликтовать без общего плана.

Общественная безопасность и транспорт
Центры экстренного реагирования, железные дороги, тоннельные диспетчерские, аэропорты, портовые центры и платформы управления движением требуют высокой доступности. Отказ связи задерживает реакцию, снижает ситуационную осведомленность и нарушает координацию.
В таких системах резервирование должно охватывать не только серверы, но и питание, коммутаторы, транки, терминалы, рабочие места операторов и внешние интерфейсы.
Преимущества внедрения помимо сокращения простоя
Главная выгода — непрерывность сервиса. При отказе первичного узла пользователи продолжают работать с меньшим перерывом, что важно для голоса, тревог, мониторинга, доступа к данным и функций управления.
Еще одно преимущество — гибкость планового обслуживания. Администраторы могут перенести сервис на standby, обслужить исходный узел и вернуть роль после проверки, сокращая длительные окна простоя.
Standby-дизайн повышает уверенность при обновлениях. Если обновление вызывает проблему на одной стороне, организация может иметь контролируемый путь восстановления, если архитектура и rollback-план подготовлены.
Для руководства высокая доступность снижает риск: отказ одного устройства превращается не в полный простой, а в управляемое событие, которое можно исследовать и устранить с меньшим ущербом бизнесу.
Практические сценарии отказов
Аппаратный отказ
Может отказать сервер, блок питания, диск, интерфейсная карта, шлюз или контроллер. Резервный узел должен определить, что активный сервис больше не здоров, и принять работу по заданной политике.
Аппаратный отказ легче всего понять, но он не всегда является самой частой причиной прерывания сервиса.
Сбой процесса приложения
Машина может оставаться включенной, а сервисное приложение перестать отвечать. Хорошая проверка здоровья должна видеть не только жив ли сервер, но и работает ли сама служба.
Одного ping обычно недостаточно. Система может отвечать на ping, когда call engine, база данных, процесс тревог или веб-служба уже отказали.
Сетевая изоляция
Узел может быть изолирован от пользователей, но продолжать считать себя здоровым. Это опасно, потому что система может не понимать, какая сторона должна быть активной.
Резервные сетевые пути и логика quorum помогают избежать ошибочных решений при событиях изоляции.
Повреждение базы данных
Если данные повреждаются на активной стороне и сразу реплицируются на standby, одна избыточность проблему не решит. Нужны backup и восстановление по версиям.
Высокая доступность не равна резервному копированию. Standby защищает непрерывность сервиса, а backup — историческое восстановление данных.
Ошибка оператора
Неверная конфигурация, случайное удаление, неправильный маршрут или неудачное обновление могут затронуть оба узла, если конфигурация синхронизируется автоматически.
Change control, согласование изменений, экспорт конфигурации и планы rollback необходимы для снижения влияния человеческих ошибок.
Высокая доступность сокращает простой от отказов компонентов, но не заменяет backup, кибербезопасность, контроль изменений, мониторинг и дисциплинированное обслуживание.
Стратегия тестирования и приемки
Failover нужно проверять до ввода в эксплуатацию. Тест должен подтвердить, что standby обнаруживает отказ, принимает сервис, обновляет сетевые пути, восстанавливает внешние соединения, сохраняет нужные данные и формирует правильные тревоги.
Тесты должны включать плановое переключение, выключение активного узла, отказ сервисного процесса, сбой сетевой линии, безопасное отключение питания и восстановление после ремонта. Для каждого теста задаются ожидаемое поведение и допустимый перерыв.
Приемочные записи должны включать время failover, результат согласованности данных, доступность сервиса, тревоги, логи, подтверждение оператора и нерешенные вопросы. Без записей система может казаться резервной, но оставаться недоказанной.
Рекомендации по эксплуатации и обслуживанию
Состояние standby нужно контролировать постоянно. Резервный узел, который включен, но не синхронизирован, не готов. Администраторы должны смотреть heartbeat, задержку репликации, ресурсы, статус служб, лицензии, емкость хранения и версии ПО.
Обе стороны нужно обновлять осторожно. Разные версии могут сорвать failover или вызвать неожиданное поведение; обновления следует выполнять поэтапно и тестировать, чтобы ошибка не сломала оба узла сразу.
Периодически проводите упражнения переключения. Система, ни разу не проверенная в контролируемых условиях, может не сработать при реальной аварии, а тренировки помогают операторам понимать процедуру и время реакции.
После каждого failover нужно анализировать журналы. Даже если сервис выглядит нормальным, причина должна быть найдена; повторные события могут указывать на нестабильность сети, перегрузку, деградацию оборудования или плохие пороги health check.
FAQ
Горячий резерв — это то же самое, что резервная копия?
Нет. Узел standby нужен для непрерывности сервиса, а backup — для восстановления данных. Обычно нужны оба механизма, потому что failover не возвращает старые версии поврежденных или удаленных данных.
Насколько быстро должен происходить failover?
Допустимое время зависит от приложения. Голос, управление, тревоги и системы общественной безопасности обычно требуют более быстрого восстановления, чем обычные отчеты или архивы.
Защищает ли резервная система от программных ошибок?
Только иногда. Если один и тот же программный дефект есть на обоих узлах, failover не решит проблему. Контроль версий, тестирование, rollback и backup остаются важными.
Что вызывает split-brain?
Split-brain часто вызывается потерей heartbeat, сетевой изоляцией, слабым quorum или неверными правилами failover. Он возникает, когда больше одного узла считает, что должен быть активным.
Что проверять после failover?
После failover проверьте активную роль, здоровье standby, синхронизацию, сервисные логи, влияние на пользователей, целостность данных, внешние транки или интерфейсы, записи тревог и первопричину перехода.